质量与多样性的兼得之策
引言
最近做 post-training 筛数据时反复遇到一个需求: 想从一个大池子里挑一个小子集, 既要分高, 又要在某些维度上分散, 比如 repo、tag、语言、时间。
本篇博客主要介绍一下我的思路, 其实把这个看成一个前AI时代的组合优化问题, 想要得到一个优解并没有那么难。数据的多样性不应该是一个"先采样什么什么, 看看分布, 再升降采样"这样的"人类启发式优化", 而是能够给出优性证明的稳定可复现流程。
基于一些数据之类的敏感性, 这个工具不会开源, 让你的Claude Code看完自己复现一个(doge
多样性需求
先说几个的场景, 直观感受一下"质量 + 多样性"到底在说什么:
- PR 池筛 SFT 数据: 1000 万 PR 里挑 1 万, 每条都打过质量分。直接 top-k 的结果是名额大头来自前几个仓库 — 模型只学会"那几个仓库的风格", 对其他仓库基本不泛化
- 多语言代码 SFT: 想要 Python / TypeScript / Go / Rust 比例大致均衡。某些语言的样本质量分普遍高, 直接按分排会几乎全是 Python
- 难度 benchmark 抽样: 简单/中等/困难三档各占 30%, 但模型在中等档输出更长更整齐, 质量分会更高, 直接选会偏到中等
- 去重 + 高分: 选 top-k 之后发现里面有一对 embedding 几乎重合; 或者同一 repo 三天内的两条PR 改了同一个文件
- 覆盖长尾: 数据集有 200 个 task tag, 不希望某些 tag 一条都不选
这些场景的共同特征: 每条数据本身有个分, 但不能只看分。某种"结构"�在里面 — 同 repo / 同 tag / 同时间窗 / 同语义簇 — 决定了我们要让候选在这个结构上散开。
把需求抽象一下
把上面这些场景翻译成数学, 我发现它们能整理成三类偏好:
1. 一元偏好 — 单条数据本身的加减分 "带 testing tag 的多加 0.3 分"、"质量分本身"、"主动学习里的不确定度奖励" — 这些都是 per-item 一个 delta, 跟其他条无关。
2. 多元对称偏好 — 同组数量的某种函数 "同 repo 不要太多"、"长尾 tag 至少保 3 条"、"label 比例 4:3:3" — 都是先按某个 key 分组, 然后对每组的"被选中数量"算一个罚或奖。关键在对称: 在同一组里, 哪几条被选中并不重要, 只看选了几条。这个对称性是它能写得简洁的根本原因 — 条数据展开成两两关系是 项, 但因为对称, 折叠成"每组的数量函数"就只跟组数有关。
3. 二元偏好 — 两条之间的关系 "embedding 余弦 > 0.9 的两条不要一起选"、"同 repo 3 天内的两条互斥"、"n-gram 重叠太大互斥" — 这些是真两两的关系, 没办法折叠成"组数量"。
第一类几乎零成本, 直接加进基础分。麻烦的是第二、三类 — 它们都是 上的非线性 / 高阶项, 不做妥协的话求解会爆炸。
设计选择: 哪里做妥协, 为什么是合理的
第一类一元偏好几乎零成本, 直接累加进基础分就行。麻烦的是第二、三类 — 它们都是 上的非线性 / 高阶项, 不做妥协的话求解会爆炸。和 Claude Code 脑暴一番后, 我做了三个非平凡的限制。这些限制让算法可解, 同时我认为它们恰好踩中了业务需求的结构。
限制 1: 二元偏好只支持稀疏图
二元偏好理论上是 的矩阵。如果稠密, , 不管什么算法都跑不动 ( 时矩阵都装不下)。我的限制是 — 平均每条最多跟常数条相关。
业务上其实非常合理: 实际场景里"哪两条要互斥"几乎都来自一些稀疏化的关系 — embedding 的 kNN (每条只跟最近 K 条相关), 时间窗 (每条只跟前后几天相关), LSH bucket (每条只跟同 bucket 的几条相关)。"全 N*N 矩阵"这种在工程上本来也算不出来。
好处: 稀疏二元可以按连通分量切开, 每个分量独立求解 — 用并查集把禁忌图分成若干组, 组与组之间没有耦合。 时大部分分量就一个点, 这一档是 的; 真正费力的只有少数大分量 (典型 ), 用分支定界或小型 LP 处理。
限制 2: 多元偏好只支持组数量的对称函数
多元偏好理论上是 上的一般 set function 。这种太一般, 求解需要枚举所有子集。我的限制是只支持"按 key 分组, 对每组数量算一个标量函数"。
业务上借用了上面"对称性"的观察: 大部分多元需求 ("repo 散开" / "tag 比例" / "长尾覆盖") 在同一组内对哪几条被选中是无差别的。把这种对称结构显式地表达出来, 求解就从 量级降到 量级。
限制 3: 组数量函数限制成凹
"组里选越多越亏"的形状有很多种 — 凸的、凹的、阶梯的、V 形的。我只支持凹的。
这个限制纯粹是为了让对偶松弛紧 — 凹函数有切线上界, 切线斜率可以折进每条数据的有效得分, 组与组之间的耦合就消失了, 拉格朗日松弛紧, ratio 证明成立。
需要先把"凹"这个词说清楚, 因为它跟"递增递减"是两码事 — 凹 = 二阶差分 = 图像永远不"鼓起来", 跟函数本身是涨是跌没关系。直观说就是 marginal increment 不增。
业务上常见的形状几乎都是凹的:
| 业务含义 | 凹? | |
|---|---|---|
| 二次罚: 每多一条罚得更狠 | ✓ (二阶差分 ) | |
| 饱和罚: marginal 罚趋稳 | ✓ | |
| 双向贴近 (TargetDistribution) | ✓ ( 形抛物线) | |
| 覆盖饱和: 至少 条之后边际收益清零 | ✓ (分段线性) | |
| 熵最大化 | ✓ |
不凹的典型反例: 阶梯硬约束 ( 时 0, 超过给 ) — 在阈值处先平后跌, 中间出现凸弯。
从偏好到算子
把上面的抽象写成代码, 引擎只需要识别三个算子:
| 算子 | 数学 | 用例 |
|---|---|---|
UnaryPreference | "给带 testing tag 的多加 0.3 分" | |
VariancePreference | , 凹 | "同 repo 不要太多"、"label 比例 4:3:3" |
SparseBinaryPreference | , 稀疏 | "embedding 太像的互斥"、"7 天内的互斥" |
总目标:
最大化 , 约束是 (每条要么选要么不选), 总数 。
API 设计
UnaryPreference(name, transform: Dataset → ndarray[N])— 用户写一个函数, 给每条数据返回一个 deltaVariancePreference是一组子类 (Quad / LogSaturating / SoftCap / SoftFloor / HardCap / TargetDistribution), 它们都吃一个grouping: Dataset → dict[key, ndarray[int]]— 用户写一个函数, 把数据按某种规则分组。具体的 形状由子类决定 (二次罚 / 上限罚 / 下限罚 / 双向贴近 target)SparseBinaryPreference(name, transform: Dataset → scipy.sparse.spmatrix)— 用户写一个函数, 返回一个稀疏矩阵, 每个非零项 表示一对禁忌
最关键的设计决定是: 保持solver的抽象层级。怎么按列 group_by, 怎么取某 tag 的布尔掩码, 怎么算时间窗内的 pair — 全是业务决定, 用户在自己自行传入funtion。这样加新约束的时候不用改求解器, 只写一个 transform 函数。
举例:
from selector.rules import Quad, SoftCap, UnaryPreference, SparseBinaryPreference
from selector.solver import Selector
def group_by_repo(ds):
out = defaultdict(list)
for i, r in enumerate(ds["repo"]):
out[r].append(i)
return {k: np.asarray(v, np.int64) for k, v in out.items()}
def tag_boost(tag, delta):
def fn(ds):
return np.where(np.array([tag in (t or []) for t in ds["tags"]]),
delta, 0.0).astype(np.float64)
return fn
res = Selector(
ds, k=700, scores=scores,
preferences=[
UnaryPreference(name="testing_boost", transform=tag_boost("testing", 0.3)),
Quad(name="repo_var", grouping=group_by_repo, alpha=0.05),
],
).solve(max_iter=30)
现有方法都怎么做
- MMR (Maximal Marginal Relevance): 贪心, 选下一条时罚一下"和已选的最像的那条"。简单, 但相似度阈值得自己定。
- k-means + 每簇取 top-1: 先聚类后从每簇挑一个。簇数怎么选是经验。
- DPP (Determinantal Point Process): 用一个核矩阵的行列式建模"diverse subset"。数学上漂亮, 但要把"repo 上分散" / "保留长尾 tag" 这类需求写成一个对称半正定核, Claude觉得不太直观, 而且大规模下计算量较大, 但我直接不会(笑)
- SemDeDup / D4 / DSIR 这类数据筛选方法: 各自针对自己关心的痛点做了优化, 我没用过, 不敢评。
- 基于 submodular 性质的贪心算法 (Nemhauser-Wolsey-Fisher 1978): 给出 的最坏情况下界, 实际表现一般会比这个好。但我关心的目标 (例如 "label 比例 X:Y:Z") 不一定满足 submodular 的条件, 这个下界不一定成立; 即使成立, 我也很难知道这次跑出来的解到底好多少。
我最在意的点是: 没有一个数能直接告诉我"这次选的离最优解差多少"
常见需求示例
| 需求 | 配置 |
|---|---|
| 每个 tag 不超过 X 条 | SoftCap, target = X |
| 同一作者不超过 X 条 | SoftCap, target = X |
| 同一语言不超过 Y% | SoftCap, target = int(k*Y/100) |
| 难度三档各占 ≥ X% | SoftFloor, target = int(k*X/100) |
| 正:负:拒绝 = X:Y:Z (双向贴近) | TargetDistribution, 给每个标签一个目标条数 |
| 选出来的 task_type 跟池子分布一致 | TargetDistribution, 按池子比例算 target |
| 长尾类至少保 X 条 | SoftFloor, 分组时只输出小组 |
| 余弦相似 > 阈值的两条互斥 | SparseBinary + kNN, 控制边数 |
| 同 repo 7 天内不要共选 | SparseBinary + 时间窗 |
| 信息熵最大 (按某 categorical) | 自定义 VariancePreference, |
| 集合覆盖 (每 tag 至少一条) | LogSaturating 或 |
| ... | ... |
需要注意的几点:
- 比例约束都先乘 转绝对条数, engine 不知道全局比例
- 真的硬约束建议在数据预处理阶段 filter 掉,
HardCap是软强约束 - 跨算子的"如果-�那么"逻辑表达不了
- 相对阈值 (top X% by score) 表达不了, 需要在预处理阶段算好布尔列再传进来
理论证明
弱对偶定理: 对任意 ,
其中 , 这里 取遍 (没有"总数 = k"的约束)。
证明很短: 对任意可行解 (满足 ),
第一个等号: 可行解满足 , 第二项是 0。第二个不等号: 可行解集是 的子集, 受约束极大值 不受约束极大值。
所以算法过程中遇到的每一个 都是 OPT 的合法上界, 不依赖具体算法是否找到最优。我记录最小的, 输出 dual_bound, 报告
这是真实近似比的下界: 报告 0.99 表示真实近似比 , 真实 OPT 至多比当前解高 1%。
算法骨架
外循环
| 步骤 | 做什么 | 复杂度 |
|---|---|---|
| 1. 凹函数线性化 | 当前每组数量是 , 用切线斜率 ��把它折进每条数据的有效得分 | |
| 2-3. 每个连通分量算 Pareto | 对每个分量预算"恰好选 个时的最大值 和对应 mask " | 主瓶颈, 见下 |
| 4. λ-bisection | 二分搜 让总选中数等于 , 同时记录最小的 作为对偶上界 | |
| 5. 拼回 + 阻尼 | 从 拼出当前解; 用 Frank-Wolfe 步长 更新 , 防震荡 | |
| 6. 收敛判 | gap = 阈值 → 退出 | — |
每轮在弱对偶意义下都给出合法上界。典型实例 5-10 轮收敛到 1% 以内的 gap。
外循环结束之后, 可以再做一个 1-swap polish: 在真实目标 (不是切线近似) 上, 找一对 (剔掉一个 + 加进一个) 使目标增加, 重复直到没有改进。Pollish 通常把 ratio 从 0.99 抬到 0.995+, 几百毫秒级开销 (典型规模)。
内层: 按连通分量求解
把两两约束的稀疏图按连通分量切开 (并查集), 每个分量独立求解。按分量大小 分发不同策略:
| 分量大小 | 求解策略 | 复杂度 |
|---|---|---|
| 1 (孤立点) | 闭式判 | , 全程向量化 |
| 无边的小分量 | 按 排序 + cumsum | |
| ≤ 18 | 暴力枚举 子集 | , 微秒级 |
| 19 ~ 200 | 分支定界 | 通常 < 100ms |
| > 200 | LP 松弛 + iterative rounding | 100ms ~ 秒 |
一个关键的地方是: 在两两约束稀疏 () 的条件下, 分量大小服从重尾分布, 大部分节点是孤立点。这一档跟 是线性的。
整体 wall-time 在稀疏假设下是关于 接近线性的 (大簇档项跟 无关, 只跟最大分量大小有关)。
如果两两约束密集 (), 分量退化成一坨, 大簇档的 LP 变成 , 算法不适用。所以我的建议是: 写两两约束 transform 时先想稀疏化 — kNN 取 top-K, 时间窗、LSH bucket 之类。
自定义 VariancePreference 的注意事项
如果你想加一个新的组凹罚 (比如自己的熵最大化):
- 写一个子类, 重写
phi(self, n: int) -> float - 保证凹性: 离散二阶差分 必须在所有合法 上成立
- 凹性挂了, 切线就不再是上界,
dual_bound会静默地不再是合法 OPT 上界 —approx_ratio失去意义。
小例子, 熵最大化:
class EntropyMax(VariancePreference):
"""phi(n) = -(n+eps) * log(n+eps), 在 n >= 0 上凹"""
eps: float = 1.0
def phi(self, n: int) -> float:
x = float(n) + self.eps
return -x * float(np.log(x))
一个端到端的小例子
跑一个 700-from-7000 的 PR 选择, 三个 preference:
- 给
testingtag 的 PR 加 0.3 分 - 同 repo 选越多边际罚越大 (
Quad) - 同 repo 14 天内不要共选 (sparse pair)
输出:
objective : 619.51
dual_bound : 620.95
approx_ratio : 0.9977
factor_breakdown:
_base : +624.71
testing_boost : +18.32
repo_var : -23.52
temporal : 0.00
components_stats: 6841 components, 312 edges
approx_ratio = 0.9977 表明: 真实 OPT 至多比 619.51 高 0.23%。总耗时 ~1.3 秒。
12w样本取1000的测了一下是4分钟左右, 更大的读者可以自己试试看。
总结
- 数据筛选可以当作组合优化问题来求解
- 优化目标可以显式写出来, 而不是嵌在 prompt 或 质量分 model 里
- 解的质量可以自证, 不需要 baseline 反复对比
如果你也遇到"参数好像调得差不多但说不清"的情况, 不妨照着这篇搓一个, 至少能对解的质量有个数。


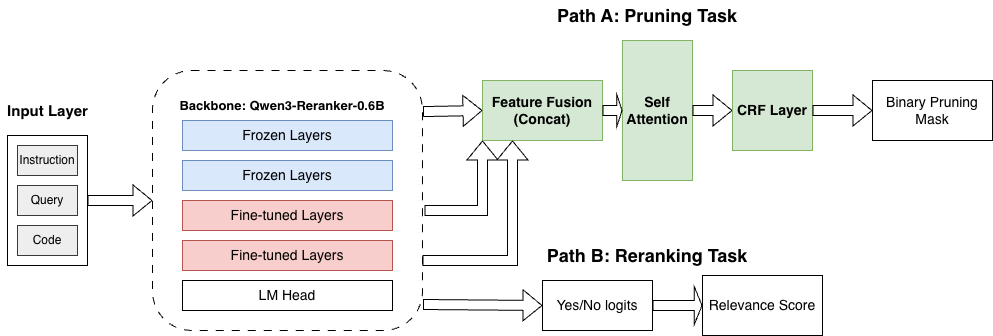
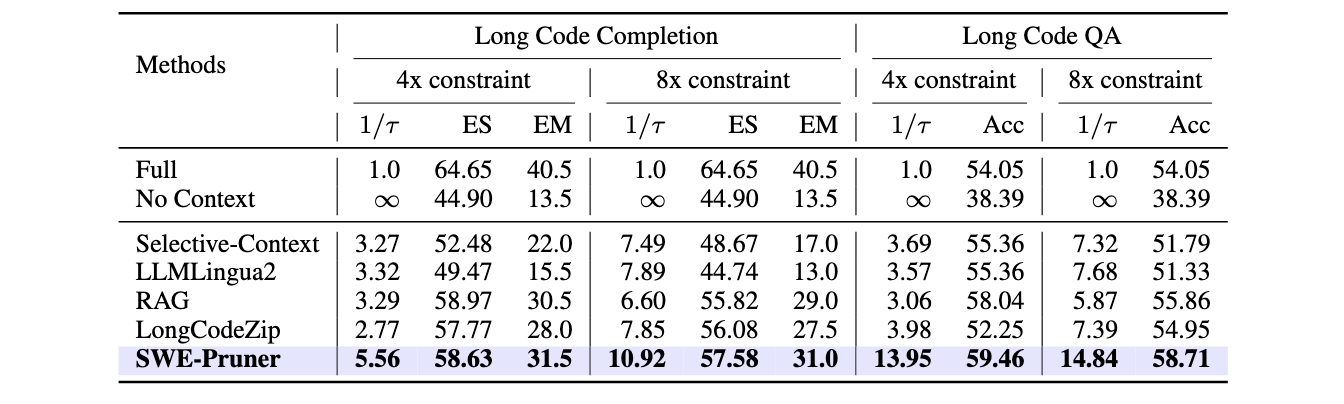

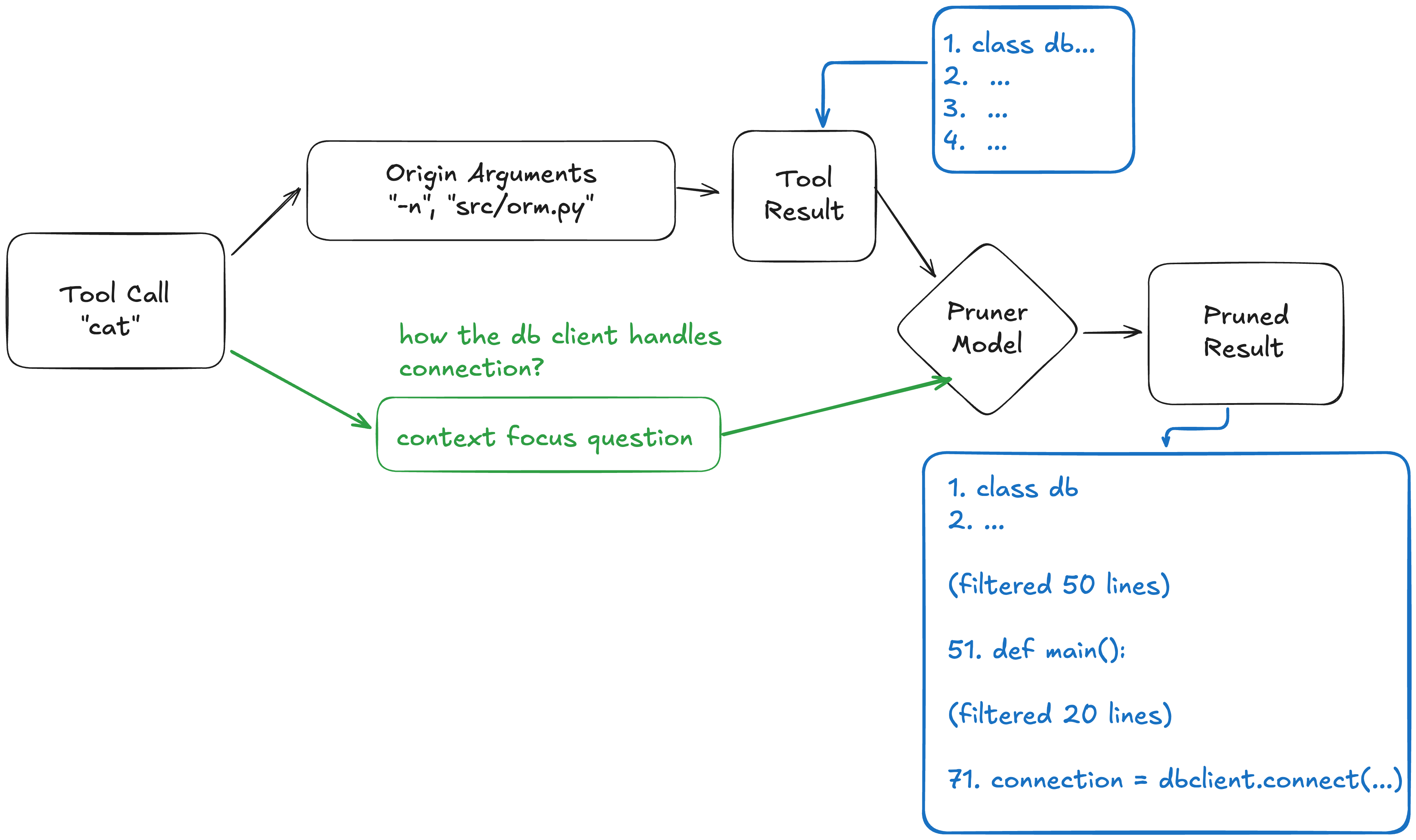
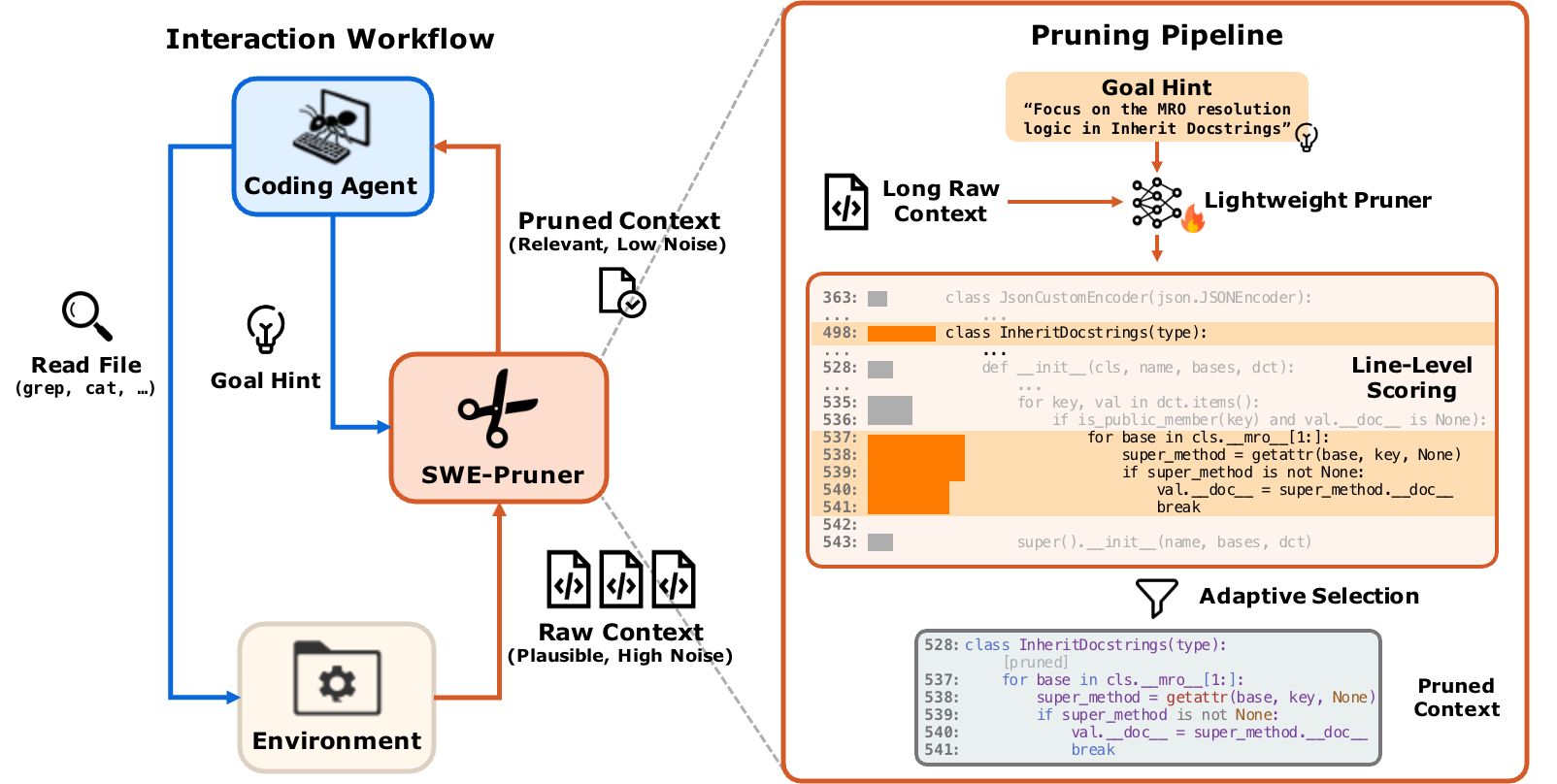
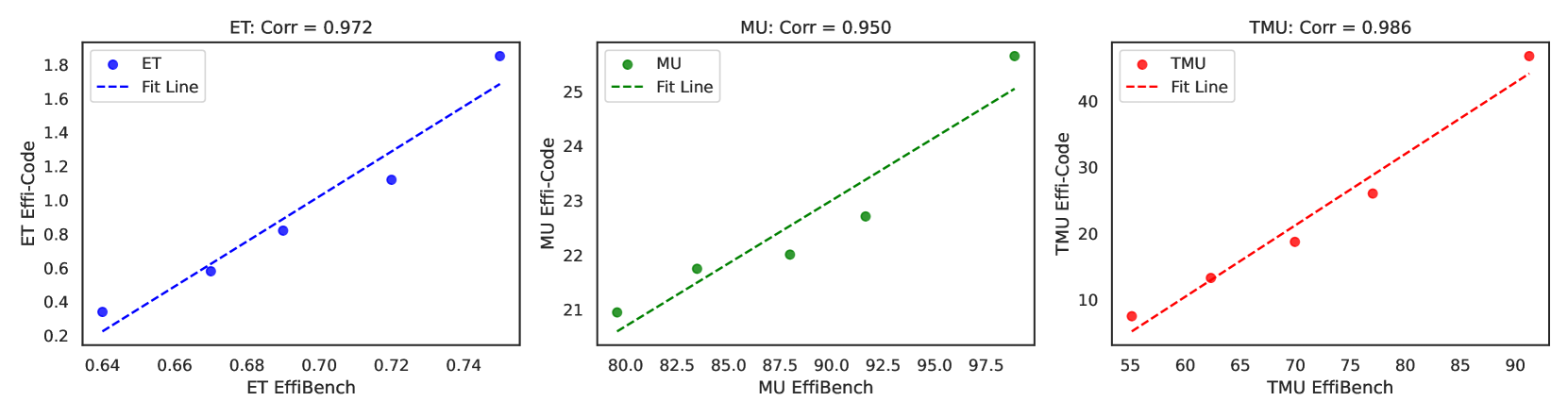


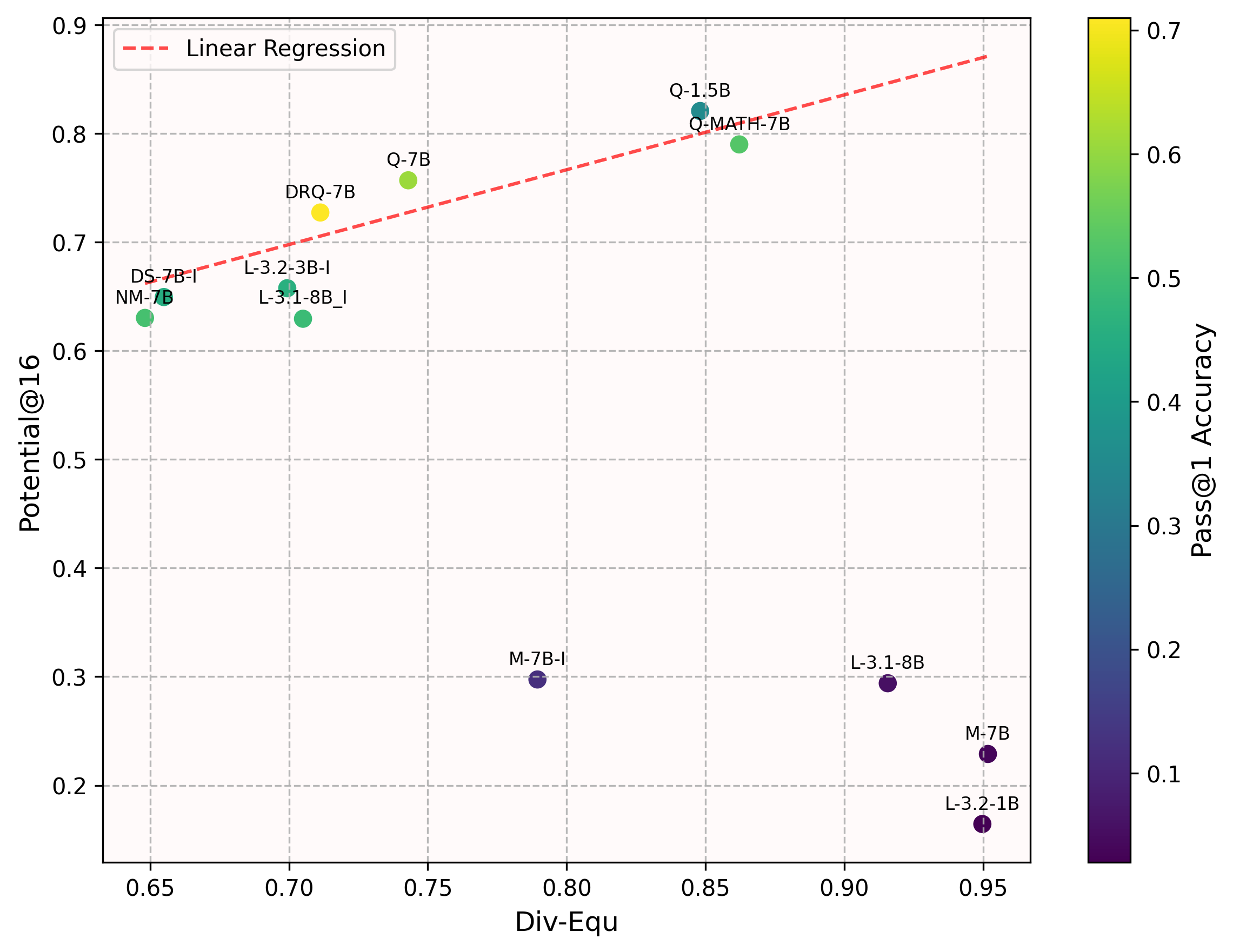
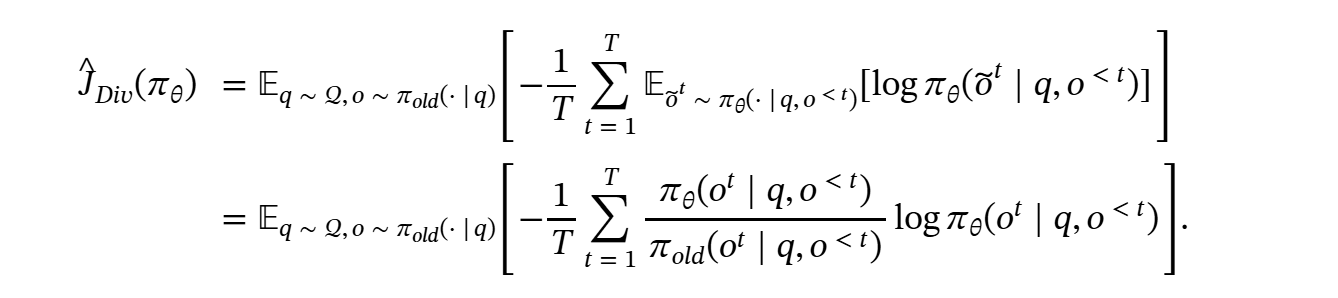
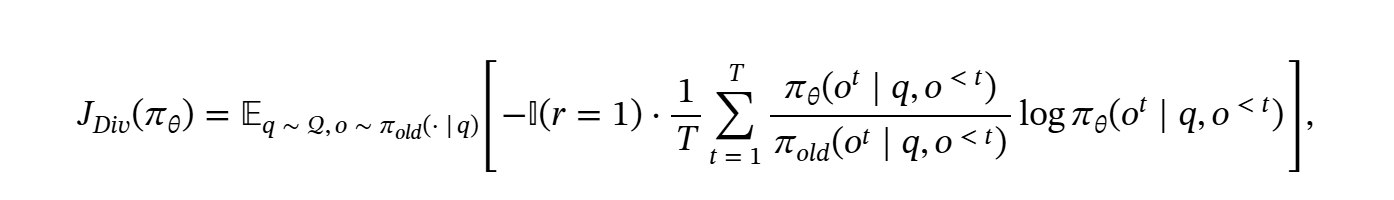
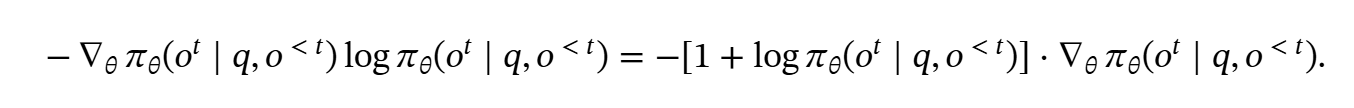
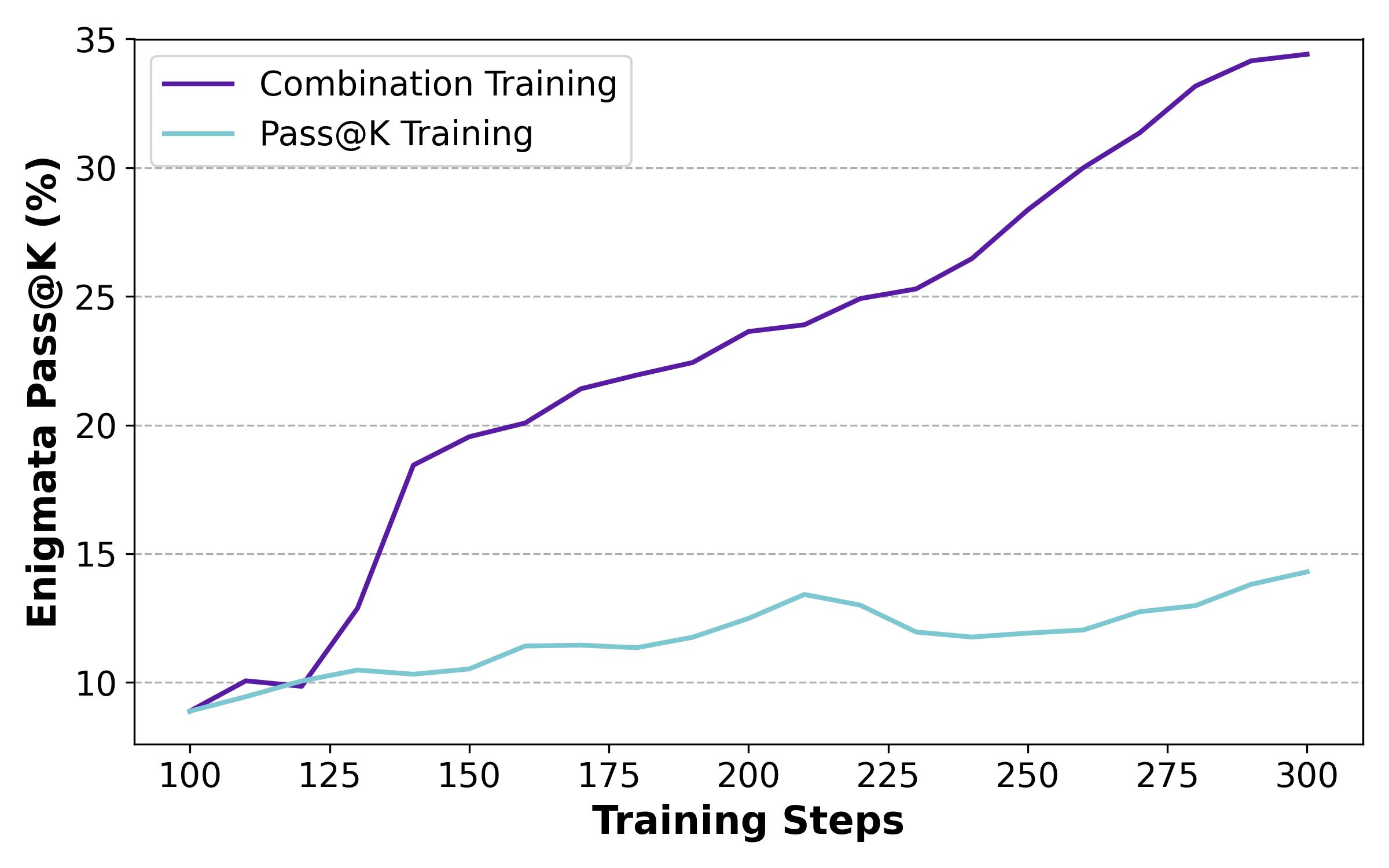

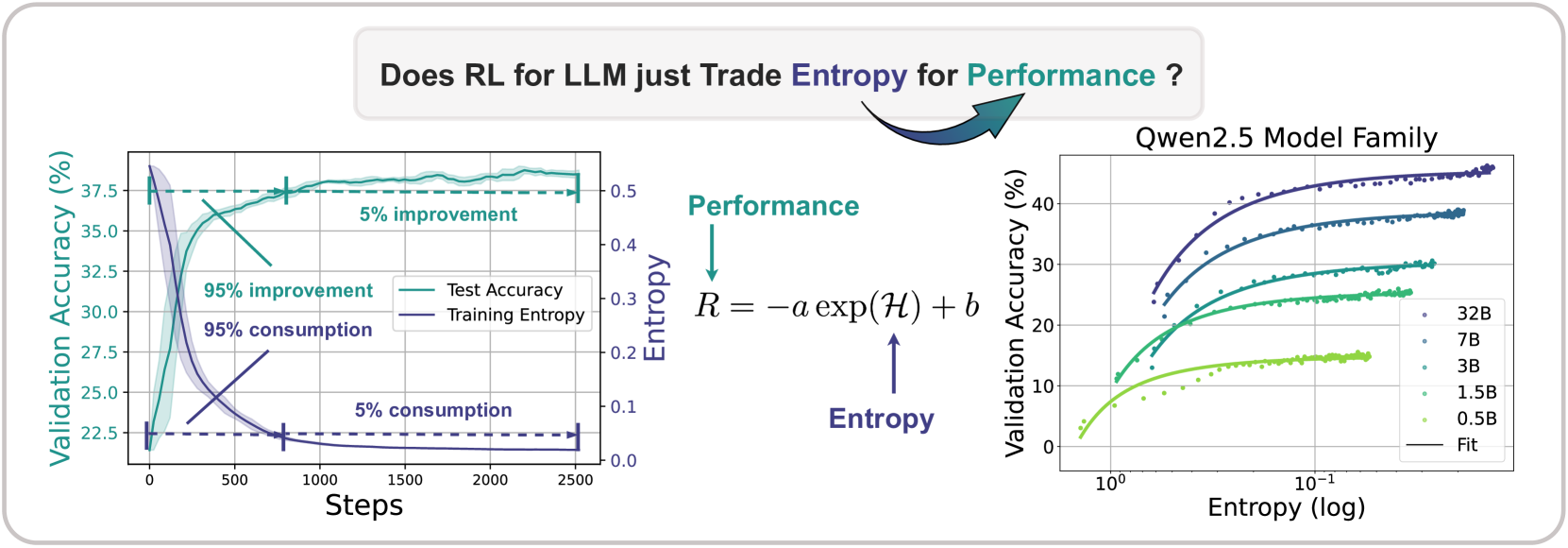
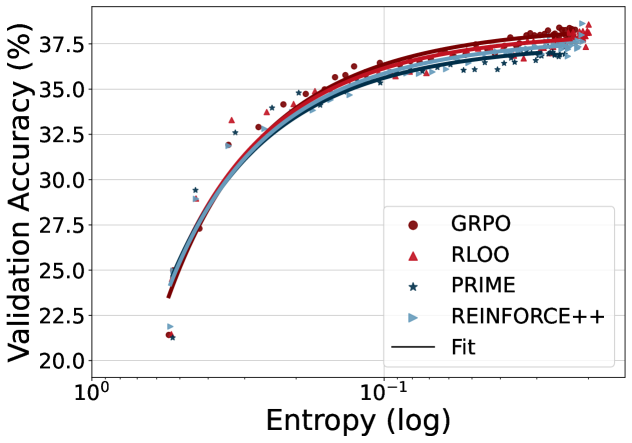
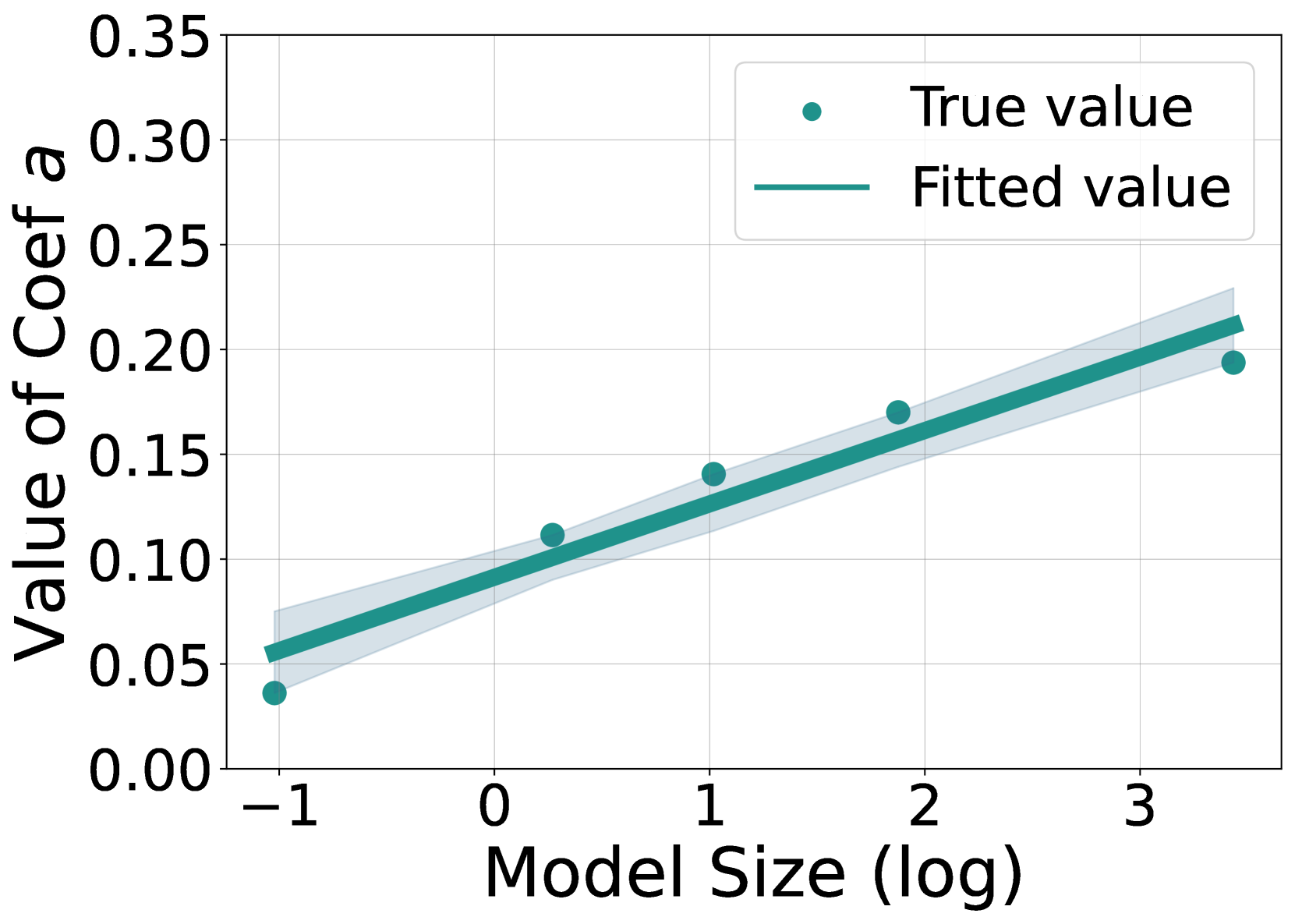


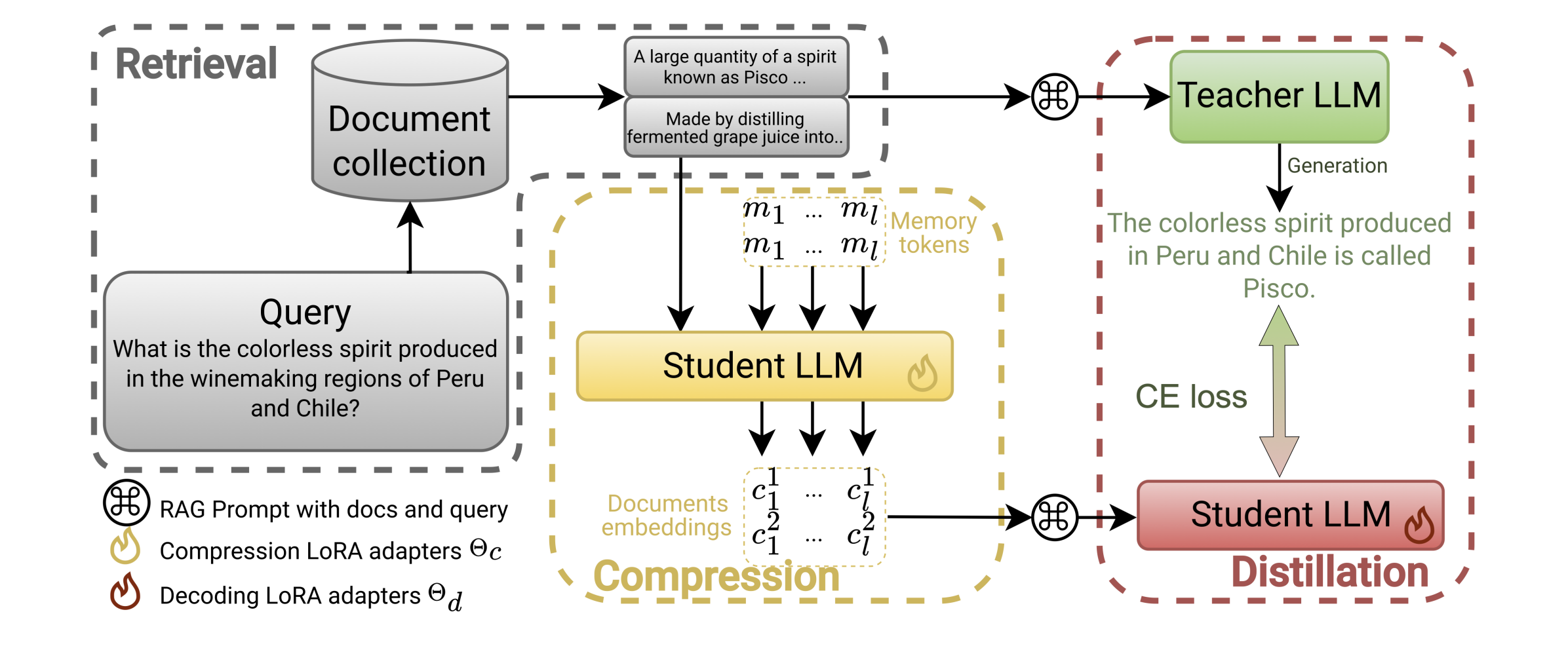
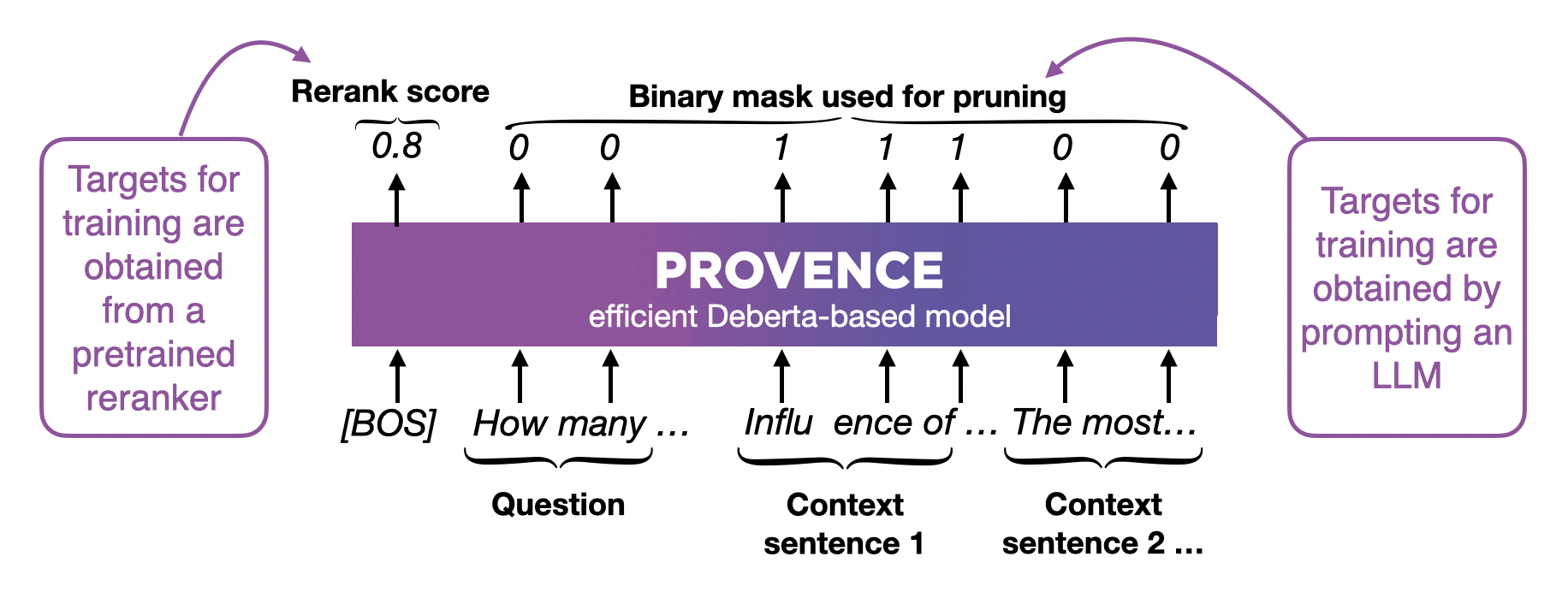
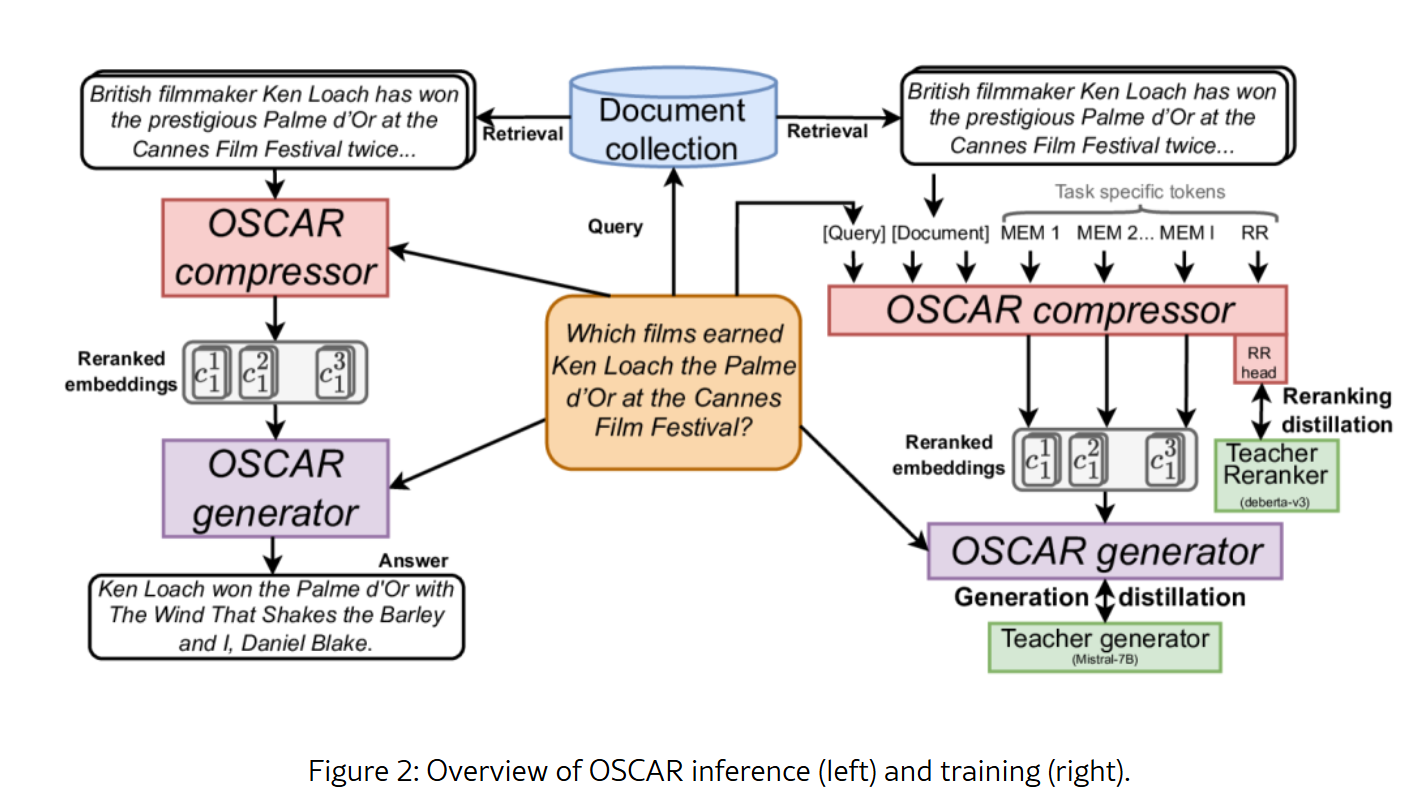
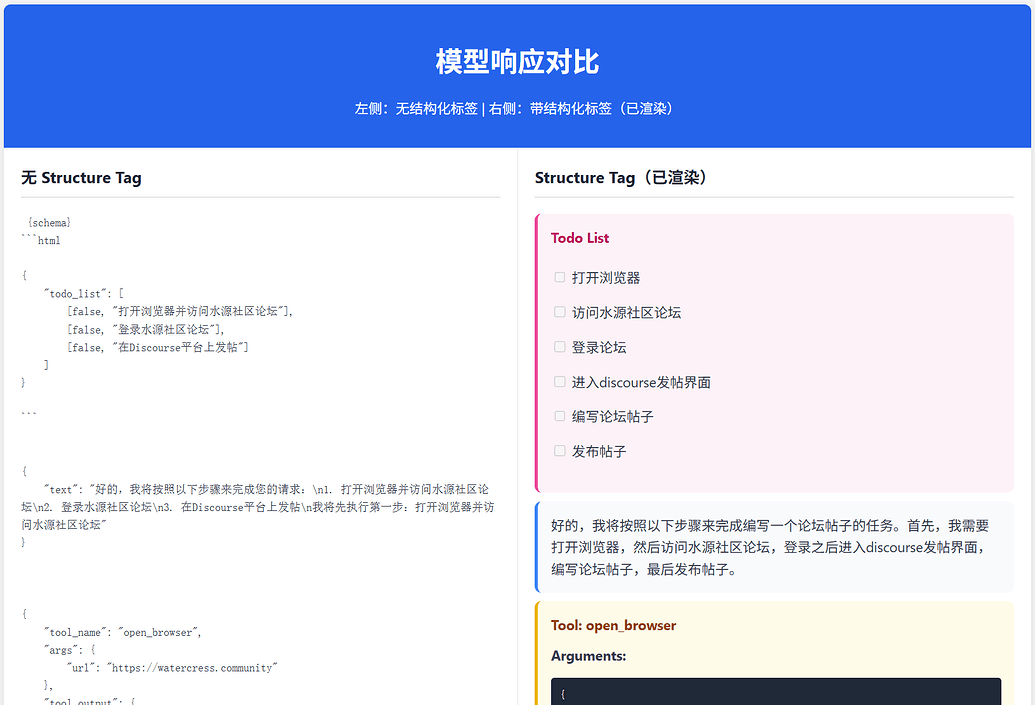
 因此,开蒸!总之也是训了XLM-RoBERTa-large & mBERT的模型替代LLM(可以发现现在的RAG基本就是
因此,开蒸!总之也是训了XLM-RoBERTa-large & mBERT的模型替代LLM(可以发现现在的RAG基本就是