ucb cs186 课程笔记(更新中)
lec2
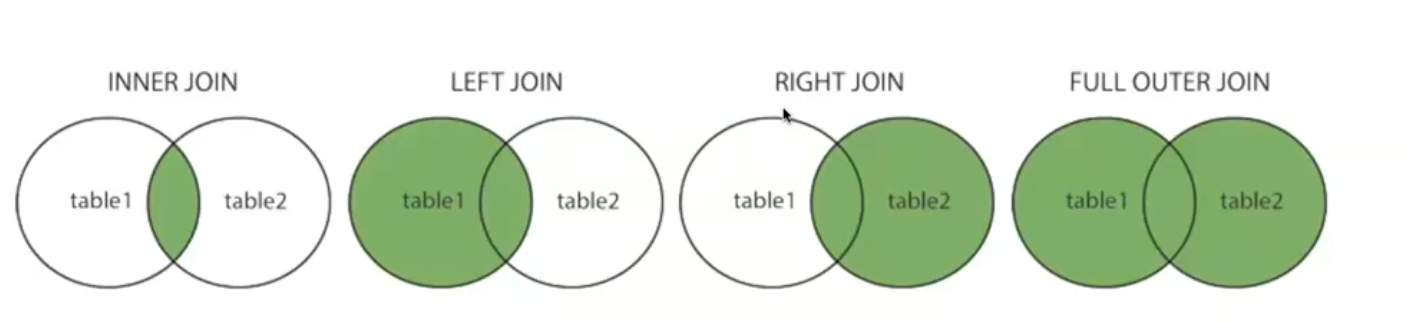
join: inner join, natural join, outer join
sql 实际执行模型 写起来是 SELECT - FROM - GROUP BY - HAVING - WHERE - DISTINCT - ORDER BY
实际是 FROM(table过滤) - GRUOP BY(行分组) - HAVING(组过滤) - WHERE(行过滤) - DISTINCT(行去重) - SELECT(行内列过滤)
inner join:叉积,对AB所有行组合
SELECT * FROM TABLE1 t1, TABLE2 t2
WHERE t1.id = t2.id
AND ...
-- 等效于
SELECT * FROM
TABLE1 t1 INNER JOIN TABLE2 t2
ON t1.id = t2.id
WHERE ...
-- 下面这种更加清晰一点
-- 等效于
SELECT * FROM
TABLE1 t1 NATURAL JOIN TABLE2 t2
WHERE ...
-- natural join就是在组合的基础上自动用了一个过滤,要求table所有相同名字的列的值都相同
outer join:
Left Outer join:
A LEFT OUTER JOIN B ON cond 如果cond满足的话,得到的是AB的组合(一行有A的列+B的列);如果不满足,得到A的列+空
Right Outer Join 同理
Full Outer Join 同理 例如ON A.id = B.id
如果有A没有对应的B, 那就是是 A + 空
如果有B没有对应的A, 那就是 空 + B
非常好的图
alias
简化 + 看起来更清楚(尤其是self-join)
FROM TABLE1 AS x, TABLE1 AS y
String Comp
LIKE或者正则S.name ~ '^B.*' (等效于S.name LIKE 'B_%')
AND OR 做条件交并
EXCEPT UNION (ALL) INTERSECT做子查询结果集合的交并差
IN EXISTS用于子查询 (NOT IN, NOT EXIST) EXISTS是判空
SELECT S.sname FROM Sailors S WHERE S.sid IN
(SELECT R.sid FROM Reserves R WHERE R.bid=102)
还有ANY ALL
ARGMAX?
SELECT * FROM Sailors S WHERE
S.rating >= ALL
(SELECT S2.rating FROM Sailors S2)
View: Named Queries
CREATE VIEW xxx
AS ...
SELECT * FROM xxx;
cache and reuse
或者
WITH [viewname] AS [statement]创建一个临时view
NULL 参与的运算大多是NULL, 除了IS NULL,False AND NULL这种
lec3
Disk & Buffer
整体架构
SQL client-> Query Parsing & Optimization->Relational Operators-> Files and Index Management->Buffer Management->Disk Space Management
Concurrency Control & Recovery
磁盘太慢,需要尽量减少读写,且寻道和旋转时间是大头
"block" && "page": 一个意思,磁盘上的块状读写最小单元 一般64KB-128KB
为了重用硬件驱动,经常会将磁盘空间管理器建立在文件系统API上,但带来了一些大数据库多文件系统的问题,也有直接建立在设备上的,更快但是移植性问题
给上层的抽象是一个巨大的文件
DB file: page的集合,每个page又包含了许多records
给上层提供:CRUD on records
record解构成一个"指针" {pageID, location on page}
structures
- Unordered Heap Files(和数据结构heap没啥关系,无序records)
- Clustered Heap Files
- Sorted Files
- Index Files
如何组织page呢?
链表? 想想就知道效率很差
类似目录的形式? 部分page只存到其他page的指针,并且始终放在缓存之中
page解构
Page Header:
- Number of records
- Free space
- Mayba a last/next pointer
- Bitmaps, slot table
record 中间留不留空?
不留空:Fixed Length Records, Packed
header后面跟紧密定长records, 因此可以有 record id = {pageId, record number in page}, 简单运算得到location
加很简单,直接append
删,全移一遍?->O(N),自然想到能不能lazy delete或者soft delete
方法是在header里面放一个delete bit的bitmap
变长?
slotted page
将信息存在footer(称为slot directory), record从头部开始存
由record id得到dir中位置,位置里面是pointer + length,
删,将slot dir中的项置空
插入,插在空位上,更新slot dir
fragmentation?
什么时候reorganize?->设计取舍,大部分时候没有那么多删除(乐)
slot不够->从page尾部向前增长
lec4
cost model for ayalysis
B, D, R
- the number of data blocks
- the number of records per clock
- avg time to r/w disk block
- opt: index
indexes:
大幅度降低range操作耗时
An index is data structure that enables fast lookup and modification of data entries by search key
区间查找 & 子集搜索, 可以复合, 不需要唯一
2-d box 2-d circle n-d indexes都有
kd树啊R树啊
postgres 的 GiST index
left key opt: 最小的key是不需要的,直接拿-inf当下界就行
处理相等:>= 向右走就行
B+树
-
叶子不一定是连续的-动态分配,指针连接以支持range scan
-
阶数d, fan-out 2d+1 典型的fan-out 为2144()
-
删除, 理论上来说, 可能涉及到重新平衡等操作 但实际的操作之中, 只需要删除即可, 原因是平衡太慢了,并且删了也能再插
叶子放什么?
- 数据
pros:
- 快
cons:
- 想要在另一列构建索引�只能重新复制文件(文件只能按照一种方式实际排序存储)
- 即使真复制了,同步问题也很寄
- 指向数据的指针 (key, page id+list of record id)
在b+树里面有重复项
- 指向同一个键的所有records (key, list of (page id + list of record id))
减少冗余,增加复杂性
clustered: index指向的数据块在磁盘上是按照这个index排序或者近似排序的
非常大影响性能 顺序比随机快100倍
对于一个有变化的数据,例如插入或者删除,需要一些成本进行磁盘数据的重新排序来维持clustered
B+树的平衡性:
使用字节数半满(占页面容量)就行, 甚至实际上更低, 按照实际性能来决定,不严格
变长key: 前缀压缩 trie
性能的常数:
由于顺序读写比随机读写快100倍
B+树比全表扫描差不多也是涉及到1%以下的表才有显著优势
所以例如对一个非聚簇索引进行一个跨越半个表的range的扫描, 那还不如直接把全表取出来
优化
由于B+树效率真的很低,所以有很多优化策略
- bulk loading 批量装载
- Sort the data by a key.
- Fill leaf pages up to size f (the fill factor).
- If the leaf page overflows, then use the insertion split algorithm from a normal B+ tree.
- Adjust pointers to reflect new nodes if needed.