RocketMQ学习
mq: 异步,解耦,削峰填谷
传统项目架构下,对网络波动没有耐受性
mq多用于分布式系统间进行通信
请求方/响应方 -> 生产者/消费者
优劣
优势:异步,解耦,削峰填谷
- 解耦: 消费方存活与否不影响生产方
- 异步: 提速
- 削峰填谷(作为一个buffer/cache), 提升系统稳定性,应对突发性高并发冲击
例子-电子商务下单:
生产者: 订单系统 -> MQ -> 库存系统、支付系统、物流系统、大数据系统(用户数据收集)(复制与多分发)
生产者发完消息,可以继续下一步业务逻辑
订单系统不需要新增业务代码,达成解耦
同时,订单系统可以发MQ消息之后就返回。准确地说,MQ消息 + 订单入库(校验等)
劣势:
- 可用性降低: MQ宕机就寄,需要保证MQ的高可用
- 系统复杂度提高:消息丢失? 消息保序?重复消费?
- 一致性问题:多消费,部分成功,部分失败?下游失败怎么办?
市面主流MQ产品:
- ActiveMQ: 万级吞吐,主从架构,ms延迟,现在不怎么用
- RabbitMQ: erlang,us处理,万级吞吐,主从架构,较难维护
- RocketMQ: java,十万级吞吐,ms级,分布式
- kafka: scala, 十万级,ms级,分布式,功能比较少
rocketmq: 17年双十一,TPS 5600w
架构
生产者集群 Producer
消息服务器集群 Broker 接受消息,提供消息,消息持久化,过滤消息,高可用
消费者 Consumer
命名服务器集群 NameServer Cluster 存储元数据**�(Broker IPs)**
producer,broker,consumer向nameserver注册,nameserver用心跳确认其他组件的存活
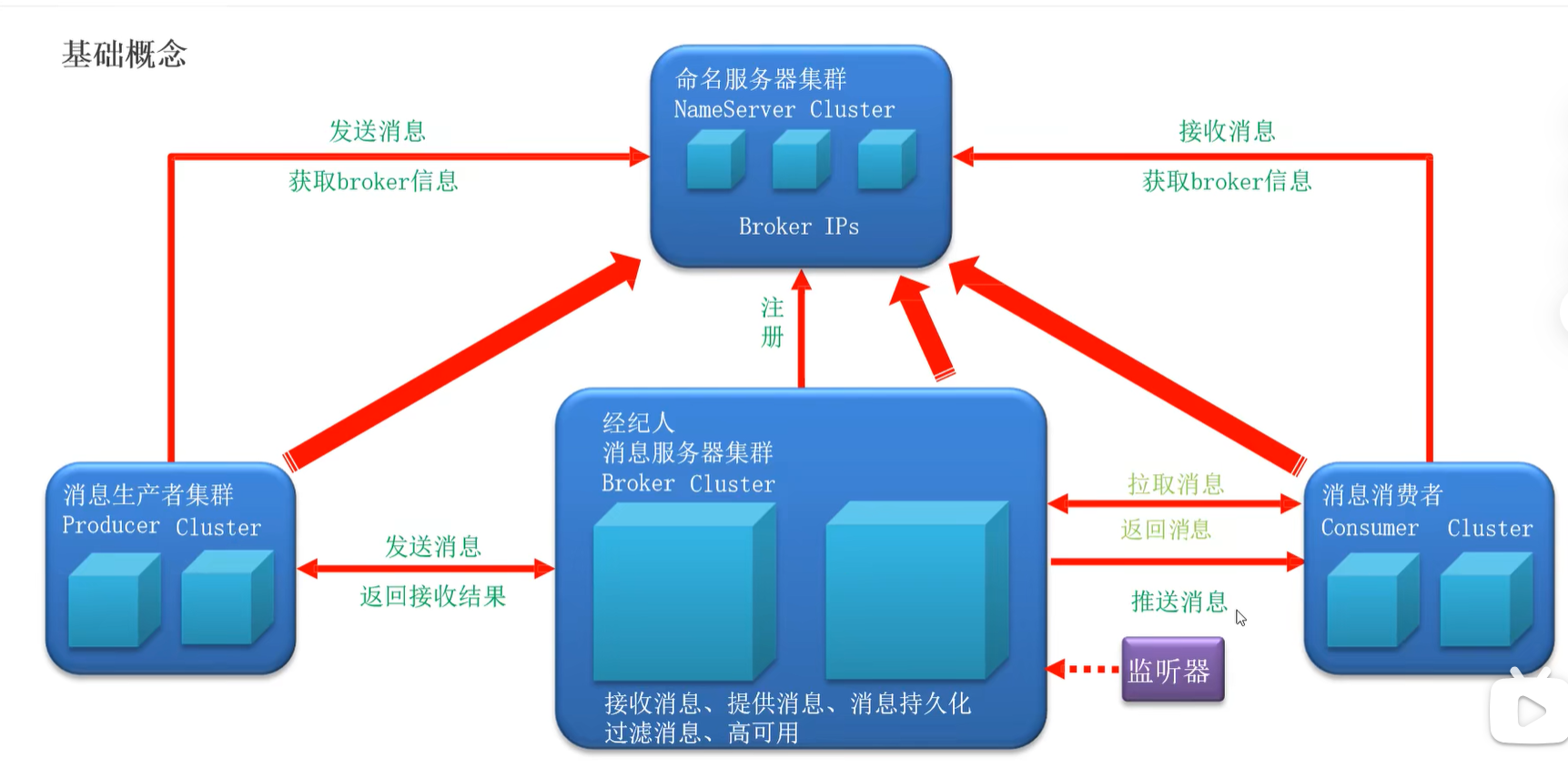
支持拉推两种模式,Consumer可以主动拉取,也可以用监听器模式
能推肯定是推省资源,免去轮询等
消息
- Message
- Topic 一级标题
- Tag 二级标题
基础流程:
Producer:
生产者创建 - 设置nameserver - 生产者启动 - 创建消息(指定topic,tag,内容)- 发送(获取结果)- 关闭生产者
发送结果是什么?主要是记录消息元数据例如消息ID的一个结构体,和Future那种设计不一样
Consumer
两类: DefaultLitePullConsumer 和 DefaultMQPushConsumer
对应拉取(额外线程轮询)和推送(长连接)模式
消费者创建 - 设置nameserver - 设置监听(订阅)主题 - 注册监听器(消息处理函数类,返回消息处理结果) - 消费者启动
设置监听的api rocketmq是这样设计的
subscribe(<topic>, <subExpression>)
这个subExpression通过通配符等支持,让api 表达力变强不少
- 支持tag过滤
- 支持sql过滤,在给消息追加属性的时候很有用
><=BETWEENINIS NULLANDORNOT
OneToMany 多消费
多个消费者监听一个topic的默认行为:
- 一条消息只会被消费一次
- 多个消费者之间有默认的负载均衡
如果想要多个消费者都消费这条消息呢?例如上面的电商情况
- 消费者组 consumer group概念
相同组的消费者,有负载均衡,单消费
- 也可以修改消息模式,将默认的消费模式改掉
CLUSTERING -> BROADCASTING
单条消息会被复制数份,发送到每一个消费者组
- “复制”是指HTTP传数次,不是存储文件复制
消息类型
同步:即时性强、必须有回执,例如短信通知
异步:即时性弱,也需要有回执,如订单信息
单向:不需要有回执,如写日志
- eg 分布式日志系统,所有Producer只管发
直接send(msg) 是发同步消息
send(msg, callback)是异步,等有结果再做处理
sendOneway是单向
延时消息
早期: v4.x
只支持不同的delayLevel,固定的1s 1m这样的时间
- 固定级别的延时消息实现简单,为每个延时类别创建单独的队列来管理, 采用内部特定主题(SCHEDULE_TOPIC_XXXX)和队列来实现延时功能
- 可能是简单的分队列定时扫描算法
后来:v5+
任意毫秒级时间戳延时,需要高效时间轮算法, 每条消息单独计时器跟踪
-
时间轮算法:小时轮,分钟轮,秒钟轮。将消息“填入时间轮槽”(即每个槽是一个
TaskList)- 层级时间轮,如果一个任务是1分30s, 会先被放入1分的分钟轮,处理到时,减去1分,降级放入秒钟轮
-
将时间线分割成多个区间,不同区间采用不同精度的扫描策略, 近期消息采用高精度扫描,远期消息采用低频率扫描
-
高效索引,分布式时钟对齐.....
批量消息
底层支持直接传 Collection<Message>
注意:
- 相同的topic
- 不能是延时消息
- 总长度不超过4M (IBM默认最大消息长度设置,可以通过改环境变量修改,但4M算是一个实验值)
- 相同的waitStoreMsgOK
Spring IoC集成
直接在配置文件中指定name-server, producer group之类
类似Kafka/Redis, RocketMQTemplate 链接管理
convertAndSend 方法
convert? Spring的Template send发送的是抽象的message,只有一个byte[]的payload,convert就是在处理上层java类与下层不同的template需要的通信格式的转换
消费者也是和Kafka类似的
@Service的类 implements RocketMQListener<MessageType> 就行, @RocketMQListener(topic=, tag=,consumerGroup=, selctorExpression=, selectorType=, messageModal=)
然后这个类就作为监听类了,调用的方法就是重载方法onMessage(T t)
(这里Spring顺带还做了个返回值处理,只要没抛异常都是消费成功,抛异常消费失败回传)
其他的机制也整合了,例如同步异步单向延时批量之类对应syncSend, asyncSend, ...
消息保序
消息错乱的原因,队列内有序,队列外无序
要做多队列的负载均衡,就不能无开销严格保证顺序
一连串的消息需要作为一个不能被拆分到多个负载均衡队列的整体
- 一个实现
messagequeueSelector的实体类,例如id hash + 取模
事务消息(无丢)
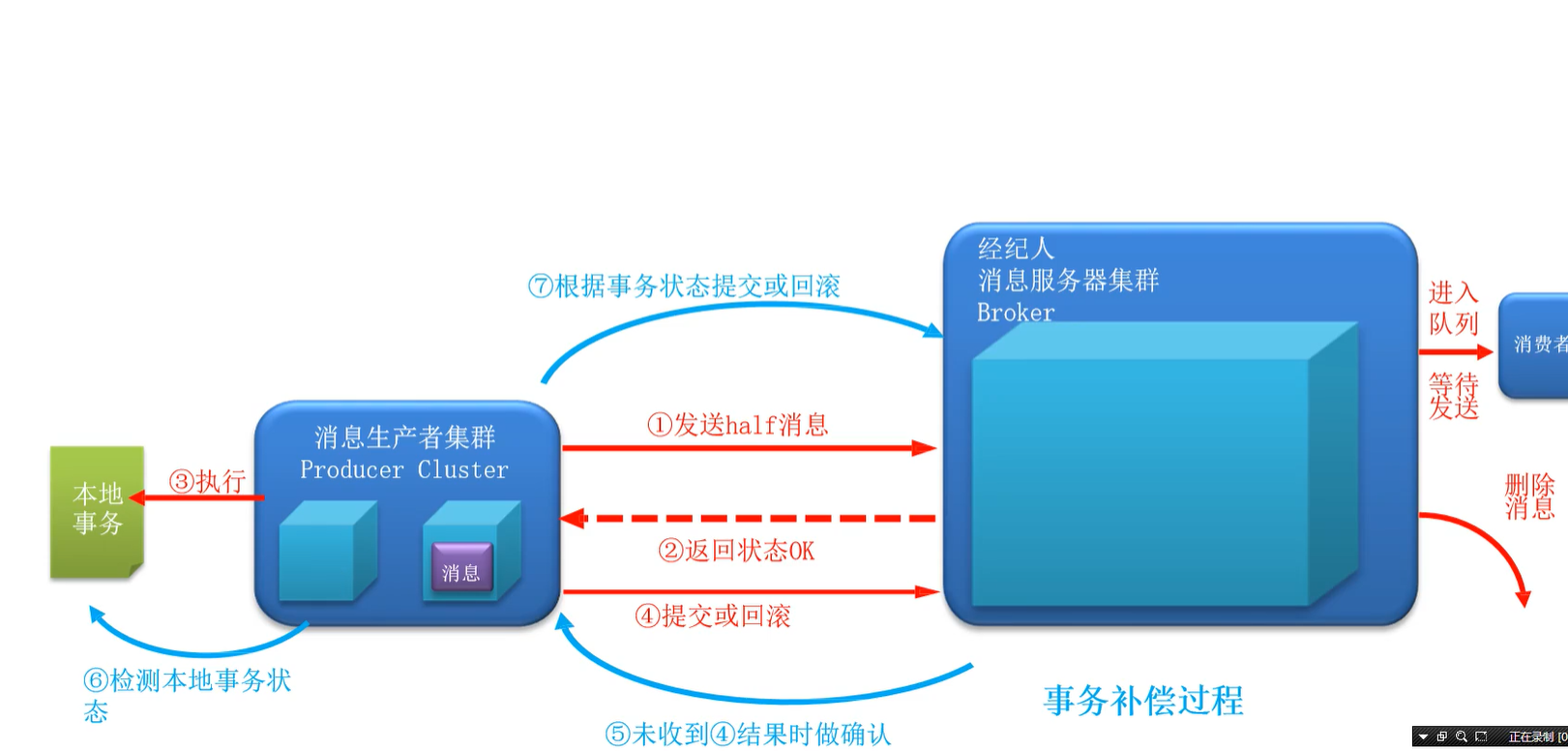
本地事务:如入本地数据库
事务状态:
- 提交状态,允许进入队列
- 回滚状态,不允许进入队列,当作没发生过
- 中间状态,未对half做二次确认
代码实现
TransactionMQProducer
setTransactionListener: 正常事务过程, 补偿过程
executeLocalTransaction: 正常事务,入库等,根据本地事务状态返回消息状态checkLocalTransaction:在正常事务超时等情况(实际上是正常事务函数返回了UNKNOW状态)时被调用,本地再次查询事务状态的函数
事务补偿还是UNKNOW?写个log或者其他人工介入方式
集群搭建
多broker:
多master多slave架构
master slave同步消息的方式可以是同步(生产者阻塞请求)也可以是异步(不阻塞)
常见:一主三从
- 只有brokerId为0的是主节点
- brokerName是集群名
每一个broker会向所有的nameserver注册

高级特性
消息存储
一次完整的消费需要两个ACK
即Producer向Broker发消息,Broker返回ACK
Broker向Consumer发消息,Consumer返回ACK
但如果中间Broker宕机,就会出现重复消费
例如,在Broker返回ACK之前宕机,Producer就可能再发一次消息;在Consumer返回ACK之前宕机,Broker就可能再发一次消息。
解决方案是,在Broker返回Producer ACK之前,先将消息存储到磁盘上持久化(数据库中),在接收到Consumer ACK之后,Broker删除这一条消息
- 如果在返回Producer ACK之前宕机,能从磁盘读消息避免重发
- 如果在Consumer返回ACK之前宕�机,也是同理
消息的存储介质
使用数据库:
- ActiveMQ:缺点是数据库瓶颈成为MQ瓶颈
文件系统:
- RocketMQ/Kafka/RabbitMQ:采用消息刷盘机制,进行数据存储
zero copy:mmap,java MappedByteBuffer
预留了一块空间进行顺序读写,默认1G commitlog
本质上,利用mmap,sendfile等系统api减少了内核空间与用户空间的数据交换次数。mmap处理文件-内存在内核态直通,sendfile处理内存-网络在内核态直通。省去的是内核态内存页到用户态内存页的拷贝,zero copy的用户程序都是没有持有数据copy的buffer的。
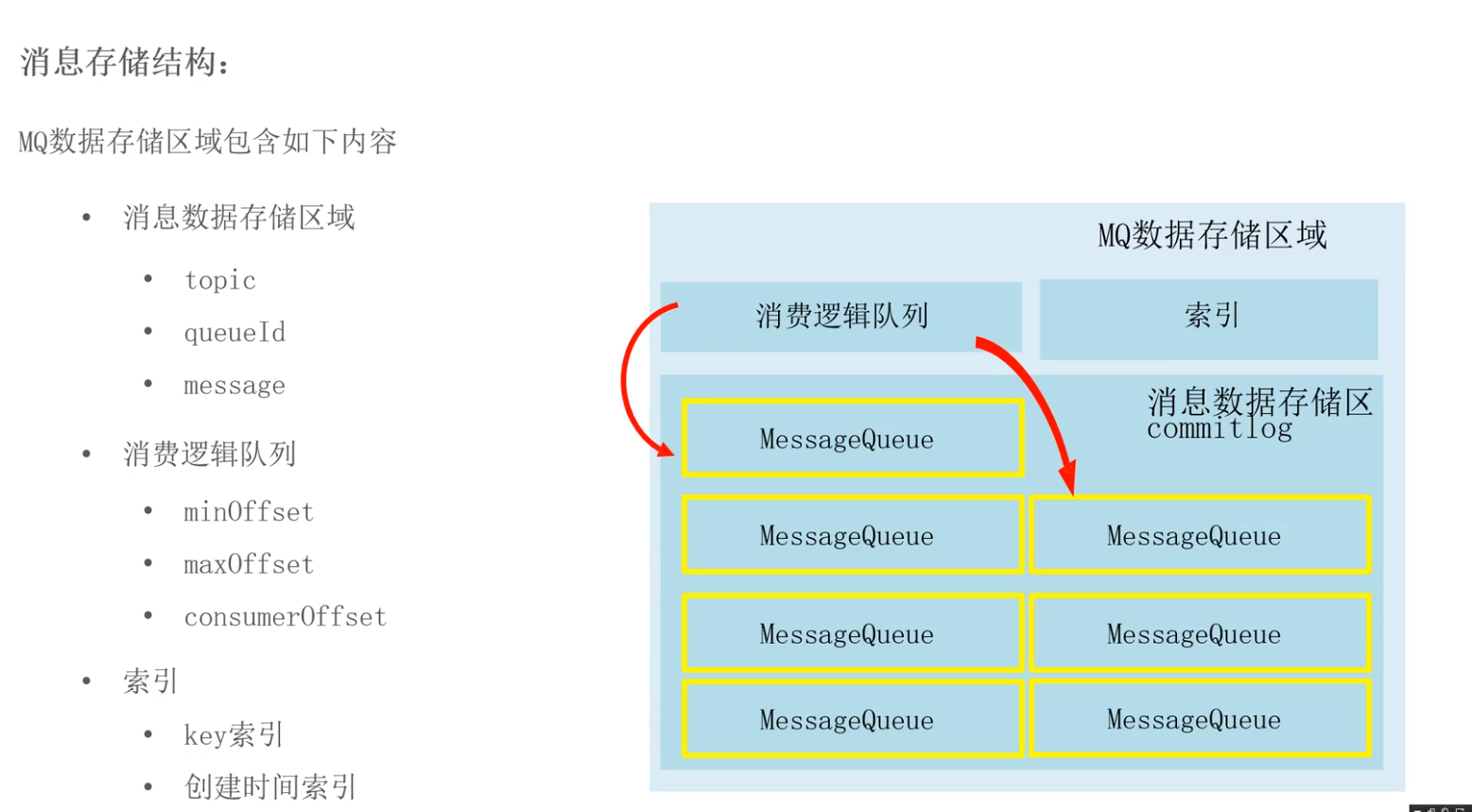
刷盘机制
同步刷盘:先入盘再返回ACK
- 可靠性高,性能低
异步刷盘:不挂起Producer线程,也先不写硬盘,将消息保留到内存之后就向Producer返回ACK,而是积累到一定batch的消息,再批量刷盘
高可用:
- nameserver:
- 无状态+全服务器注册
- 消息服务器
- 主从架构,2主2从
- 消息生产
- 生产者将相同的topic绑定到多个group组,保障master挂掉之后,其他master仍然可以正常接受消息
- 消息消费:RocketMQ会根据master压力确认是否由master承担数据读取功能,master繁忙的时候,自动切换slave做承担数据读取的工作(读写分离)
负载均衡
Producer负载均衡
- RocketMQ内部实现了不同broker集群中对同一topic对应消费队列的负载均衡
Consumer负载均衡
- 平均分配(AABBCC)不好,循环平均分配(ABCABC)好
- 原因,broker部分挂掉时,生产者的流量会被均分到剩下的broker上,如果平均分配,则有些对应挂掉的broker的consumer就不干活了,其他consumer压力会变大;循环平均分配则是将所有的consumer都分到剩下的broker上,避免了单个consumer压力过大
消息重试:
顺序消息:
- 当消费消息失败后,RocketMQ会以1s为间隔进行自动重试。
- 应用会出现消息消费被阻塞的情况,因此需要对顺序消息的消费情况进行监控(监控offset等),避免阻塞
无序消息:
-
仅适用于负载均衡(集群)模型下的消息消费,不适用于广播模式
-
MQ设定了合理的消息重试间隔时长,有一个指数的backoff
-
当重试到达指定次数(默认16次)后,MQ将无法被正常消费的消息称为死信消息。死信消息不会被直接抛弃,而是会被发送到一个死信队列中,供后续处理
死信消息不会再被重复消费,有效期为3天,过时后会被删除
死信处理,业务逻辑处理,或者人工介入
RocketMQ不可能完全避免重复消费,还是存在可能出现重复消费的情况:
- 生产者发送重复消息,例如,网络闪断没收到ACK,生产者宕机
- Broker和消费者之间网络闪断,消费者/broker重启
- 客户端扩缩容
- ......
所以不能完全依赖RocketMQ的幂等性,还是要在业务逻辑上做幂等性处理
- 使用业务id作为消息key
- 在消费消息时,客户端对key做判定,未使用放行,使用过抛弃
- 注�意:messageId由RocketMQ生成,不具有唯一性,不能做幂等判定条件
Kafka VS RocketMQ
Kafka:
- 专注简单与吞吐量: "Do one thing and do it well"的Unix哲学,专注于高吞吐的消息传递
- 不可变数据流: 将消息视为不可变的数据流,适合事件溯源和流处理
- 客户端复杂性: 将复杂性推向客户端,保持服务端简单高效
RocketMQ:
- 丰富的消息功能: 目标是作为全功能的企业级消息系统
- 服务端智能: 在服务端实现更多功能,减轻客户端负担
- 电商场景驱动: 由阿里巴巴电商业务需求驱动设计,面向复杂业务场景
那么古尔丹,高吞吐量的代价是什么呢?
- 偏移量指针的设计只能顺序前进,无法原生支持延迟时间,通过时间戳索引查找偏移量、专用延时主题、定时扫描来达到延时队列
- 必须顺序处理消息,无法灵活跳过(异常消息)和回退(重放)
- 消息路由和分布式一致性绑定,路由灵活性受限
- 不支持消息优先级队列,因为都得按照offset指针顺序处理.....
- 无法设置可见性超时等,都需要上层应用做
- 消费失败的幂等性保证处理复杂,偏移量需要分布式维护增加网络开销.....
| 特性 | Kafka | RocketMQ |
|---|---|---|
| 定时/延时消息 | 需外部实现 | 原生支持 1 |
| 消息回溯 | 支持(通过偏移量) | 支持(更灵活) 1 |
| 消息过滤 | 有限支持 | 服务器端支持SQL92表达式过滤 1 |
| 事务消息 | 有限支持 | 完整支持 1 |
| 死信队列 | 不支持 | 支持 |
| 消息优先级 | 不支持 | 不直接支持,但可通过设计实现 |
| 多租户隔离 | 有限支持 | 更好支持 |
| 消息轨迹追踪 | 需外部工具 | 原生支持 1 |
核心设计的哪些不同带来了这样的差异?
存储模型
Kafka:
- 分散的文件存储: 每个主题的每个分区对应一个物理文件,消息按照写入顺序存储 1
- 顺序追加写入: 使用顺序追加的方式写入文件,不允许修改已写入的数据
- 偏移量指针: 消费者通过偏移量指针确定读取位置,不复制消息
RocketMQ:
- 统一的文件存储: 所有主题的消息存储在同一组物理文件中 3
- 逻辑分区: 主题和队列仅是逻辑概念,不与物理文件一一对应
- 消息索引: 维护更复杂的索引结构,支持按多种方式查�询消息
消息投递模型
Kafka:
- 基于分区的消费模型: 消费者组内的消费者分配分区,消费者只能按顺序消费分区中的消息 1
- 仅支持拉模式: 消费者主动从Broker拉取消息
RocketMQ:
- 更灵活的消费模型: 支持更多的消费模式,包括集群消费和广播消费 1
- 推拉结合: 同时支持推模式和拉模式,提供更灵活的消息投递方式
- 消息过滤: 支持在服务器端进行消息过滤,减少不必要的网络传输
消息处理机制
Kafka: 消息就是字节数组
**RocketMQ: ** 消息包含更多元数据和属性