稀疏神经嵌入
下午在看milvus文档的时候看到着重提了稀疏检索,注意到bge-m3是有神经稀疏检索的支持的,于是学习了一下,下��面属于纯入门笔记。
https://bge-model.com/bge/bge_m3.html

和传统的BM25等稀疏嵌入不同,bge-m3的稀疏嵌入是基于模型的,复用密集嵌入的前面层
BGE-M3 实现的是一种**“learned sparse embedding”(神经稀疏语义嵌入**)。与 SPLADE、uniCOIL 这类模型类似,这些都是让模型自适应学习每个 token 某种“匹配权重”,在大规模预训练和下游 fine-tune 时引入了专门的稀疏激活目标,使输出稀疏且有用

SPLADE 模型的全称为"Sparse Lexical and Expansion Model"(稀疏词法和扩展模型),结合了传统稀疏向量检索的优点和神经网络的语义理解能力。

BERT 的 MLM 头部会为每个输入位置计算对词汇表中每个词元的贡献分数。这些分数反映了当前上下文下,特定词元与其他词元的关联强度。
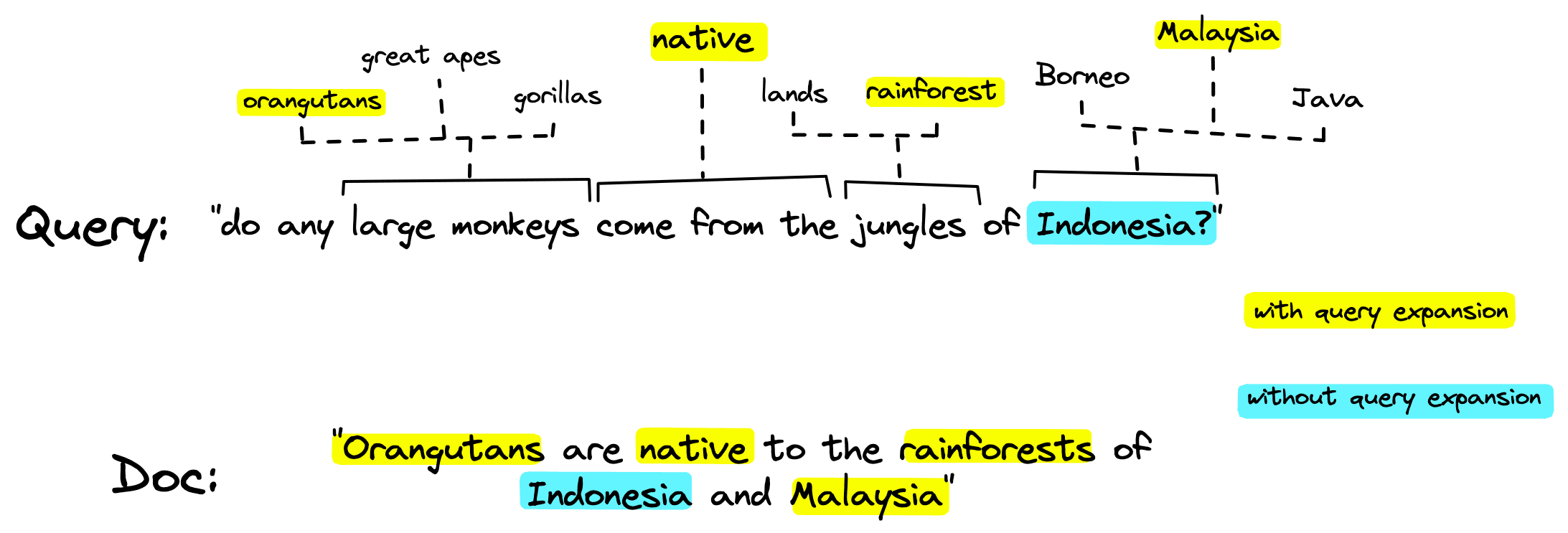
也就是说,这个方法实际处理了三个问题:
- 词表不够大(或者分词精度不够)的问题,采用预训练BERT的词表和分词器,可以随着预训练模型的拓展而拓展;
- 针对传统稀疏编码需要精确词匹配、编码值实际上都是离散变化的问题,采用遍历整个词表,利用BERT的mask-预测概率,计算将原始句子的每一个词与词汇表中其他词的关联强度,对应logits即为,从而实现了词汇的拓展,允许相关词、近义词匹配等
- 针对传统BM25中没有上下文位置关系的问题,利用BERT的位置编码和捕获双向信息的预测,将传统手工设计特征的部分取代
还有一些其他的操作比如稀疏化,用于提供较密集嵌入更强的筛选能力
SPLADE 使用 ReLU 激活和 MAX 池�化操作来确保生成稀疏向量。ReLU 将负值置为零,增加稀疏性;MAX 池化则为每个词元选择所有位置中的最大贡献值,进一步增强了稀疏性 1。
此外,SPLADE 还使用正则化(如 FLOPS 正则化)来控制稀疏性程度:
L_FLOPS = λ * ||q_splade||_1 * ||d_splade||_1
这个正则化项通过惩罚向量的 L1 范数(非零元素的绝对值和)来鼓励模型生成更稀疏的向量
还有一个问题是:这个“关联强度"是什么?
从模型的角度说,这个关联强度向量就是BERT的嵌入再过一个MLP得到(vocab_size, )的向量
但实际上,这里并没有直接使用BERT的mask预测权重,而是针对信息检索进行了微调(使用MS MARCO数据集,100万条搜索引擎搜索数据)

最后的损失函数是三者的加权组合
目前SPLADE稀疏向量的召回率已经显著由于BM25传统搜索引擎的召回率

但是BM25等传统方法就完全不行了吗?也未必,有文章指出SPLADE这样的基于模型的方法始终会受到预训练语料的领域限制,并且在垂域少量数据上训练/微调的成本开销都比较大,此时未必有简单的BM25 + 领域定制词典权重好
而作为召回的一道路径来说,还有许多额外的召回规则,例如通配符和前缀,编辑距离和短语......
很fashion的reranker https://www.mixedbread.com/blog/mxbai-rerank-v2
双模搜索:https://www.mixedbread.com/blog/the-hidden-ceiling
做了一系列实验证明了OCR质量在RAG系统中的重要性和目前的OCR方法质量的局限性,多模态生成用于检索的编码,OCR生成嵌入:检索时用能理解文本布局、复杂图表的多模态嵌入,而进入LLM的时候用OCR生成的文本
- 他们也实验了使用图片/嵌入直接进视觉LLM,但效果不佳。提出的观点是LLM能够容忍文本的噪声和解析错误(文字质量下降),但不太能容忍精致且无关的文本(搜索质量下降),在传统rag流程中,OCR质量下降会直接导致搜索质量下降