部分llm技术报告的阅读
Qwen
base model: 3 trillion tokens 三万亿
数据处理
预训练:公共文档,书籍,代码
HTML中提取文本,语言识别工具确定语言
增加多样性: MinHash/LSH 模糊去重
过滤低质量数据:rule-base/ML方法(语言模型,文本质量评分模型,内容审查模型)
进一步提高性能:高质量instruction数据集
tokenization: BPE byte pair encoding
cl100k base作为起点
最终152k词汇量
- embedding: 解绑定的embedding方法,而不是绑定embedding和输出projection的权重
->内存换性能(why) - position embedding: RoPE fp32精度
- Bias: 只有attention的QKV有
- PreNorm & RMSNorm 提高训练稳定性,替代传统layer norm,
prenorm > post-norm - activation function: SwiGLU
训练:上下文2048, flash attn, AdamW, 余弦学习率,最小为10%峰值,bf16混合精度训练
上下文长度拓展:在推理时做,训练时长上下文O(N^2)开销太大,NTK-aware interpolation
另外两个注意力机制: LogN-Scaling and window attention
sft对齐: ChatML-style format
该模型的训练过程采用AdamW优化器,具有以下超参数:β1设置为0.9,β2设置为0.95,()设置为(). 序列长度限制为2048,batch size为128. 该模型总共经过4000步,学习率在前1430步逐渐增加,达到峰值. 为了防止过拟合,应用权重衰减,值为0.1,dropout设置为0.1,梯度裁剪强制限制为1.0.
sft泛化和创造性的限制,容易过拟合 -> RLHF
PPO
tool-use造数据:左脚踩右脚,让Qwen生成更多示例相关的查询、特定格式的输出,应用规则+人工过滤产生训练样本,之后SFT
代码模型:继续预训练,900亿tokens + 8192长上下文
数学模型:1024上下文,数学问题较短加快训练速度
Qwen2.5
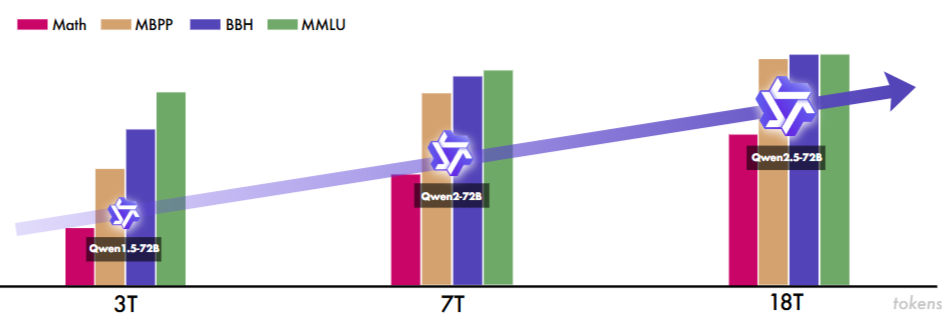
预训练 18万亿tokens
大于100w样本的sft,多阶段强化学习
有效KVcache利用:GQA Group Query Attention
MoE架构:将标准FFN层替换为专门MoE层,每一层包括多个FFN专家和一个路由,路由将tokens分派给topk专家
tokenization从BPE升级到BBPE, 控制token增加
做数据:
-
更好的数据过滤
-
更好的数学和代码数据,在预训练就加
-
更好的合成数据,数学/代码/知识模型生成 + 奖励模型过滤
-
平衡样本分布
电子商务、社交媒体和娱乐等领域在网络规模数据中明显过度表示,通常包含重复的、基于模板的或机器生成的内容。 相反,技术、科学和学术研究等领域虽然包含更高质量的信息,但传统上代表性不足。 通过对过度表示的领域进行战略性降采样,以及对高价值领域进行升采样
长上下文拓展:
最终预训练 4k -> 32k, RoPE 10k->1000k
渐进式拓展
32k->64k->128k->256k
每一个截断包含40%的长序列和60%的短序列,避免遗忘
YARN + Dual Chunk Attention 降低困惑度来改善长序列推理性能
两阶段RL:
• Offline RL:此阶段侧重于开发奖励模型难以评估的能力,例如推理、事实性和 instruction-following。 通过对训练数据进行细致的构建和验证,我们确保 Offline RL 信号既可学习又可靠 (Xiang et al., 2024),使模型能够有效地获得这些复杂技能。
• Online RL:Online RL 阶段利用奖励模型检测输出质量细微差别的能力,包括真实性、helpfulness、简洁性、相关性、harmlessness 和 debiasing。 它使模型能够生成精确、连贯且结构良好的响应,同时保持安全性和可读性。 因此,模型的输出始终符合人类的质量标准和期望。
长上下文:准备long-response dataset:从pre-training data中生成long-text数据对应的长查询,并使用Qwen2过滤低质量data
数学:CoT + 拒绝采样 + reward model/annotated answer
编码:code-related QA web 合成示例,github收集snippet, sandbox code checking, 自动单元测试保证正确性
指令准随:利用可严格验证的code来做,拒绝采样
结构化数据:table QA/fact verification/error correct... 造数据集然后训
逻辑推理:70000个新query迭代改进
回复过滤:多智能体协作评分系统
离线rl, 客观查询领域,数学/编码/逻辑推理/指令追随, 确保回复的质量,只有通过质量检查的才是正示例,其他回答全是负示例
在线rl, 真实性,帮助性,简洁性,相关性,无害性和去偏见
GRPO, 先训response分数方差较高的query
当前的reward model评估benchmark无法准确预测��在其指导下训练的RL模型的性能
Qwen3 Embedding
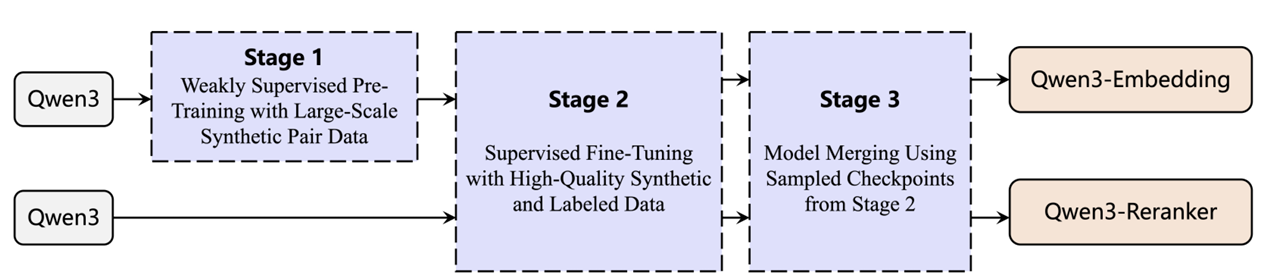
多阶段训练流程: 大规模无监督训练, 高质量数据集有监督微调
qwen3 产生高质量、多语言、多任务的文本相关性数据集,在无监督阶段利用,筛选出部分高质量用于有监督训练
Embedding, Instruction + query,之后直接**[EOS]**, 最后的嵌入是这个EOS对应的最后一层隐藏状态
Reranking, Instruction + query + doc,之后是Assistant:
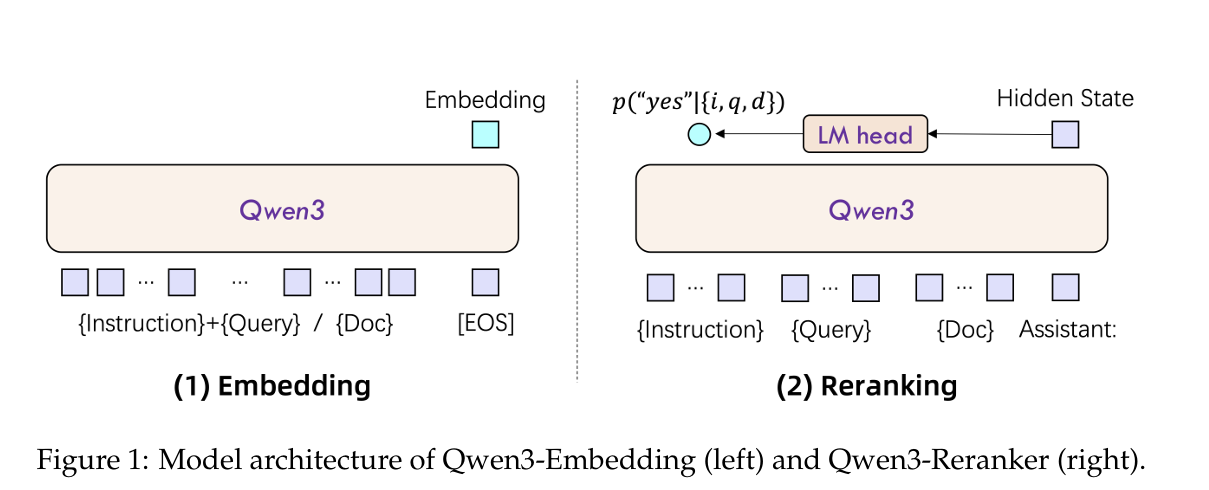
为了嵌入的统一,instruction和query会拼接成同一个输入,{Instruction} {Query}<|endoftext|>
重排: **pointwise,二分类问题,**遵循以下模板,实际相关性分数是yes|no的logits

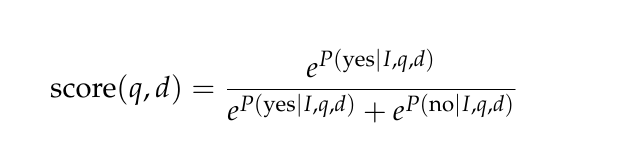
使用InfoNCE作为损失函数

qwen3采用批内负采样
即,在实际对比学习(尤其是检索任务)中,为了训练出区分能力强的模型,负样本非常关键。但生成或采样足够丰富且高质量的负样本往往代价很高或不现实。
因此,常用的做法是:
- 批内负采样(In-batch Negative Sampling):利用当前训练批次中其他样本的 query 、正样本 以及负样本 作为当前样本的负样本补充。
因为batch是随机取的,所以为了避免批内负采样形成错误信号,需要在中把实际是正样本��的部分筛选掉,就是下面的掩码因子

减轻false negative的影响
认为是错负例的:
- 的
- 的,即这个批内负样本比正样本还相似度高0.1以上,这个0.1可能是考虑到初期时数值的稳定性加的
此时掩码为0,的这一项是0,即不考虑这一项作为负样本
比起用if-else等前筛选方法,这个后筛选方法方便并行化,由于预计假负样本应该是比较少的,所以能提高效率
对于rerank, 定义SFT loss
对正面文档是"yes", 负面是"no"
创新点:
- 大规模合成数据,直接使用qwen3的合成数据而不是收集qa pair
- 高质量合成数据在SFT中的利用
- 模型合并:基于球面线性插值(slerp)对微调的多个ckpt进行合并,提升不同数据分布下的鲁棒性和泛化
数据集合成:
Qwen3-32B, 利用检索模型从角色库中,识别出(文档可能对应的)前五个角色候选
然后,将文档+候选角色作为prompt,令模型输出最适合的角色配置
再将角色配置给到模型,生成查询
- 多样性:使用 作为模型合成数据的状态空间
最后产生了1.5亿对数据
高质量对:简单的余弦相似度计算,保留相似度大于0.7的,得到1200w对
结果 SOTA
两个分析:
- 不做合成数据训练,明显掉点
- 不做模型合并,也掉点
Qwen3
GQA, SwiGLU, RoPE, RSMNorm,Pre-Norm
移除QKV的bias, 在attn中引入QK-Norm
MoE, 128专家,激活8个,去除共享专家,采用全局批次负载平衡损失
预训练:36T tokens,100+语言,代码、STEM、推理、书籍、合成数据
部分数据是Qwen-2.5-VL对大量pdf做OCR再Qwen2.5进行文本优化得到的高质量文本数据
三阶段预训练:
- 通用阶段,30T tokens,4k max length,获取语言能力和世界知识
- 推理阶段,增加STEM, 代码,推理和合成数据的比例,5T tokens,4k max length,加速学习率衰减
- 长上下文阶段,32K,4k-16k 25% + 16k-32k 75%,RoPE 基础频率10000->1000000, 引入YARN和双向块注意力
后训练
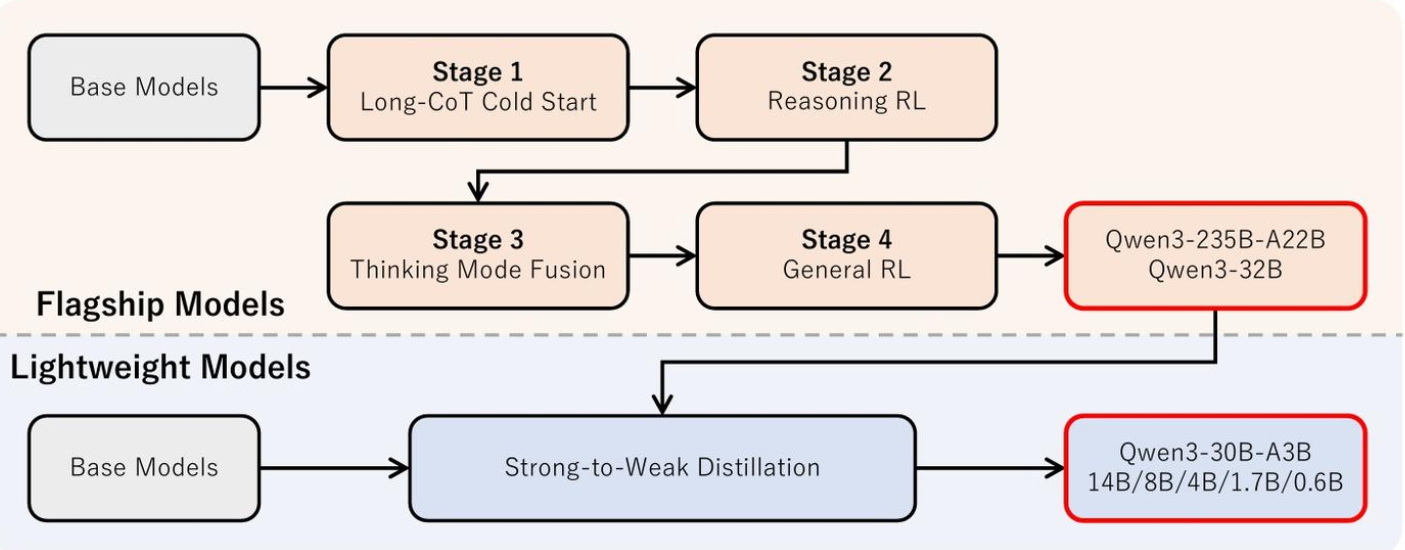
- 思考控制
- 强到弱蒸馏
CoT冷启动:query response两层过滤
query过滤用2.5-72B删除不容易验证的query, 如多个子问题和通用问题,删除2.5-72B能直接正确回答不需要CoT的问题,对每个Query进行领域标注,保持数据平衡
Response过滤用QwQ-32B, 每个问题生成N个response,
- 无法生成正确答案
->人工标注 - 移除最后答案不正确的,存在大量重复的,猜测而缺乏推理的,推理和总结不一致的,混用语言的,可能和验证集过于相似的
冷启动数据直接SFT,学习基础推理模式,为后续RL打基础
推理RL:GRPO, 大Batch Size, 每个Query多Rollout
仅仅用了4k个数据,满足
- 冷启动没用过
- 冷启动模型可学习(不太难)
- 有挑战性
- 广泛子领域
235B-A22B进行了170个RL训练步骤
思考模式融合(控制不思考)
SFT数据集融合思考非思考的数据,同时设计聊天模板,非思考保留空思考块

当模型学会在非思考和思考模式之间切换,就可以**处理基于不完整的思考生成答案,就可以让模型在思考过程中根据预算来强行停止思考过程。**即 当模型的思考长度达到定义的阈值时,插入停止思考指令:“考虑到用户的时间限制,我必须根据目前的思考直接给出解决方案。 \n</think>.\n\n”。并让模型继续根据其积累的推理生成最终响应。
通用RL
增强能力和稳定性
20多任务:指令遵循,格式遵循,偏好对齐,代理能力,特定场景能力(如RAG)
三种奖励:基于规则的奖励,基于模型的奖励(带参考答案),基于模型的奖励(无参考答案)
蒸馏:离线和在线
离线,教师模型产生输出给学生模型SFT
在线,教师和学生对相同prompt在输出logits对齐(最小KL散度)
Ablation
- Math & code 做完 reasoning RL 达到顶峰
- Agent tool use 能力,general RL 也很关键
- 通用语言能力,很需要 General RL
有一个有趣的是thinking其实损害了长上下文的性能
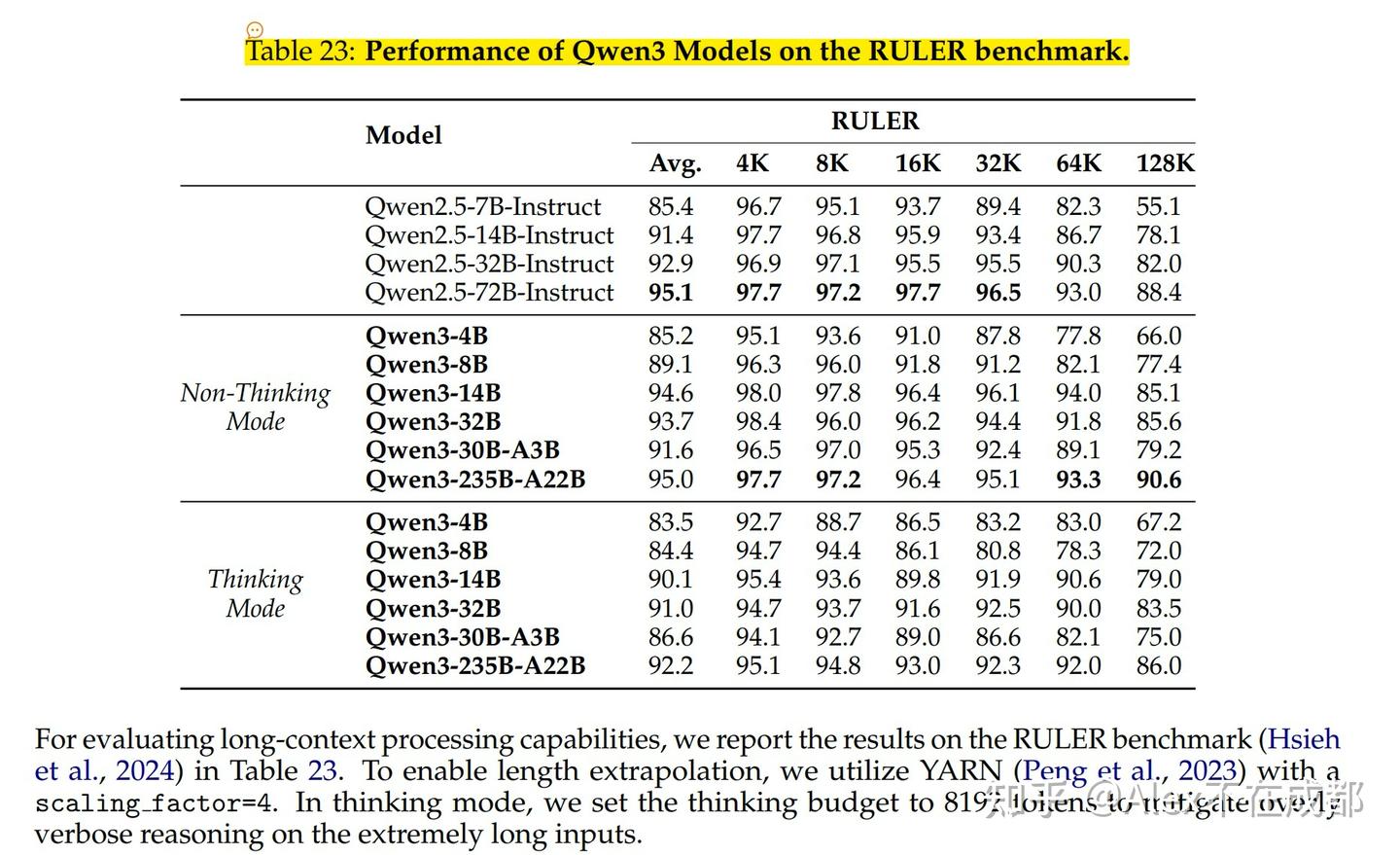
RULER大海捞针,non-thinking mode更高,long CoT甚至掉点
GRPO & RLHF
RLHF大致两种,on policy(ppo)和off policy(dpo)
on policy的更耗卡,更耗时,但理论上限更高
ppo的四个模型:actor, critic, reference model, reward model
on policy:top_p = 1.0, top_k=-1,加大探索
critic 得出,起一个降低方差的作用
ReMax: 用作为baseline,(不是随机采样, 是状态的函数),解决critic model的开销
能够降低方差的原因是默认认为通常 SFT 模型已经经过一部分对齐,对于同一个 prompt 模型不太会输出差异性过大的答案
GRPO:直接退回PG是否有点原始
虽然Critic不仅占资源,并且在LLM这种全部回答的trajectory才重要的情况下,中间的“价值”也很难界定,但PPO还有别的先进feature可以保留,比如重要性采样和clip

只是将 的计算从的输出换成了group内的相对值
非常暴力,但非常有效
KL penalty用近似值保证KL始终是正数,
LLM中,通常将GAE的设置为1,因此也直接将这个得分复制到每一个token训练
尽管这种方法确实可以省掉一个 Critic,但成功需要具备 2 个关键:
- SFT 对给定的 prompt 不能有着太 diverse 的输出,否则方差会比较大。
- 对同一个 prmopt 采样的数量要可能大,这样才能降低方差
offline��方法,DPO
降低不好答案被采样的概率,提升好回答的概率
DPO 有一个非常致命的问题,
由于 DPO 的训练 loss 目标是「尽可能最大化好答案和坏答案之间的采样概率差」,
一种常见的情况是:好答案 & 坏答案被采样的概率同时在变低,只不过坏答案降低的比好答案更多。
这种情况在 chosen 和 rejected 答案有大部分内容相同,仅有少部分内容不同时较为常见。
DPOP添加了一个如果choosen答案在SFT模型(ref)中采样概率大于当前policy模型的采样概率,则减去的正则项(policy还没拟合好,少更新点)
TDPO 加上了KL,但是是forward KL(KL非对称,SFT计算采样概率是forward, policy model计算是backward KL)
由于 backward KL 的目标是拟合整个分布中的「一部分」,而 forward KL 的目标是尽可能 cover 整个分布中的大部分。因此,TDPO 训练后的模型会比 PPO 训练后的模型,在输出多样性上更加自由。
token clipping 操作是导致性能下降的主要原因!尤其是像 "However"、"Recheck"、"Wait"、"Aha" 这类带有反思性质的 token 在初始模型中本就属于低概率 token,在更新过程中容易出现高奖励值继而被裁剪,从而无法继续为后续梯度更新提供贡献。
minimax提出CISPO,不丢弃token梯度,裁剪重要性采样权重
传统方法: 先计算 , 再裁剪乘积
CISPO: 先裁剪 , 再乘以
效率显著提高(2x speed)
早停: 目标不是对已经生成的重复文本进行惩罚,而是在模型进入重复循环前就终止生成。由于简单的字符串匹配难以应对复杂的重复模式,我们设计了一个基于 token 概率的启发式方法。
一旦模型进入重复循环,所生成 token 的概率会大幅上升。因此我们制定了如下早停规则:
如果连续 3,000 个 token 的生�成概率都大于 0.99,就立即终止生成。