godis源码阅读
tcp
echo
一个优雅超时关闭的方法
// WaitWithTimeout blocks until the WaitGroup counter is zero or timeout
// returns true if timeout
func (w *Wait) WaitWithTimeout(timeout time.Duration) bool {
c := make(chan struct{}, 1)
go func() {
defer close(c)
<!--truncate--> w.Wait()
c <- struct{}{}
}()
select {
case <-c:
return false // completed normally
case <-time.After(timeout):
return true // timed out
}
}
核心数据结构
type EchoHandler struct {
activeConn sync.Map
closing atomic.Boolean
}
然后是tcp server
这个处理signal的值得学习
Notify相当于起了一个新的goroutine去监听
// ListenAndServeWithSignal binds port and handle requests, blocking until receive stop signal
func ListenAndServeWithSignal(cfg *Config, handler tcp.Handler) error {
closeChan := make(chan struct{})
sigCh := make(chan os.Signal)
signal.Notify(sigCh, syscall.SIGHUP, syscall.SIGQUIT, syscall.SIGTERM, syscall.SIGINT)
go func() {
sig := <-sigCh
switch sig {
case syscall.SIGHUP, syscall.SIGQUIT, syscall.SIGTERM, syscall.SIGINT:
closeChan <- struct{}{}
}
}()
listener, err := net.Listen("tcp", cfg.Address)
if err != nil {
return err
}
//cfg.Address = listener.Addr().String()
logger.Info(fmt.Sprintf("bind: %s, start listening...", cfg.Address))
ListenAndServe(listener, handler, closeChan)
return nil
}
// ListenAndServe binds port and handle requests, blocking until close
func ListenAndServe(listener net.Listener, handler tcp.Handler, closeChan <-chan struct{}) {
// listen signal
errCh := make(chan error, 1)
defer close(errCh)
go func() {
select {
case <-closeChan:
logger.Info("get exit signal")
case er := <-errCh:
logger.Info(fmt.Sprintf("accept error: %s", er.Error()))
}
logger.Info("shutting down...")
_ = listener.Close() // listener.Accept() will return err immediately
_ = handler.Close() // close connections
}()
ctx := context.Background()
var waitDone sync.WaitGroup
for {
conn, err := listener.Accept()
if err != nil {
// learn from net/http/serve.go#Serve()
if ne, ok := err.(net.Error); ok && ne.Timeout() {
logger.Infof("accept occurs temporary error: %v, retry in 5ms", err)
time.Sleep(5 * time.Millisecond)
continue
}
errCh <- err
break
}
// handle
logger.Info("accept link")
ClientCounter++
// atomic.AddInt32(&ClientCounter, 1)
waitDone.Add(1)
go func() {
defer func() {
waitDone.Done()
atomic.AddInt32(&ClientCounter, -1)
logger.Info("counter: ", ClientCounter)
}()
handler.Handle(ctx, conn)
}()
}
waitDone.Wait()
}
redis
client
如何做心跳
// Client is a pipeline mode redis client
type Client struct {
conn net.Conn
pendingReqs chan *request // wait to send
waitingReqs chan *request // waiting response
ticker *time.Ticker
addr string
status int32
working *sync.WaitGroup // its counter presents unfinished requests(pending and waiting)
}
func (client *Client) heartbeat() {
for range client.ticker.C {
client.doHeartbeat()
}
}
func (client *Client) doHeartbeat() {
request := &request{
args: [][]byte{[]byte("PING")},
heartbeat: true,
waiting: &wait.Wait{},
}
request.waiting.Add(1)
client.working.Add(1)
defer client.working.Done()
client.pendingReqs <- request
request.waiting.WaitWithTimeout(maxWait)
}
protocol
redis 的字节流协议RESP
Redis 自 2.0 版本起使用了统一的协议 RESP (REdis Serialization Protocol)
二进制安全:允许协议payload中出现任意字符而不会导致故障
https://www.cnblogs.com/Finley/p/11923168.html
RESP 定义了5种格式:
- 简单字符串(Simple String): 服务器用来返回简单的结果,比如"OK"。非二进制安全,且不允许换行。
- 错误信息(Error): 服务器用来返回简单的错误信息,比如"ERR Invalid Synatx"。非二进制安全,且不允许换行。
- 整数(Integer): llen、scard 等命令的返回值, 64位有符号整数
- 字符串(Bulk String): 二进制安全字符串, 比如 get 等命令的返回值
- 数组(Array, 又称 Multi Bulk Strings): Bulk String 数组,客户端发送指令以及 lrange 等命令响应的格式
RESP 通过第一个字符来表示格式:
- 简单字符串:以"+" 开始, 如:"+OK\r\n"
- 错误:以"-" 开始,如:"-ERR Invalid Synatx\r\n"
- 整数:以":"开始,如:":1\r\n"
- 字符串:以
$开始, 两行,第一行$+正文长度,第二行实际内容+换行,实际内容可以有换行等特殊符号,二进制安全 - 数组:以
*开始,第一行*+ 数组长度len,后面是len组bulk string
datastruct
- bitmap 没什么好说的
- dict
wildcard的简单通配符支持
func (dict *SimpleDict) DictScan(cursor int, count int, pattern string) ([][]byte, int) {
result := make([][]byte, 0)
matchKey, err := wildcard.CompilePattern(pattern)
if err != nil {
return result, -1
}
for k := range dict.m {
if pattern == "*" || matchKey.IsMatch(k) {
raw, exists := dict.Get(k)
if !exists {
continue
}
result = append(result, []byte(k))
result = append(result, raw.([]byte))
}
}
return result, 0
}
capacity 得到大于param的最小2幂数, 在c++可能是gcc builtin,这里就自己实现位运算了
func computeCapacity(param int) (size int) {
if param <= 16 {
return 16
}
n := param - 1
n |= n >> 1
n |= n >> 2
n |= n >> 4
n |= n >> 8
n |= n >> 16
if n < 0 {
return math.MaxInt32
}
return n + 1
}
concurrent dict类是一个有输入指定的shardCount个槽的table, 每个格子里面是一个map+RWlock,通过对字符串hash得到格子
这是hashmap分片
redis没有做java那样的链表-红黑树升级,估计是觉得大集合或者大map才是常态
优点:减少读写锁的竞争,提高读写效率
缺点: 需要两次hash, 分片导致scan效率下降, 弥补方法是需要顺序等的scan使用sortedset跳表结构
KV 内存数据库的核心是并发安全的哈希表,常见的设计有几种:
- sync.map: golang 官方提供的并发哈希表, 适合读多写少的场景。但是在 m.dirty 刚被提升后会将 m.read 复制到新的 m.dirty 中,在数据量较大的情况下复制操作会阻塞所有协程,存在较大的隐患。关于 sync.map 的详细讨论推荐阅读鸟窝:sync.Map揭秘
- juc.ConcurrentHashMap: java 的并发哈希表采用分段锁实现。在进行扩容时访问哈希表线程都将协助进行 rehash 操作,在 rehash 结束前所有的读写操作都会阻塞。因为缓存数据库中键值对数量巨大且对读写操作响应时间要求较高,使用juc的策略是不合适的。
- memcached hashtable: 在后台线程进行 rehash 操作时,主线程会判断要访问的哈希槽是否已被 rehash 从而决定操作 old_hashtable 还是操作 primary_hashtable。
memcached hashtable 的渐进式 Rehash 策略使主线程和rehash线程之间的 data race 限制在哈希槽内,最小化rehash操作对读写操作的影响,这是最理想的实现方式。但由于作者才疏学浅无法使用 golang 实现该策略故忍痛放弃(主要原因在于 golang 没有 volatile 关键字, 保证可见性的操作非常复杂),欢迎各位读者讨论。
本文采用 golang 社区广泛使用的分段锁策略。我们将 key 分散到固定数量的 shard 中避免 rehash 操作。shard 是有锁保护的 map, 当 shard 进行 rehash 时会阻塞shard内的读写,但不会对其他 shard 造成影响。
这种��策略简单可靠易于实现,但由于需要两次 hash 性能略差。
Redis 的渐进式 rehash 是一种用于在不阻塞数据库的情况下调整哈希表大小的机制。当 Redis 的哈希表(例如用于实现字典的数据结构)已满或接近满时,需要进行 rehash 操作,即重新分配哈希表中的键值对到一个更大的哈希表中。
传统的 rehash 方法会一次性将所有键值对从旧哈希表复制到新哈希表,这会导致数据库在 rehash 期间被阻塞,影响性能。而渐进式 rehash 则采用了一种更优雅的方式,它将 rehash 操作分散到多个步骤中,在不影响数据库正常读写操作的情况下完成。
以下是渐进式 rehash 的工作原理:
- 分配新哈希表: Redis 为新的哈希表分配两倍于旧哈希表大小的空间。
- 渐进迁移: Redis 不会一次性将所有键值对迁移到新哈希表。每次执行一个读写操作时,Redis 会将一部分键值对从旧哈希表迁移到新哈希表。具体来说,Redis 会选择旧哈希表中的一个或多个桶(bucket),将桶中的所有键值对迁移到新哈希表中。
- 更新哈希表指针: Redis 会维护一个
rehashidx指针,指向旧哈希表中正在迁移的桶的索引。每次迁移完成后,rehashidx指针都会更新。- 并发读写: 在 rehash 过程中,Redis 仍然可以处理读写操作。读操作会同时查询旧哈希表和新哈希表;写操作则会直接写入新哈希表。
- 完成迁移: 当
rehashidx指针达到旧哈希表的末尾时,rehash 操作完成。此时,旧哈希表将被释放,新哈希表成为当前的哈希表。渐进式 rehash 的优势:
- 避免阻塞: rehash 操作不会阻塞数据库,保证了数据库的可�用性。
- 平滑过渡: rehash 操作平滑地进行,不会对数据库性能造成突发性的影响。
- 高效利用资源: rehash 操作在多个步骤中完成,不会占用过多的系统资源。
rehash的条件
1、服务器目前没有在执行 BGSAVE 命令或者 BGREWRITEAOF 命令,并且哈希表的负载因子大于等于 1。
2、服务器目前正在执行 BGSAVE 命令或者 BGREWRITEAOF 命令,并且哈希表的负载因子大于等于 5。
根据 BGSAVE 命令或 BGREWRITEAOF 命令是否正在执行,服务器执行扩展操作所需的负载因子并不相同,这是因为在执行 BGSAVE 命令或 BGREWRITEAOF命令的过程中, Redis会fork一个子进程,而大多数操作系统都采用写时复制(copy-on-write)技术来优化子进程的使用效率,所以在子进程存在期间,服务器会提高执行扩展操作所需的负载因子,从而尽可能地避免在子进程存在期间进行哈希表扩展操作,这可以避免不必要的内存写入操作, 最大限度地节约内存。
**触发收缩操作条件:**当哈希表的负载因子小于0.1时,程序自动开始对哈希表执行收缩操作
redis rehash
(注意主进程始终是单线程的)
会创建两个表,当第一个负载因子达到阈值时触发rehash, 给第二个表分配两倍内存,更新rehash状态,然后返回
将rehash idx设置为0
之后每次对字典执行添加、删除、查找、更新时,除了已有的操作外,还会将原始表在rehashidx索引上的所有kv rehash到新表
同时在rehash过程之中, 写值会写到新的表上
当rehash idx为原表长度时,结束rehash
rehash过程中的scan优化
在scan进行中,触发rehash, 如何让其不重复扫描?
使用了高位��序scan(反向二进制迭代)的优化手法
具体而言,假设原来的hash key是k, index = k % size
新表上就是 k % 2 * size = index 或 index + size
即一个 二进制为0b00..0XXX的index, 0b00...1000的size, 在新表上要么是00b00..0XXX,要么是0b00..1XXX
这样我使用从高到低位遍历
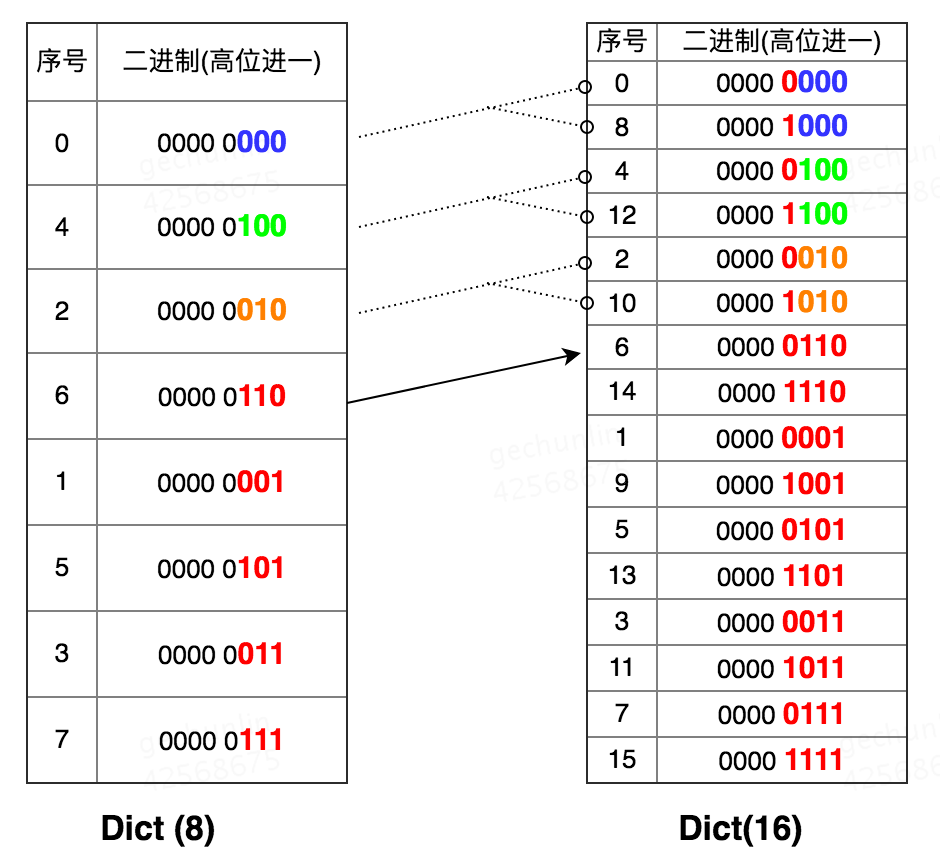
把rehash后可能的两个index放到一起了,不改变顺序
无论在何时中途发生扩容,都只要扫描一遍
确实是magic
- lockmap
这个concurrentmap还有一些功能没有支持
例如 锁key, 即对N个key上对象的原子操作MSETNX, incr等等
- 如果每个key都分配锁, 如果不回收内存开销不小; 如果回收, 需要某种形式的引用计数来回收, 我能想到的是用CAS看他的ref是不是0来提供并发安全, 如果是0,说明有其他goroutine应该再删除,新建锁。但godis作者觉得太复杂没做
- 取而代之的是他锁了key对应的槽,这性能下降肯定是不少的, 因为不同的key实际上均匀分配到了不同的槽
- sortedset 简单跳表
database backup
aof, rdb
redis提供的两种backup方式,aof是在执行写命令前写日志,从而可以在另一个redis上重放; rdb是把所有数据持久化后压缩为二进制
aof有三种策略
appendfsync always总是立刻落盘, 每次调用fsync()appendfsync everysec这个在go里面非常简单�,起一个ticker计时器定时fsyncappendfsync no: 不调用fsync()
aof 持久化
起一个aof协程
主协程不断把执行的写cmd通过chan发送给aof协程
type DB struct {
// 主线程使用此channel将要持久化的命令发送到异步协程
aofChan chan *reply.MultiBulkReply
// append file 文件描述符
aofFile *os.File
// append file 路径
aofFilename string
// aof 重写需要的缓冲区,将在AOF重写一节详细介绍
aofRewriteChan chan *reply.MultiBulkReply
// 在必要的时候使用此字段暂停持久化操作
pausingAof sync.RWMutex
}
需要注意一个细节
expire 命令要用等效的 expireat 命令替换。举例说明,10:00 执行
expire a 3600表示键 a 在 11:00 过期,在 10:30 载入AOF文件时执行expire a 3600就成了 11:30 过期与原数据不符。
func (handler *Handler) handleAof() {
handler.currentDB = 0
for p := range handler.aofChan {
// 使用锁保证每次都会写入一条完整的命令
handler.pausingAof.RLock()
// 每个客户端都可以选择自己的数据库,所以 payload 中要保存客户端选择的数据库
// 选择的数据库与 aof 文件中最新的数据库不一致时写入一条 Select 命令
if p.dbIndex != handler.currentDB {
// select db
data := reply.MakeMultiBulkReply(utils.ToCmdLine("SELECT", strconv.Itoa(p.dbIndex))).ToBytes()
_, err := handler.aofFile.Write(data)
if err != nil {
logger.Warn(err)
continue // skip this command
}
handler.currentDB = p.dbIndex
}
// 写入命令内容
data := reply.MakeMultiBulkReply(p.cmdLine).ToBytes()
_, err := handler.aofFile.Write(data)
if err != nil {
logger.Warn(err)
}
handler.pausingAof.RUnlock()
}
// 关闭过程中主协程会先关闭 handler.aofChan,然后使用 <-handler.aofFinished 等待缓冲区中的命令落盘
// 通过 handler.aofFinished 通知主协程 aof 缓冲区处理完毕
handler.aofFinished <- struct{}{}
}
读取时用同样的命令解析器即可
混合持久化:
redis可以设置
aof-use-rdb-preamble yes
来开启混合��持久化, 流程为
- fork
- 由于COW, fork的子进程自然的具备了内存“快照”, 主进程照常读写就行, 子进程把内存中的数据存为rdb文件
- 在这个时间点之后的新增命令再作为aof文件存储
混合持久化有不少优点,既弥补了aof重做耗时长的缺点,又弥补了rdb保存开销大,实时性不高的缺点
但以上流程基于fork,在go里面没有原生的fork,甚至不太能模拟一个fork
- syscall.ForkExec: 只能fork之后立刻exec调用一个已有的二进制程序
- 强行调用原生syscall: 没有意义,因为go会起一堆os thread用来服务goruntine, GC, ...; 而原生的fork只有一个fork的thread,不能指望任何go程序在上面工作
- 使用reexec等基于namespace的偷天换日技法: 本质上也是一样的, 并不真正发生了fork, 也不共享内存等, 需要自己拷贝
所以看起来没实现这个
aof重写:
压缩aof文件(通过消除无用的对相同key的操作)
redis还是用fork的
godis想了个基于fs的替代方法
因此我们设计了一套比较复杂的流程:
- 暂停AOF写入 -> 更改状态为重写中 -> 准备重写 -> 恢复AOF写入
- 重写协程读取 AOF 文件中的前一部分(重写开始前的数据,不包括读写过程中写入的数据)并重写到临时文件(tmp.aof)中
- 暂停AOF写入 -> 将重写过程中产生的新数据写入tmp.aof -> 使用临时文件tmp.aof覆盖AOF文件(使用文件系统的mv命令保证安全 -> 恢复AOF写入
也就是说,在重写开始时去得到当前aof的offset(size)
利用aof是追加的性质, 这部分不会被改变, 对 0-offset的部分重写到新文件tmp, godis正常执行命令写到原来的文件
重写完成后, 暂停执行命令, 把offset到最新的少量数据写入tmp, 再用mv把tmp覆盖原始aof,最后恢复可以继续执行命令
mv实际上是meta data的修改,因而可以保证效率
redis内存压缩
元素较少时: ziplist
其结构为
<zlbytes> <zltail> <zllen> <entry> <entry> ... <entry> <zlend>
- zlbytes: uint32 型, 存储整个ziplist当前被分配的空间,包含自身占用的4个字节。
- zltail: uint32 型, 存储ziplist中最后一个entry相对头部的偏移量, 用于直接访问尾端元素避免遍历。
- zllen: uint16 型, 记录 ziplist 中元素的个数
- entry: 实际存储元素的单元
- zlend: 0xff 标记 ziplist 的结尾, 没有 entry 以 0xff 开头不会出现误判的问题
ziplist不会预留拓展空间, 插入新元素需要realloc
在元素小于阈值且value字节数小于阈值的情况下会使用ziplist
quicklist:节点是ziplist的双向链表
ziplist越小,越接近linkedlist, 存储效率下降,修改效率上升
ziplist越大, 越接近ziplist, 存储效率上升,修改效率下降
默认是8kb, 但可调
压缩中间节点(一般对于长集合, 两边访问频率较高): 默认不压缩,可设置
intset
当集合中的元素均为整数且元素数少于
set-max-intset-entries时,redis 采用 inset 编码存储集合。当插入非整数元素或元素数超过阈值后,intset 会升级为 hashtable 编码进行存储。intset 的源码可以在: redis/intset.c 中找到。
intset 是整数元素组成的有序数组, 可以支持 O(logn) 级别的查询。
intset 的内存结构与 ziplist 类似是一段的内存。它由三个部分组成:
- encoding: 表示intset中的每个数据元素用几个字节来存储。它有三种可能的取值:
- INTSET_ENC_INT16表示每个元素用2个字节存储
- INTSET_ENC_INT32表示每个元素用4个字节存储
- INTSET_ENC_INT64表示每个元素用8个字节存储。
- length: 表示intset中的元素个数。encoding和length两个字段构成了intset的头部(header)。
- contents: 表示实际存储的内容。它是一个C语言的柔性数组(flexible array member)。
需要注意的是,每次添加元素 intset 都会检查是否需要将 INTSET_ENCODING 升级为更长的整数。与每个 entry 拥有独立 encoding 的 ziplist 不同,inset 中所有成员使用统一的 encoding。
分布式事务
两阶段提交(2-Phase Commit, 2PC)算法是解决我们遇到的一致性问题最简单的算法。在 2PC 算法中写操作被分为两个阶段来执行:
- Prepare 阶段
- 协调者向所有参与者发送事务内容,询问是否可以执行事务操作。在 Godis 中收到客户端 MSET 命令的节点是事务的协调者,所有持有相关 key 的节点都要参与事务。
- 各参与者锁定事务相关 key 防止被其它操作修改。各参与者写 undo log 准备在事务失败后进行回滚。(这里的undo log在godis里面只是内存中的cmdline而已, 因为也不落盘, 所以没有对宕机负责的义务)
- 参与者回复协调者可以提交。若协调者收到所有参与者的YES回复,则准备进行事务提交。若有参与者回复NO或者超时,则准备回滚事务
- Commit 阶段
- 协调者向所有参与者发送提交请求
- 参与者正式提交事务,并在完成后释放相关 key 的锁。
- 参与者协调者回复ACK,协调者收到所有参与者的ACK后认为事务提交成功。
- Rollback 阶段
- 在事务请求阶段若有参与者回复NO或者超时,协调者向所有参与者发出回滚请求
- 各参与者执行事务回滚,并在完成后释放相关资源。
- 参与者协调者回复ACK,协调者收到所有参与者的ACK后认为事务回滚成功。
2PC是一种简单的一致性协议,它存在一些问题:
- 单点服务: 若协调者突然崩溃则事务流程无法继续进行或者造成状态不一致
- 无法保证一致性: 若协调者第二阶段发送提交请求时崩溃,可能部分参与者受到COMMIT请求提交了事务,而另一部分参与者未受到请求而放弃事务造成不一致现象。
- 阻塞: 为了保证事务完成提交,各参与者在完成第一阶段��事务执行后必须锁定相关资源直到正式提交,影响系统的吞吐量。
func MSet(cluster *Cluster, c redis.Connection, args [][]byte) redis.Reply {
// 解析参数
argCount := len(args) - 1
if argCount%2 != 0 || argCount < 1 {
return reply.MakeErrReply("ERR wrong number of arguments for 'mset' command")
}
size := argCount / 2
keys := make([]string, size)
valueMap := make(map[string]string)
for i := 0; i < size; i++ {
keys[i] = string(args[2*i+1])
valueMap[keys[i]] = string(args[2*i+2])
}
// 找到相关 key 所属的节点
groupMap := cluster.groupBy(keys)
if len(groupMap) == 1 { // do fast
// 若所有的 key 都在同一个节点直接执行,不使用较慢的 2pc 算法
for peer := range groupMap {
return cluster.Relay(peer, c, args)
}
}
// 开始准备阶段
var errReply redis.Reply
txId := cluster.idGenerator.NextId() // 使用 snowflake 算法决定事务 ID
txIdStr := strconv.FormatInt(txId, 10)
rollback := false
// 向所有参与者发送 prepare 请求
for peer, group := range groupMap {
peerArgs := []string{txIdStr}
for _, k := range group {
peerArgs = append(peerArgs, k, valueMap[k])
}
var resp redis.Reply
if peer == cluster.self {
resp = PrepareMSet(cluster, c, makeArgs("PrepareMSet", peerArgs...))
} else {
resp = cluster.Relay(peer, c, makeArgs("PrepareMSet", peerArgs...))
}
if reply.IsErrorReply(resp) {
errReply = resp
rollback = true
break
}
}
if rollback {
// 若 prepare 过程出错则执行回滚
RequestRollback(cluster, c, txId, groupMap)
} else {
// prepare 成功,要求所有节点提交
_, errReply = RequestCommit(cluster, c, txId, groupMap)
rollback = errReply != nil
}
if !rollback {
return &reply.OkReply{}
}
return errReply
}
func requestCommit(cluster *Cluster, c redis.Connection, txID int64, peers map[string][]string) ([]redis.Reply, reply.ErrorReply) {
var errReply reply.ErrorReply
txIDStr := strconv.FormatInt(txID, 10)
respList := make([]redis.Reply, 0, len(peers))
// 要求每个节点进行提交
for peer := range peers {
var resp redis.Reply
if peer == cluster.self {
resp = execCommit(cluster, c, makeArgs("commit", txIDStr))
} else {
resp = cluster.relay(peer, c, makeArgs("commit", txIDStr))
}
if reply.IsErrorReply(resp) {
errReply = resp.(reply.ErrorReply)
break
}
respList = append(respList, resp)
}
// 若有节点提交失败则要求所有节点回滚
if errReply != nil {
requestRollback(cluster, c, txID, peers)
return nil, errReply
}
return respList, nil
}
常见的分布式事务实现方案有 TCC(try-confirm-catch)事务、MQ 事务消息、Saga 事务等。分布式事务主要有两种实现思路,第一种的典型代表�是 TCC 事务,TCC 事务分为三个阶段:
- Try 阶段: 事务协调器要求参与方预留并锁定事务所需资源;
- Confirm 阶段: 若所有参与方都表示资源充足可以提交,事务协调器会向所有参与方发出 Confirm 指令,要求实际执行事务。
- Cancel 阶段: 若 Try 或 Confirm 阶段任一参与者表示无法继续事务协调器会向所有参与方发出 Cancel 指令解锁预留资源并回滚事务。
第二种实现思路的典型代表是 Saga 事务,Saga 事务将一个大事务拆分成多个有序的子事务并且每个子事务都准备了撤销操作,事务协调器会顺序的执行子事务,如果某个步骤失败,则根据相反顺序一次执行一次撤销操作。
上面我们只简单介绍了分布式事务保证原子性的机制,在实际实现中还要考虑分布式事务的一致性(强一致还是最终一致)、隔离性(Saga 事务会暴露事务执行到一半时的状态)、对业务的侵入性、并发量等各种问题,简言之分布式事务是一种非常复杂、成本很高的技术。
由于分布式事务的高成本,在实际开发中经常使用「对账」的方式来保证多模块事务的最终一致性,即用离线任务定时扫描数据库找出未正确处理的事务,然后按照预定策略进行补偿(比如撤销未成功付款用户的会员身份)或者要求人工介入修复
geohash
一直四等分矩形并编码,此时编码前缀相同意味着在相同的矩形内部,也就是说在某个矩形内部可以转化成坐标编码在一个区间内
用SortedSet进行索引就可以在对数时间内查找
关于误差范围和投影误差百科吧(
单机事务
Redis 命令只会因为错误的语法而失败(并且这些问题不能在入队时发现),或是命令用在了错误类型的键上面:这也就是说,从实用性的角度来说,失败的命令是由编程错误造成的,而这些错误应该在开发的过程中被发现,而不应该出现在生产环境中。 因为不需要对回滚进行支持,所以 Redis 的内部可以保持简单且快速。 有种观点认为 Redis 处理事务的做法会产生 bug,然而需要注意的是,在通常情况下,回滚并不能解决编程错误带来的问题。举个例子,如果你本来想通过 INCR 命令将键的值加上 1 ,却不小心加上了 2 ,又或者对错误类型的键执行了 INCR ,回滚是没有办法处理这些情况的。鉴于没有任何机制能避免程序员自己造成的错误,并且这类错误通常不会在生产环境中出现,所以 Redis 选择了更简单、更快速的无回滚方式来处理事务。
如果要在godis里面支持单机事务
为了在遇到运行时错误时事务可以回滚(原子性),可用的回滚方式有两种:
- 保存修改前的value, 在回滚时用修改前的value进行覆盖
- 使用回滚命令来撤销原命令的影响。举例来说:键A原值为1,调用了
Incr A之后变为了2,我们可以再执行一次Set A 1命令来撤销 incr 命令。
由于不落盘+命令简单可逆,所以godis采用了第二种
godis能实现隔离级别
脏读 - 不可重复读 - 幻读
kv没有幻读, 因为源码中一直用的是读写锁,并且遵循2PL的加放锁约定
所以一旦一�个T1事务触发了写, 那其他事务直接阻塞, 比timestamp的occ暴力一些, watch也是如果时间戳不对(有其他goroutine写过)就回滚