从微调reranker到搜推工程实践
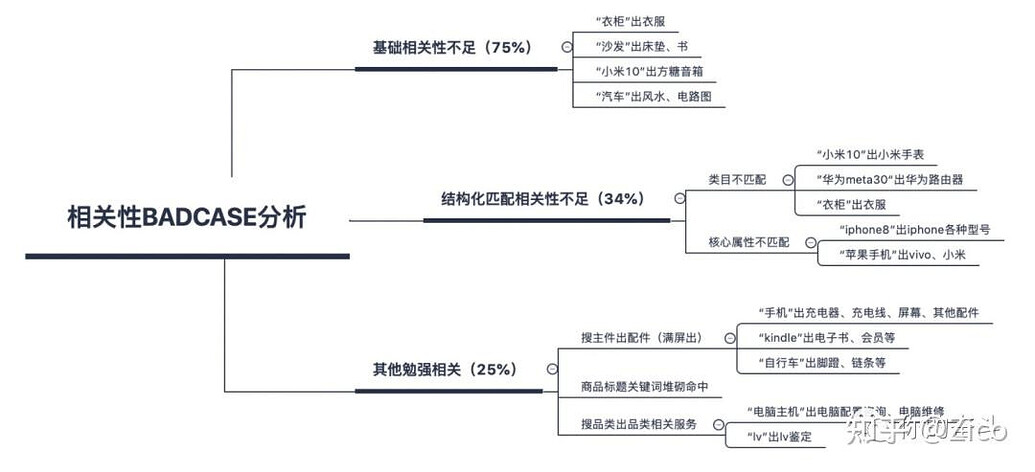
如何进行reranker微调?
之前我曾经花了一定时间找这个问题的经验,结果发现大部分reranker�模型对于这个问题是一个回避状态,不愿意开源自己的训练集,更不提像OpenAI/Cohere的rerank/embed服务本身就在卖钱,而兜售rag解决方案的公司,更不肯将如何做领域适配这一赚钱核心逻辑公之于众
也就BAAI以一个非常开放的态度,公开了自己的微调方法和相关脚本和训练数据,但他们也更侧重与如何训练一个通用的模型,对于怎么微调,只知道构造正负样本,query,pos,neg,然后InfoNCE,至于为什么能work,pos/neg怎么选,可能觉得大家都知道,也没有多说
而兜兜转转的楼主最后在传统搜推里面找到了一整套硬负例挖掘方面的方案,rag整套方案其实都是抄搜推的一个劣化版本罢了 🤣
为什么采用的是正负对而不是交叉熵或者其他有label的损失?核心在于,搜推本身就是一个弱label的场景
乍一想,在有正负对的情况下的时候,交叉熵似乎也很自然,以01为例,两种损失项就是 ? 但一个随之而来的问题是哪来的01 label?
也就是说,这样做的前提是label的准确性,而在搜推场景中,负样本 的一个设置是曝光过但没被user选择的真负样本
但召回层的大部分样本根本没被曝光过,label噪声很大(召回层是一个几亿->几千->几十条的过程,只有最后的几十被曝光了),如果只依赖这样的负样本的话,根本无法支撑模型训练。所以正负样本的设计某种意义上是无奈之举,我无法知道这个样本和用户的真实关系,但我可以从用户的行为中得到一些偏好信号,召回算法往往采用Pairwise LearningToRank (LTR),建模排序的相对准确性,模型的优化目标变成正样本匹配度高于负样本匹配度
现在我们知道了为什么采用正负样本,但真正上手就会发现,正负样本这一件事并没有想象中的简单。
如果你采用随机的语料作为负样本,带来的一个问题是这个负样本对模型太easy了,模型只能区分猫和狗,但无法区分哈士奇和狼狗,即忽视了细节信息,也即是我们所说的rag的领域细节的缺失
而解决的方法,也在搜推里面早就提出了,硬负样本挖掘,即设置一部分的硬负样本,这部分是有难度的,来迫使模型学会根据细节进行区分
而在rag里面大家常常是拍脑门的硬负样本设计,让reranker带上一些业务目标,在搜推里面也早是被玩烂的东西了。
先说业务目标: 比起rag中,大部分的应用还局限在文本相似度,搜推早就进入到多个因素的融合和全链路目标指向的优化,例如,很多搜推业务需要考虑地域性(如外卖,酒店等),于是其正负样本会这样设计: 有基于业务逻辑的,核心是增强某个指标的相似性,让模型考虑其他指标做出区分,以房屋销售为例
- 增加与正样本同城的房间作为负样本,增强了正负样本在地域上的相似性,加大了模型的学习难度
- 增加“被房主拒绝”作为负样本,增强了正负样本在“匹配用户兴趣爱好”上的相似性,加大了模型的学习难度
针对模型只学地域特征信息就可以进行打分的easy neg,设计了同城的hard neg强迫考虑其他特征
绝大部分负样本还是随机采样生成的。但是,Airbnb发现,用户点击序列中的listing多是同城的,导致正样本多是同城listing组成,而随机采样的负样本多是异地的,这其中存在的bias容易让模型只关注“地域”这个粗粒度特征。
为此,Airbnb在全局随机采样生成的负样本之外,还在与中心listing同城的listing中随机采样一部分listing作为hard negative,以促使模型能够关注除“地域”外的更多其他细节。
在电商场景下,负样本的业务构造也有很多:
- 正样本:充足曝光下高点击ctr样本(如:ctr大于同query下商品点击率平均值)
- 负样本:
- 同父类目的邻居子类目负采样。
- 高曝光低点击类目样本:同一个query搜索下,根据全局点击商品的类目分布,取相对超低频类目样本作为负样本。
- 充足曝光情况下,低于相应query平均曝光点击率一定百分比的样本做负样本。
- 基于query核心term替换构造负样本:如,对于“品牌A+品类”结构的Query,使用“品牌B+品类”结构的query��做其负样本。(这个lz当时在propilot构造领域词替换负样本的时候还觉得自己想到了个好方法,后来发现是早有之事)
- 随机构造负样本:为增加随机性,该部分实现可在训练时使用同batch中其他样本做负样本,同时也可以引入经典的Hard Sample机制。(这部分涉及到很有趣的一个问题,后面讲)
不局限于业务,搜推还对RAG很少涉及的“如何选择hard neg”上面有非常久远的研究,如
-
高置信样本挖掘,避免搜索点击行为日志“点击但不相关”的问题。
-
**定制化的负样本构造,避免模型收敛过快,**只能判断简单语义相关性,对难样本无法很好的区分。
-
关于短文本的定制化需求, 如美团提到的他们实践的一些难Case,“大提琴”→“小提琴”以及“葡萄酒”→“葡萄”这类字面编辑距离小的case,会根据搜索结果做分析,以搜索无结果作为bad case进行负样本生成
-
知识图谱也是被玩烂的东西
-
图结构也是被玩烂的东西,如在Pinterest中,基于GCN的PinSAGE
和Airbnb一样,我们可以认为被同一个user消费过的两个item是相似的,但是这样的排列组合太多了。
为此,PinSAGE采用随机游走的方式进行采样:在原始的user-item二部图上,以某个item作为起点,进行一次二步游走(item→user→item),首尾两端的item构成一条边。将以上二步游走反复进行��多次,就构成了item-item同构图。
在这个新构建出来的item-item同构图上,每条边连接的两个item,因为被同一个user消费过,所以是相似的,构成了训练中的正样本。
- 在训练开始前,
- 从item-item图上的某个节点u,随机游走若干次。
- 游走过程中遍历到的每个节点v,都被赋予一个分数L1-normalized visit count=该节点被访问到的次数 / 随机游走的总步数。
- 这个分数,被视为节点v针对节点u的重要性,即所谓的Personal PageRank(PPR)。
- 训练过程中
- 针对item-item同构图上的某一条边u→v,u和v就构成了一条正样本,它们的embedding应该相近
- 在图上所有节点中随机采样一部分ne,u和每个ne就构成了一条负样本,它们的embedding应该比较远。因为是随机采样得到的,所以ne是easy negative。
- 除此之外,还将u所有的邻居,按照它们对u的重要性(PPR)从大到小排序,筛选出排名居中(e.g.论文中是2000~5000名)的那些item。这些item与u有几分相似,但是相似性又没那么强,从中再抽样一批item,作为"u"的hard negative。
....
- 利用传统nlp思路的
在airbnb中,用户的点击序列,如果用类似word2vec+窗口的想法看成是一个“共现”问题的话,用户点击序列中的项的不像语言那样有一个很明显的长程衰减,embedding都应该是相近的。 但这样的组合太多,所以回退到窗口的方式,拿中心项和邻居项组成正样本对。但因为最后一次下单的点击有最强的业务信号,所以拿它和整个序列的每一项组成正样本对,“增加final booked listing作为global context加入每个滑窗”
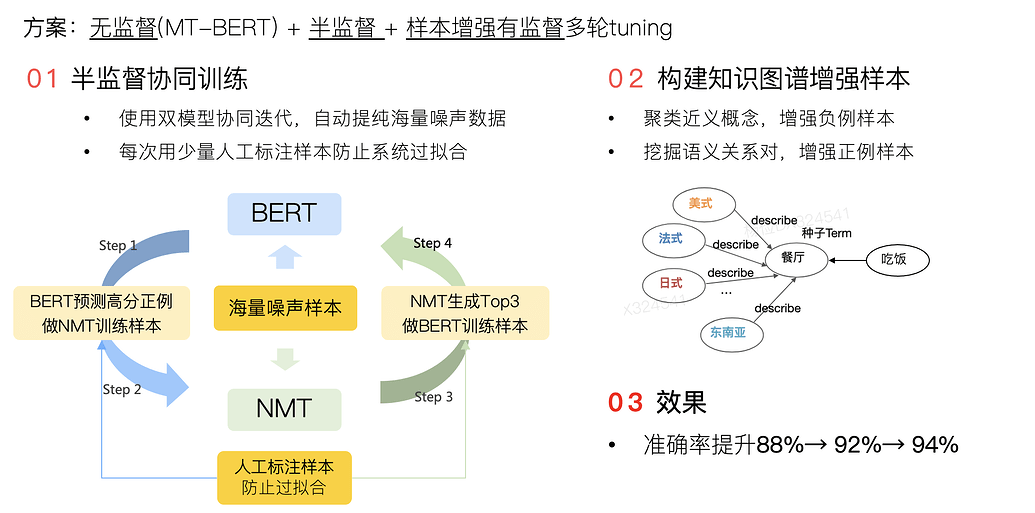
解决了如何构��造硬负样本的问题,那应该选择多少硬负样本呢?如果自己跑过reranker的微调就会知道,过高的硬负样本比例甚至会让模型崩掉。而更是有拿调reranker的数据集拿来调embedder的神人(没错,就是我自己),BAAI官方的脚本中,这俩也没啥区别 🤣
然而,早在N年前Facebook的文章中,就给出了他们的经验教训
- 将比例维持在easy:hard=100:1
- 将rerank的数据拿来训embed(在搜推场景中是拿曝光未点击数据(rerank前列但未收到信号)来当召回(embed)的负样本)是完全错误的实践,离线数据可能不错但一上线就是一坨
这是为什么呢?因为召回不同于排序,在rag层要处理的文档没有那么多可能无感知,很多rag甚至没有排序层拿召回当排序,先下结论
如果说排序是特征的艺术,那么召回就是样本的艺术,特别是负样本的艺术。样本选择错了,那么上述的模型设计、特征工程,只能是南辕北辙,做得越卖力,错得越离谱。


明白了这个数据分布的区别之后,就会对前面硬负样本和简单样本的比例在不同阶段是不同的这一个特点有更深的理解,对于召回而言
hard negative并非要替代easy negative,而是easy negative的补充。在数量上,负样本还是以easy negative为主,文章中经验是将比例维持在easy:hard=100:1。毕竟线上召回时,库里绝大多数的物料是与用户八杆子打不着的easy negative,保证easy negative的数量优势,才能hold住模型的及格线。
所以,全样本随机采样的负例才会很重要
而推荐甚至走的更远好几步,例如,随机采样不等于等概率采样,推荐系统中会出现放大的效应,即热门的样本会更容易被点击,进而各种指标特征表现更高,变得更热门,为了不然模型退化到只推荐一类样本,在实践之中会对热门正样本降采样,对热门负样本升采样
还有对硬负样本带来的左脚踩右脚
当业务逻辑没有那么明显的信号的时候,就需要依赖模型自己挖掘, 都是用上一版本的召回模型筛选出没那么相似的对,作为额外负样本,训练下一版本召回模型。怎么定义“没那么相似”?文章中是拿召回位置在101~500上的物料
Q: 这样选择出来的hard negative已经被当前模型判断为“没那么相似”了,那拿它们作为负样本训练模型,还能提供额外信息吗 A: 上一版本中,这批样本只是相似度靠后,现在直接划为负样本,能更迫使模型进行区分
而rag在玩的全链路RL优化,是推荐系统几年前玩了一波后来又扔到垃圾桶的东西 🤣性能不稳定,模拟和实测差距大,等等问题
包括现在在rag系统的reranker中还未广泛见到的刷点技巧,对不同难度级别的负例单独训小模型,然后做embedding融合
在工程性上,RAG的路也更像是把所有搜推的路再走一遍,
-
如何解决冷启动问题?搜推已经证明了LR,FM这种一二阶特征就能得到一个不错的基线,并且可以将实数特征离散化,排0存储,排0计算进行O(N^2)到O(N)再二值化化乘为加得到在线级别的性能(用户每一次交互都是一次特征计算)
-
如何解决系统效率问题?网络上参数服务器+只传递特征id,实数特征的分桶离散化,特征的Field级别合并减少NN的维度,log的一套大数据系统+redis冷热缓存+bloomfilter+......
-
如何解决模型性能问题?在召回层禁止特征交叉,在排序层卷一系列现代架构,根据短文本特点进行深度语义层的裁剪,量化和蒸馏
-
如何解决可解释性问题?用加权的ML模型做基线,bad case定位和迭代,先把神经网络丢一边......
-
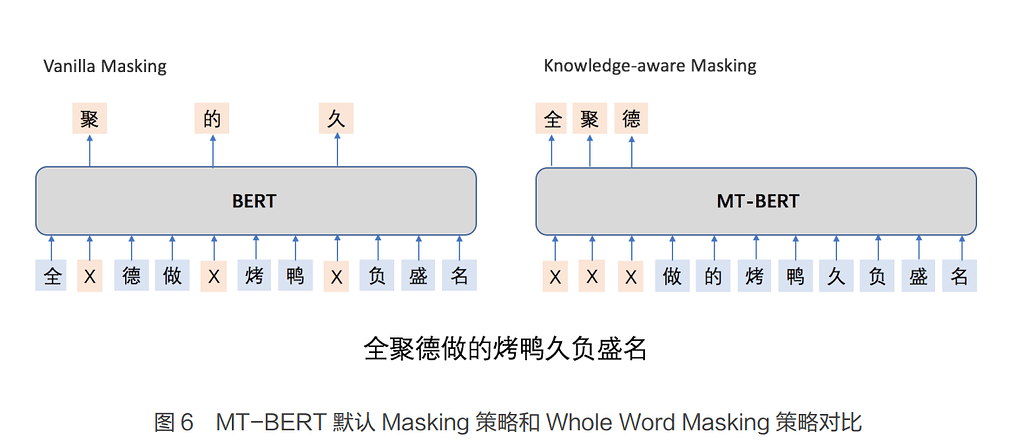
意图识别?训练NER任务,对查询做成分识别,丢掉不重要的词,在少无结果的时候做多级检索,甚至能把时延卷到10ms量级。BERT结合KG做领域词级别的mask而不是字符级别的mask,来达到对整个实体级别语义的理解效果
-
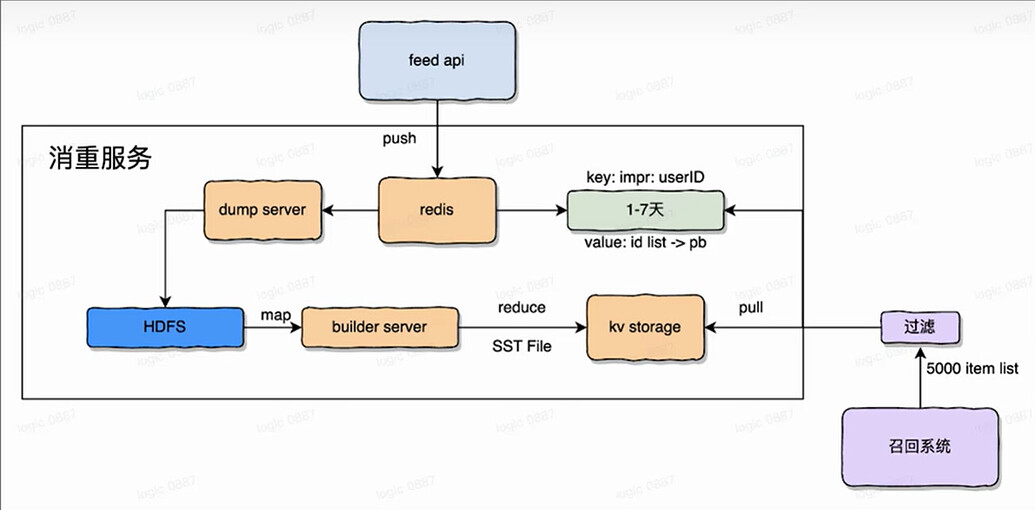
多样性?召回通道的消重系统
-
商业化?精排的广告插入......
-
规模化? 一键训推平台,业务算法提交数据后集群分卡自动运行和效果验证
-
稀疏样本?酒店这种看重订单率而不是相关性的就是最好的参考实践

现在传统RAG发现一个问题就是半结构化数据很难被embedding模型处理,但如果从这个角度反向想回去的话,搜推一直就是在处理结构化数据啊,还是走同一套特征离散化的逻辑,后面做Pooling�和特征融合又可以复用各种实践,
- 普通的Mean/Max Pooling,代表算法YoutubeNet,先embedding再pooling
- Neural FM中,让属于同一field的feature embedding两两交叉,完成所谓的Bi-Interaction Pooling
- 加权平均 - Attention, 阿里Deep Intereset Network (DIN),计算candidate item和用户各历史item的attention score,再根据这个score加权历史item的embedding,表示用户的历史偏好,使得用户的向量表达随着不同的candidate变化
- 加权+时序,DIEN
所以,我们真的需要一个劣化的RAG系统吗?很多时候只是我们维护不起一套完整的搜推系统罢了,没有人力和体系力量去维护一个结构化的数据组,AB test和实时的线上反馈,又不在意系统的时延,吹嘘着LLM神话,消耗着大量的token,最后效果也就那样,还得根据线上信号进行优化,做来做去发现前人早就做过了(笑)。
但是anyway,如果你需要做点rag的话,搜推这边的方法可能需要大规模人力物力不一定能用得上,但这边踩过的坑,再踩一次就是猪头了,也算是理解了为啥网上有做搜推的转RAG讲说从LLM转过来的完全不理解上线难点在哪里,会踩很多坑,或者永远停留在离线的状态