buddy system
Buddy System 简介
Buddy System 是一种内存分配算法,主要用于操作系统内核的内存管理。它将内存分成大小为2的幂次方的块,并通过合并和分割这些块来满足内存分配和释放的需求。
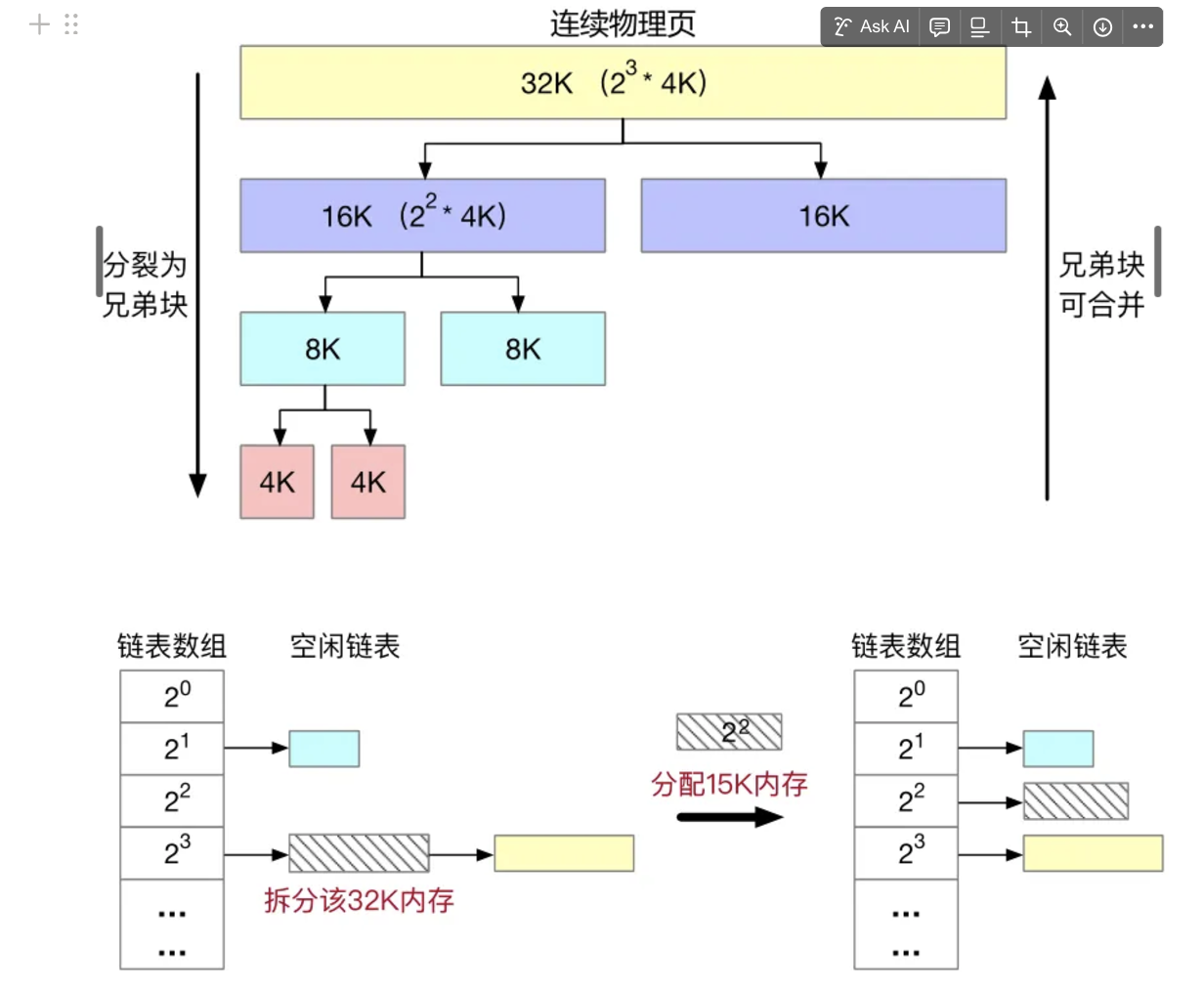
工作原理
-
初始化:内存被分成大小为2的幂次方的块。
-
分配:当需要分配内存时,找到最小的足够大的块。如果该块太大,则将其分割成两个“伙伴”块,直到块的大小合适。
-
释放:释放内存时,检查其“伙伴”是否也空闲。如果是,则合并这两个块,形成一个更大的块,继续检查并合并,直到不能再合并为止。
-
源码解析:
内存排布图 ref: https://www.cnblogs.com/kangyupl/p/chcore_lab2.html
┌─────────────┐◄─ page_end (metadata_end + (npages * PAGE_SIZE))
│ │
│ pages │
│ │
├─────────────┤◄─ metadata_end (img_end + (npages * sizeof(struct page))
│page metadata│
│ │
├─────────────┤◄─ metadata_start (img_end)
│ KERNEL IMG │
├─────────────┤◄─ init_end
│ bootloader │
├─────────────┤◄─ 0x00080000 (img_start, init_start)
│ reserved │
└─────────────┘◄─ 0x00000000
内部设计:
get_buddy_chunk
涉及的几个函数命名都怪怪的
struct page & page 指 metadata段的page info结构体, 记录alloc, pool等信息,也作为freelist链表节点
virt 实际的地址和分配的数据段, 猜测叫 virt 是因为前面的direct mapping?
Lab1之中,内核段
vaddr对应的物理地址是vaddr - KERNEL_VADDR,用户地址空间va = pa
而因此,在后面完成页表的初始化和分配之后,我们需要根据这个新的页表来建立新的映射
由于page指针指向的是meta data的地址段,下面两个函数实际意思是 meta data 和 actual page的转换
void *page_to_virt(struct page *page)
{
vaddr_t addr;
struct phys_mem_pool *pool = page->pool;
BUG_ON(pool == NULL);
/* page_idx * BUDDY_PAGE_SIZE + start_addr */
addr = (page - pool->page_metadata) * BUDDY_PAGE_SIZE
+ pool->pool_start_addr;
return (void *)addr;
}
struct page *virt_to_page(void *ptr)
{
struct page *page;
struct phys_mem_pool *pool = NULL;
vaddr_t addr = (vaddr_t)ptr;
int i;
/* Find the corresponding physical memory pool. */
for (i = 0; i < physmem_map_num; ++i) {
if (addr >= global_mem[i].pool_start_addr
&& addr < global_mem[i].pool_start_addr
+ global_mem[i].pool_mem_size) {
pool = &global_mem[i];
break;
}
}
if (pool == NULL) {
kdebug("invalid pool in %s", __func__);
return NULL;
}
page = pool->page_metadata
+ (((vaddr_t)addr - pool->pool_start_addr) / BUDDY_PAGE_SIZE);
return page;
}
明白了这个之后get_buddy_chunk就简单了,从传入的page metadata pointer得到实际的page地址,再通过一个异或操作得到某个order上的buddy page, 最后返回这个buddy page的metadata pointer
static struct page *get_buddy_chunk(struct phys_mem_pool *pool,
struct page *chunk)
{
vaddr_t chunk_addr;
vaddr_t buddy_chunk_addr;
int order;
/* Get the address of the chunk. */
chunk_addr = (vaddr_t)page_to_virt(chunk);
order = chunk->order;
/*
* Calculate the address of the buddy chunk according to the address
* relationship between buddies.
*/
buddy_chunk_addr = chunk_addr
^ (1UL << (order + BUDDY_PAGE_SIZE_ORDER));
/* Check whether the buddy_chunk_addr belongs to pool. */
if ((buddy_chunk_addr < pool->pool_start_addr)
|| ((buddy_chunk_addr + (1 << order) * BUDDY_PAGE_SIZE)
> (pool->pool_start_addr + pool->pool_mem_size))) {
return NULL;
}
return virt_to_page((void *)buddy_chunk_addr);
}
split_chunk
比较有趣的是它的api设计,传入的order是表示最后需要“得到”这个order的chunk,如��果得不到就递归分裂,并把中间分裂出来的空块放入对应order的free_list
static struct page *split_chunk(struct phys_mem_pool *pool, int order,
struct page *chunk)
{
struct page *buddy_chunk;
struct list_head *free_list;
/*
* If the @chunk's order equals to the required order,
* return this chunk.
*/
if (chunk->order == order)
return chunk;
/*
* If the current order is larger than the required order,
* split the memory chunck into two halves.
*/
chunk->order -= 1;
buddy_chunk = get_buddy_chunk(pool, chunk);
/* The buddy_chunk must exist since we are spliting a large chunk. */
if (buddy_chunk == NULL) {
BUG("buddy_chunk must exist");
return NULL;
}
/* Set the metadata of the remaining buddy_chunk. */
buddy_chunk->order = chunk->order;
buddy_chunk->allocated = 0;
/* Put the remaining buddy_chunk into its correspondint free list. */
free_list = &(pool->free_lists[buddy_chunk->order].free_list);
list_add(&buddy_chunk->node, free_list);
pool->free_lists[buddy_chunk->order].nr_free += 1;
/* Continue to split current chunk (@chunk). */
return split_chunk(pool, order, chunk);
}
merge_chunk
同理,找到buddy chunk, 之后查看他
- 是否空闲
- 是否同阶
如果是就合并,并从free_list之中删了它
但这个删除比较有意思,是一个O(1)的删除,这就体现meta data段的威力了,从page meta→ page data → buddy data→buddy meta→buddy node pointer, 之后就是双向链表的操作
详细来说
- page meta → page data:
page_to_virt - page_data → buddy data: xor,
get_buddy_chunk - buddy_data → buddy meta:
virt_to_page - meta → alloc信息更新,free list更新等
list_del(&(buddy_chunk->node));
static inline void list_del(struct list_head *node)
{
node->prev->next = node->next;
node->next->prev = node->prev;
}
init_buddy
初始化物理内存池的几个属性
- 初始化free_list
- 清理并初始化meta_data area
- 通过free把物理内存页放到free_list之中
void init_buddy(struct phys_mem_pool *pool, struct page *start_page,
vaddr_t start_addr, unsigned long page_num)
{
int order;
int page_idx;
struct page *page;
BUG_ON(lock_init(&pool->buddy_lock) != 0);
/* Init the physical memory pool. */
pool->pool_start_addr = start_addr;
pool->page_metadata = start_page;
pool->pool_mem_size = page_num * BUDDY_PAGE_SIZE;
/* This field is for unit test only. */
pool->pool_phys_page_num = page_num;
/* Init the free lists */
for (order = 0; order < BUDDY_MAX_ORDER; ++order) {
pool->free_lists[order].nr_free = 0;
init_list_head(&(pool->free_lists[order].free_list));
}
/* Clear the page_metadata area. */
memset((char *)start_page, 0, page_num * sizeof(struct page));
/* Init the page_metadata area. */
for (page_idx = 0; page_idx < page_num; ++page_idx) {
page = start_page + page_idx;
page->allocated = 1;
page->order = 0;
page->pool = pool;
}
/* Put each physical memory page into the free lists. */
for (page_idx = 0; page_idx < page_num; ++page_idx) {
page = start_page + page_idx;
buddy_free_pages(pool, page);
}
}
外部接口:
buddy_get_pages
有了上面的辅助函数之后,这个函数的思路就很清晰了
- 拿锁
- 找到一个足够大且free的chunk(实际上order从小到大看free list的第一个元素就行)
- 如果这个chunk比需要的大,split_chunk之后返回给调用者
代码如下,��中间比较hack的就是这个从free_list得到第一个元素的page metadata的操作
注意free_list之中为了加速存储的不是page metadata的指针page,而是直接指向实际data内存地址的指针node
而从node获取page就用了下面的list_entry宏这样一个小小的hack, 具体解析见下文,为了节省这一次的指针跳跃真是拼啊
/* Search a chunk (with just enough size) in the free lists. */
for (cur_order = order; cur_order < BUDDY_MAX_ORDER; ++cur_order) {
free_list = &(pool->free_lists[cur_order].free_list);
if (!list_empty(free_list)) {
/* Get a free memory chunck from the free list */
page = list_entry(free_list->next, struct page, node);
list_del(&page->node);
pool->free_lists[cur_order].nr_free -= 1;
page->allocated = 1;
break;
}
}
buddy_free_pages
同理,拿锁,修改meta data的属性,merge之后,在freelist里面添加,
void buddy_free_pages(struct phys_mem_pool *pool, struct page *page)
{
int order;
struct list_head *free_list;
lock(&pool->buddy_lock);
BUG_ON(page->allocated == 0);
/* Mark the chunk @page as free. */
page->allocated = 0;
/* Merge the freed chunk. */
page = merge_chunk(pool, page);
/* Put the merged chunk into the its corresponding free list. */
order = page->order;
free_list = &(pool->free_lists[order].free_list);
list_add(&page->node, free_list);
pool->free_lists[order].nr_free += 1;
unlock(&pool->buddy_lock);
}
并发安全性: 在init时初始化锁,仅在外部接口get,free时拿大锁, 简单的并发安全性保证
数据结构设计: physmem_map, page, free_list, phys_mem_pool, page_metadata
经典Liunx宏
#define container_of(ptr, type, field) \
((type *)((void *)(ptr) - (void *)(&(((type *)(0))->field))))
#define list_entry(ptr, type, field) \
container_of(ptr, type, field)
(((type *)(0))->field) 得到了field的offset, 将null强制转换成 type 的指针后->field 就的地址就会是offset,从而可以让ptr - offset得到原始的地址
这其实被誉为是“Linux第一宏”,依赖于结构体的变量在内存地址之中是大于结构体的地址(向上增长),而gnu manual的原文其实是 https://www.gnu.org/software/c-intro-and-ref/manual/html_node/Structure-Layout.html
The precise layout of a
structtype is crucial when using it to overlay hardware registers, to access data structures in shared memory, or to assemble and disassemble packets for network communication. It is also important for avoiding memory waste when the program makes many objects of that type. However, the layout depends on the target platform. Each platform has conventions for structure layout, which compilers need to follow.
Here are the conventions used on most platforms.
The structure’s fields appear in the structure layout in the order they are declared. When possible, consecutive fields occupy consecutive bytes within the structure. However, if a field’s type demands more alignment than it would get that way, C gives it the alignment it requires by leaving a gap after the previous field.
Once all the fields have been laid out, it is possible to determine the structure’s alignment and size. The structure’s alignment is the maximum alignment of any of the fields in it. Then the structure’s size is rounded up to a multiple of its alignment. That may require leaving a gap at the end of the structure.
只说了“按照声明顺序在内存布局”,微妙地没有指定方向(实际上在“标准c/cpp”之中,这个宏是个UB)
也就是有很微妙的点在于,假如这个结构体是在栈上的,且栈向下增长(注意c标准甚至没有“堆”和“栈”!),那么栈上的结构体的元素排布也需要保持这个向上的顺序,可以举个例子
#include <iostream>
#include <string>
using namespace std;
#define container_of(ptr, type, field) \
((type *)((char *)(ptr) - (char *)(&(((type *)(0))->field))))
struct A {
int x;
int y;
};
void print_A(A *a, bool is_stack) {
string type = is_stack ? "Stack" : "Heap";
cout << type << "A: " << a->x << ", " << a->y << endl;
};
int main() {
A stackA = {1, 2};
A *heapA = new A{3, 4};
A stackA2 = {5, 6};
A *heapA2 = new A{7, 8};
int *stack_y_ptr = &stackA.y;
int *heap_y_ptr = &heapA->y;
cout << "stackA: " << &stackA << ", address of y: " << stack_y_ptr << endl;
cout << "stackA2: " << &stackA2 << ", address of y: " << &stackA2.y << endl;
cout << "heapA: " << heapA << ", address of y: " << &heapA->y << endl;
cout << "heapA2: " << heapA2 << ", address of y: " << &heapA2->y << endl;
A *stack_A_ptr = container_of(stack_y_ptr, struct A, y);
A *heap_A_ptr = container_of(heap_y_ptr, struct A, y);
print_A(stack_A_ptr, true);
print_A(heap_A_ptr, false);
delete heapA;
return 0;
}
得到结果
stackA: 0x7ffe77f0b6c4, address of y: 0x7ffe77f0b6c8 // addr y > addr stackA
stackA2: 0x7ffe77f0b6b0, address of y: 0x7ffe77f0b6b4 // addr A in stack high to low
heapA: 0x5593be7242b0, address of y: 0x5593be7242b4 // addr y > addr heapA
heapA2: 0x5593be7242d0, address of y: 0x5593be7242d4 //addr A in heap low to high
StackA: 1, 2
HeapA: 3, 4
作用为从一个结构体成员的指针得到结构体容器(wrapper)的指针
从而达成类似反射的效果
在buddy_get_pages里面有一个很好的实例
/* Search a chunk (with just enough size) in the free lists. */
for (cur_order = order; cur_order < BUDDY_MAX_ORDER; ++cur_order) {
free_list = &(pool->free_lists[cur_order].free_list);
if (!list_empty(free_list)) {
/* Get a free memory chunck from the free list */
page = list_entry(free_list->next, struct page, node);
list_del(&page->node);
pool->free_lists[cur_order].nr_free -= 1;
page->allocated = 1;
break;
}
}
在chcore中更重要的是解决了free_list和page的嵌套关系
思考: 假设没有这个宏魔法,应该怎么设计struct page(page metadata)和struct free_list的包含结构?
/*
* The layout of each physmem:
* | metadata (npages * sizeof(struct page)) | start_vaddr ... (npages *
* PAGE_SIZE) |
*/
static void init_buddy_for_one_physmem_map(int physmem_map_idx)
{
paddr_t free_mem_start = 0;
paddr_t free_mem_end = 0;
struct page *page_meta_start = NULL;
unsigned long npages = 0;
unsigned long npages1 = 0;
paddr_t free_page_start = 0;
free_mem_start = physmem_map[physmem_map_idx][0];
free_mem_end = physmem_map[physmem_map_idx][1];
kdebug("mem pool %d, free_mem_start: 0x%lx, free_mem_end: 0x%lx\n",
physmem_map_idx,
free_mem_start,
free_mem_end);
#ifdef KSTACK_BASE
/* KSTACK_BASE should not locate in free_mem_start ~ free_mem_end */
BUG_ON(KSTACK_BASE >= phys_to_virt(free_mem_start) && KSTACK_BASE < phys_to_virt(free_mem_end));
#endif
npages = (free_mem_end - free_mem_start)
/ (PAGE_SIZE + sizeof(struct page));
free_page_start = ROUND_UP(
free_mem_start + npages * sizeof(struct page), PAGE_SIZE);
/* Recalculate npages after alignment. */
npages1 = (free_mem_end - free_page_start) / PAGE_SIZE;
npages = npages < npages1 ? npages : npages1;
page_meta_start = (struct page *)phys_to_virt(free_mem_start);
kdebug("page_meta_start: 0x%lx, npages: 0x%lx, meta_size: 0x%lx, free_page_start: 0x%lx\n",
page_meta_start,
npages,
sizeof(struct page),
free_page_start);
/* Initialize the buddy allocator based on this free memory region. */
init_buddy(&global_mem[physmem_map_idx],
page_meta_start,
phys_to_virt(free_page_start),
npages);
}
从这个mm_init就可以看到整一个的流程
首先是在全局变量的global_mem和physmem_map, 这部分会根据硬件来划分几段可以分配的物理地址段,并保留其起始地址和结束地址,树莓派是三段所以是
paddr_t physmem_map[N_PHYS_MEM_POOLS][2]; // N_PHYS_MEM_POOLS = 3
之后chcore为每一段空间初始化一个buddy allocator,即
static void init_buddy_for_one_physmem_map(int physmem_map_idx)
在这里根据
/*
* The layout of each physmem:
* | metadata (npages * sizeof(struct page)) | start_vaddr ... (npages *
* PAGE_SIZE) |
*/
这样的layout 计算出meta data的开头和结尾,实际分配段的start_vaddr和长度,和文件系统之中的meta data + block data是类似的逻辑
之后对每一段的初始化逻辑都是:
- 初始化meta段数据
- phys_mem_pool的start_vaddr和page_metadata(metadata起始地址), page_num
- 对每一个page设置allocate位,0 order 和保留pool的指针
- 进行buddy sys的合并
- 需要注意的是这里并没有假定每一段的长度是2^N这样, 所以并不是直接得到一个大块,而是迭代每一个page进行merge,带来了更多的灵活性,使得buddy sys也支持像是1.5G或者 2G - 10M(例如10M是预留数据)这样的空间,提高了灵活性
- merge之后,将得到的chunk放到对应order的free_list之中