context-engineering
rag那边最近看到的新的概念,现在prompt工程不叫prompt工程了,叫上下文工程 (context engineering),笑
上下文工程概念的兴起主要是两个方面,一是更关注多轮和工具,prompt无法很好地概括这些部分,二是模型的能力并不能做到和声称的上下文一样(支持1M长度的模型,可能长度超过32K指标就会严重下滑)
上下文失败的几种情况,参考 How Long Contexts Fail | Drew Breunig
- 上下文中毒: 幻觉和错误进入上下文,并反复引用,这个主要来源于google在用智能体玩游戏时出现的一些现象(超长程规划)
An especially egregious form of this issue can take place with “context poisoning” – where many parts of the context (goals, summary) are “poisoned” with misinformation about the game state, which can often take a very long time to undo. As a result, the model can become fixated on achieving impossible or irrelevant goals.
- 上下文干扰 & 混淆 上下文干扰是指上下文变得太长,以致模型过度关注上下文,而忽略了在训练期间学到的内容。
The Berkeley Function-Calling Leaderboard is a tool-use benchmark that evaluates the ability of models to effectively use tools to respond to prompts. Now on its 3rd version, the leaderboard shows that every model performs worse when provided with more than one tool4. Further, the Berkeley team, “designed scenarios where none of the provided functions are relevant…we expect the model’s output to be no function call.” Yet, all models will occasionally call tools that aren’t relevant.
随着模型变小,问题变得越来越严重
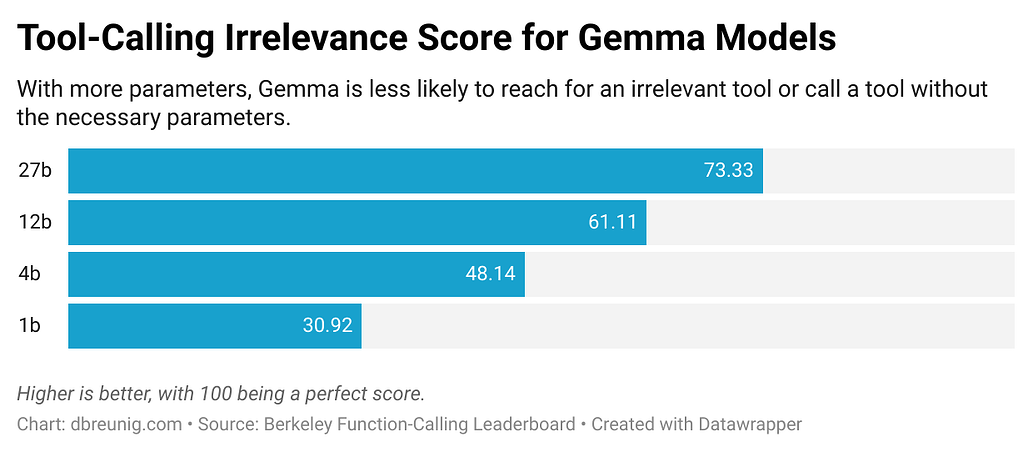
问题是:如果你把某些东西放入上下文中, 模型就必须注意它。 它可能是无关的信息或不必要的工具定义,但模型会将其考虑在内。大型模型,尤其是推理模型,在忽略或丢弃多余上下文方面做得越来越好,但我们仍然看到无用的信息绊倒了智能体
关于信息之间和信息与问题的交互,google和其他机构都有不少的research paper,现在广泛认为,信息自己有几个“原子事实”不太重要,但信息之间的的一致性和独立性(相互cover不同部分以从根本解决信息冲突的问题)以及信息和query的相关性很重要
- 上下文冲突 A Microsoft and Salesforce team documented this brilliantly in a recent paper.
分阶段提供信息,模型的表现严重下降
We find that LLMs often make assumptions in early turns and prematurely attempt to generate final solutions, on which they overly rely. In simpler terms, we discover that when LLMs take a wrong turn in a conversation, they get lost and do not recover. 我们发现,LLM 们经常在早期阶段做出假设,并过早地尝试得出最终解决方案,而他们过度依赖这些解决方案。简而言之,我们发现,当 LLM 们在对话中走错方向时,他们会迷失方向,无法恢复。
Andrew Karpathy依然擅长炒作,他的观点是LLM as a new OS. Context is RAM
上下文工程:在上下文窗口中为下一步填充恰到好处的信息的科学
有哪些呢?
- Instructions
- Knowledge
- Tools
上下文工程策略:写入上下文,选择上下文,压缩上下文,隔离上下文
写入上下文:
- 临时笔记板,可以是会话的状态对象,也可以是简单的工具调用写文件 Anthropic 的研究表明,将“笔记板”工具与特定领域的提示配对使用可以带来显著的收益,与专业代理的基准相比,最高可提高 54%。这也称作上下文卸载(Context Offload), 参考 The "think" tool: Enabling Claude to stop and think \ Anthropic
Anthropic identified three scenarios where the context offloading pattern is useful: Anthropic 确定了上下文卸载模式有用的三种场景:
Tool output analysis. When Claude needs to carefully process the output of previous tool calls before acting and might need to backtrack in its approach; Policy-heavy environments. When Claude needs to follow detailed guidelines and verify compliance; and Sequential decision making. When each action builds on previous ones and mistakes are costly (often found in multi-step domains).
- 记忆:跨模型、跨会话,独立存储。Reflexion + 定期整理记忆
选择上下文:
- 记忆选择:Langchain将记忆归为几种类别:Semantic, Episodic, Procedural 对应 Facts,Experiences和Instructions,一个挑战是选择相关记忆。Claude Code使用CLAUDE.md,Cursor和Windsurf使用规则文件
- 工具管理:例如对工具list用RAG,这个在现在的MCP中很多都在尝试,比如OSPP就有这样的项目
压缩上下文:Claude Code当交互占用超过上下文的95%之后,会自动压缩,总结用户-Agent的完整轨迹。可以是递归或者分层摘要。也可以在一些特定点添加摘要(如某些工具调用),Cognition为此使用微调模型 上下文修剪:启发式删除旧信息,provence作为上下文修剪器
隔离上下文:
- 拆分到子Agent之间,OpenAI Swarm动机是关注点分离,一组Agent完成各自的子任务
- 工具代码沙箱
LangGraph & LangSmith
LangGraph 在记忆(状态)上面做了努力,选择 上下文也通过这个State获取,压缩上下文通过状态对象进行自定义逻辑,隔离通过子图和节点
LangGraph基于状态机的实现倒是暗合了OS=状态机的观点,从一个比较底层的视角上为各种上层应用提供了可能,也可以复用业界关于状态机的一系列优化已有实践
而关于上下文管理的评估侧,一个比较热门的评估和观测系统Galieo设置了四种指标来评估一个RAG应用: Adherence,Completness, Utilization,Attribution 对上文的忠实度,上文本身对解答这个问题的完整性,答案对于上文的利用度,答案对于不同chunk的归因
在它的博客之中,给了一个非常真知灼见的观点是,过多的指标本身没什么意义,它选择这四个指标的原因是能定位出是链路的哪一块出现了问题,这个指标也只有low, medium, high三级,不做复杂的打分,倒是有点像是推荐系统里面的分桶离散特征
例如,如果整体利用度低,但完整度高,那么冗余信息太多了,减少chunk size和输入LLM的chunk数量N;如果整体忠实度高,但完整度低,则需要考虑是搜索的问题(多样性考虑不够)还是数据的问题(根本就没有足够多的文档);而归因性可以用来调整chunk size,裁剪等参数;忠实度不够则主要从prompt和chunk数量入手......
与其他一切最终被广泛利用的策略相同,Galieo也蒸馏了一个小BERT来代替昂贵的LLM进行打分,以此提供一个本地托管的方案
另一个上下文管理的有趣的工作是直接进行暴力的token-level prompt压缩,来自微软的LLMLingua论文,其基于两个观察
- 自然语言有冗余
- 传统的信息熵指标只有单向上下文, 且与提示压缩指标不一致
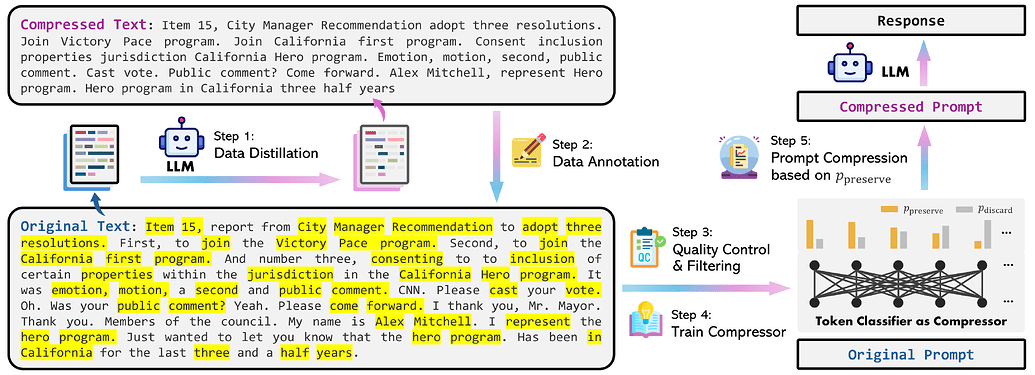 因此,开蒸!总之也是训了XLM-RoBERTa-large & mBERT的模型替代LLM(可以发现现在的RAG基本就是
因此,开蒸!总之也是训了XLM-RoBERTa-large & mBERT的模型替代LLM(可以发现现在的RAG基本就是 寻找问题-大模型蒸馏训练-用专业小模型代替-形成nlp管道的范式,在几�乎每一个组件都是如此,效果也好)