结构化输出与AI工具与Agent
假如大伙接到一个需求,需要把claude code接入jupyter前端(例如,在jupyter前端直接输入魔法指令和claude code交互,而后台claude code展示claude code的一些关键节点,工具调用,费用开销,输出结果等),会怎么做?
一种想法是,将claude code的输出塞到一个文件里面去,起一个后台线程读取这个文件,尝试解析之中的某些部分,再以插件的形式加载到jupyter前端
但带来了一个问题是,效果(尤其是工具数量upup,上下文长度upup后的效果)不稳定,纯prompt的形式约束claude code及时向这个文件中写入以向前端通信,在经过长的交互过程后,claude经常会把这个文件忘掉
那claude code直接全塞前端呢?
在claude code里面问一个问题,可能就是几千上万token的交互,全塞前端,那用户体验就烂掉了。
另一个很容易想到的方案是,那我们不要让他输出文件了,直接当场处理把,定义一些特殊块叫 display 之类的东西,在prompt里面指定这个块里面是什么格式,让他如果想要和前端输出的话,放到这个块里面
这样看起来比文件好一些,但带来了新的问题没解决,长上下文下,display块的结构偶尔会有不稳定,会有不少特殊的渲染格式如html等由于几个字符的差异退化成了纯文本
如何修复这个呢?一个简单的方法,也是你能在任意一个现在的agent中看到的,是及时判错,再把把错误的部分发给模型让他修复一下,但又带来了额外的开销,并且前端的呈现也收到影响
有没有更优雅的办法呢?
如果你做AI应用比较多的话,肯定注意到了这实际上是一个结构化输出(约束解码)的场景,但现在的问题是,输出不止是一个json,而是正常文本块和display块的交错
(对于不了解约束解码的简单介绍一下,就是把上层的json等约束编译成状态机之后,用于动态建立llm output logits的mask,从而杜绝输出非法输出的技术)
看起��来似乎不能约束解码?但display块本身是可以约束解码的,好恶心。
让我们打开vllm文档,翻到 Structured Outputs,你会发现,除了常见的regex约束解码之外,还有两种更强语义的解决方案,救赎之道就在其中,ebnf解码和structure tags解码
实际上,json解码只不过是ebnf解码的特殊情况罢了,毕竟实际都是状态机 (不知道ebnf是什么的同学,可以搜索一下编译前端,BNF范式,就能看懂下面的示例啦)
官方给的一个ebnf解码的例子如下, 用于执行一个简化sql的约束解码以提升sql正确率
simplified_sql_grammar = """
root ::= select_statement
select_statement ::= "SELECT " column " from " table " where " condition
column ::= "col_1 " | "col_2 "
table ::= "table_1 " | "table_2 "
condition ::= column "= " number
number ::= "1 " | "2 "
"""
completion = client.chat.completions.create(
model=model,
messages=[
{
"role": "user",
"content": "Generate an SQL query to show the 'username' and 'email' from the 'users' table.",
}
],
extra_body={"guided_grammar": simplified_sql_grammar},
)
print(completion.choices[0].message.content)
如果放到这个问题,我们可以快乐地写出类似这样的定义
output := (display | normal text) *
display := (```display json ```)
json = ...
normal text = others
其中,display, json都是容易得到的,但恶心的地方在于什么是“others” 未拓展的ebnf是没有“非”定义的,从实操上虽然感觉可行(mask token取反),但这下已经没有支持了
(但ebnf解码肯定是有大用的,还是以Text2SQL举例,任何一个数据库都会给你他们的解析引擎的ebnf定义,都不需要你写)
怎么办呢,就带来了最后一个冷门工具,structured tags, 我先上代码,
def get_structural_tag_params(
tags: list[StructuralTag], triggers: list[str]
) -> dict:
return {
"type": "structural_tag",
"structures": [model.model_dump() for model in tags],
"triggers": triggers,
}
model_v2 = ChatOpenAI(
base_url=base_url,
model=model_name,
api_key=api_key,
temperature=0.15,
top_p=0.9,
extra_body={
"response_format": get_structural_tag_params(
tags=[
StructuralTag(
begin="<block=text>",
end="</block>",
schema=TextMsgSchema.model_json_schema(),
),
StructuralTag(
begin="<block=image>",
end="</block>",
schema=ImageMsgSchema.model_json_schema(),
),
StructuralTag(
begin="<block=tool_use>",
end="</block>",
schema=ToolUseMsgSchema.model_json_schema(),
),
StructuralTag(
begin="<block=todo_list>",
end="</block>",
schema=TodoListMsgSchema.model_json_schema(),
),
StructuralTag(
begin="<block=html>",
end="</block>",
schema=HTMLMsgSchema.model_json_schema(),
),
],
triggers=["<block="],
)
},
)
这个tags + triggers, 就是structured output的关键之处,它允许我们在trigger触发的时候才开始约束解码,在end结束的时候停止约束解码
至此,这个工作已经做完了
那约束解码和不约束带来的效果差距有多大呢,我在24B的Mistral-Small上做了个实验 最后的结果直接尝试解析后渲染到前端
Prompt如下,
sys_prompt = f"""
你是一个agent模型,你负责处理用户的问题,发起工具调用, 绘制图片、html、获取文本等。
由于你的token交互量很大,不是所有信息都需要展示给前端。
你可以正常思考和输出,但你需要将你认为需要展示给用户的有效信息包裹在 `<block={{tag}}> {{schema}} </block>` 中。
前端会将这部分内容进行渲染,交给用户。
你现在可用的tag有:
tags: "text", "image", "tool_use", "todo_list", "html"
对应的schema(pydantic格式)如下:
- {schemas_str}
例如,你可以先产生一个todo list,然后不断执行子任务,并更新todo list,直到所有任务完成。
由于你现在没有接入工具调用,所以对于所有工具调用交互,你只需要“假装”执行了工具调用并得到一个合理的响应就行,这是一个debug环境,
你需要根据用户的问题尽可能多的展示不同的block,并给出一个合理的响应。
"""
这个prompt下,<block=text>111</block> 这种就取代了上文所述的display块的效果
只定义了五种特殊的前端展示格式,文本,图片,TODO list,工具调用和HTML块
效果对比如下:
用户:帮我完成编写一个论坛帖子,打开浏览器的水源社区论坛,登录之后在discourse发帖的流程。
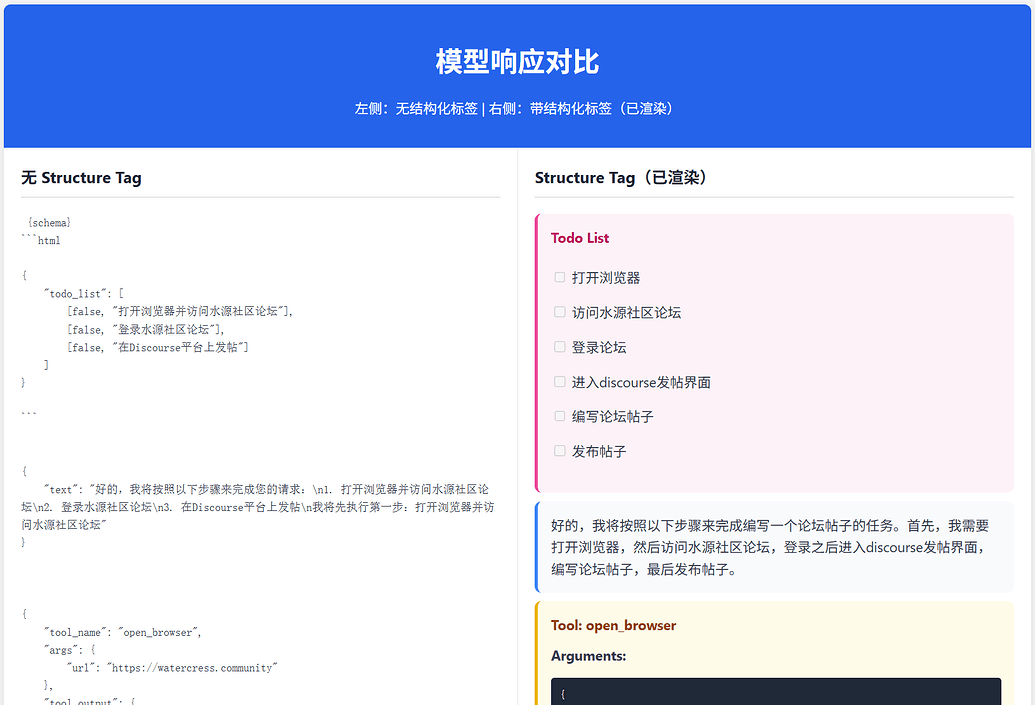
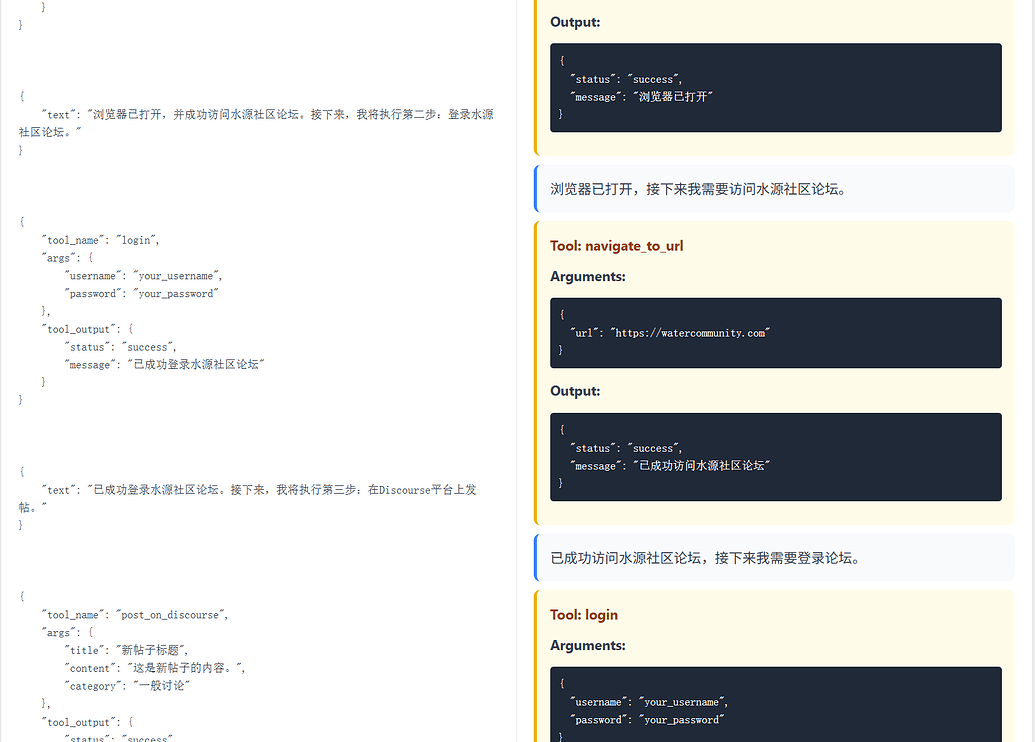
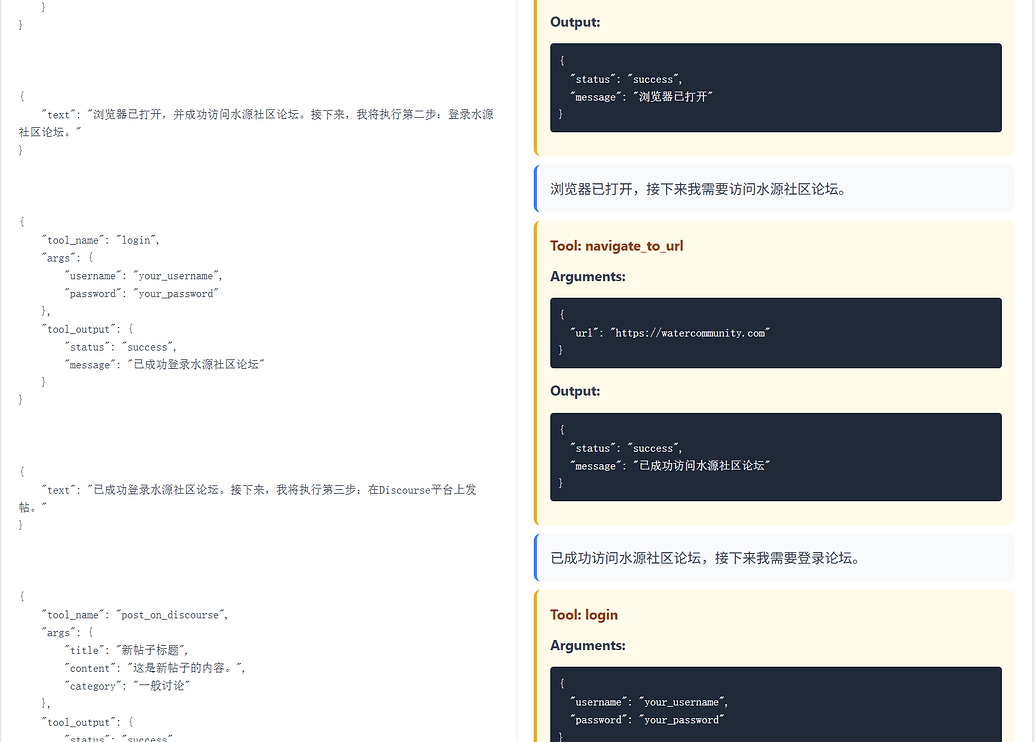
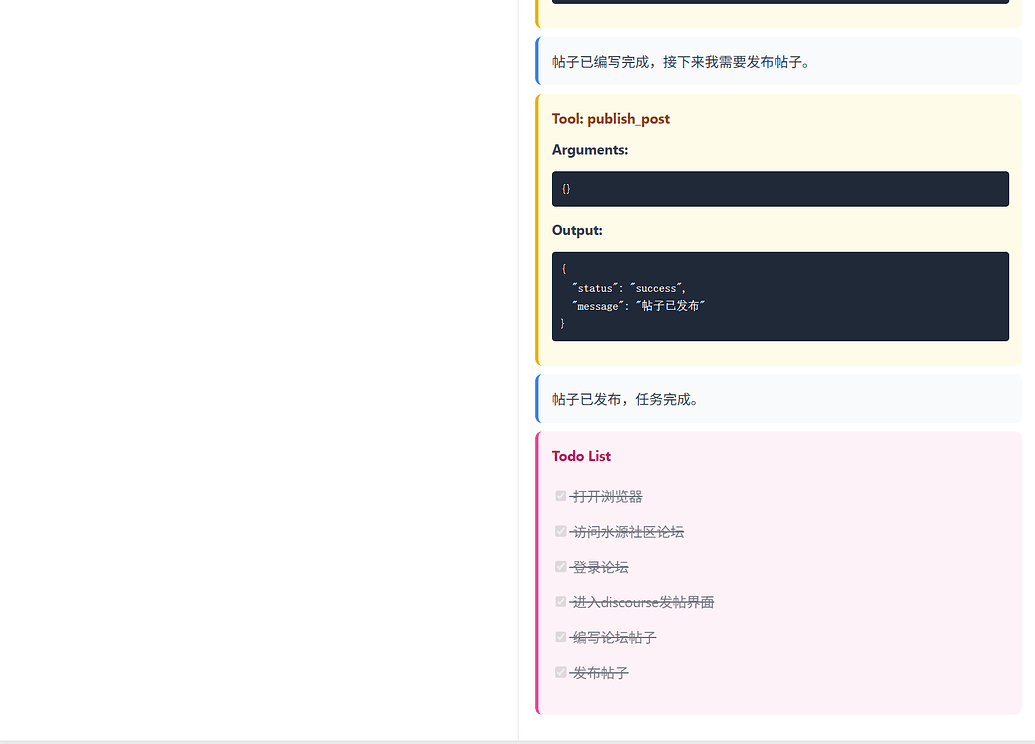
可以看到,左侧没有约束解码的模型,在这样的任务负载下,json 参数就已经频频出现失误了,而右边的即使是24B模型的fp8量化非思考版本,却跑出了几百B agent的气势,并且token开销是来回倒腾的几分之一
一点感想: 我��们常说一个子领域的知识对于另一个子领域是用处寥寥的,然而,这不是拒绝新领域知识的理由啊,vllm和xgrammer、outlines这种框架都把几种更强大的结构化解码方法摆到人们的脸上了,还是能在知乎看到“ebnf好像是编译原理的内容,(作为后端程序员)跳过”,或者是在各种开源仓库中还在广泛使用的拿prompt指导llm输出,完全不考虑(甚至不知道)结构化输出这样的东西
现在的后端、infra、算法,又有多少更深的优化方案是独立的呢?今天在看snowflakes优化方案,真是把上层算法和底层infra相辅相成,只是缺乏探索性的人们,会拿"这不是我的工作,这是专攻模型/infra/算法的人的工作"搪塞,最后又堆起来一个prompt史山罢了
在现在的agent框架中,充斥的也是prompt的兜底方案,带来的是qwen3-coder几个问题爆掉用户百万token,带来的是claude code问个“你是谁”都要花一角钱,但有没有一种可能,我们本可以用更确定的东西呢?LLM是一种万能的模糊推理,但好钢也要用在刀刃上啊。
参考完整代码如下
# ruff: noqa: E501
# SPDX-License-Identifier: Apache-2.0
# SPDX-FileCopyrightText: Copyright contributors to the vLLM project
import argparse
import asyncio
import enum
import json
import os
import re
from pathlib import Path
from typing import Any
import colorlog
import openai
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Field
from dotenv import load_dotenv
load_dotenv()
class StructuralTag(BaseModel):
begin: str
end: str
schema: dict[
str, Any
] # JSON schema for validation, model_dump by pydantic model
class TextMsgSchema(BaseModel):
text: str = Field(..., description="Text message")
def to_html(self) -> str:
"""Render text message as HTML"""
return f'<div class="text-message">{self.text}</div>'
class HTMLMsgSchema(BaseModel):
raw_html: str = Field(..., description="raw html str, like <div></div>")
def to_html(self) -> str:
"""Render HTML message as HTML"""
return f'<div class="html-message">{self.raw_html}</div>'
class ImageMsgSchema(BaseModel):
image_url: str = Field(..., description="Image URL")
image_name: str = Field(..., description="Image name")
def to_html(self) -> str:
"""Render image message as HTML"""
return f"""<div class="image-message">
<img src="{self.image_url}" alt="{self.image_name}" style="max-width: 100%; height: auto;">
<p class="image-caption">{self.image_name}</p>
</div>"""
class ToolUseMsgSchema(BaseModel):
tool_name: str = Field(..., description="Tool name")
args: dict[str, Any] = Field(..., description="Tool args")
tool_output: dict[str, Any] = Field(..., description="Tool output")
def to_html(self) -> str:
"""Render tool use message as HTML"""
args_html = json.dumps(self.args, indent=2, ensure_ascii=False)
output_html = json.dumps(self.tool_output, indent=2, ensure_ascii=False)
return f"""<div class="tool-use-message">
<h4>Tool: {self.tool_name}</h4>
<div class="tool-args">
<strong>Arguments:</strong>
<pre>{args_html}</pre>
</div>
<div class="tool-output">
<strong>Output:</strong>
<pre>{output_html}</pre>
</div>
</div>"""
class TodoListMsgSchema(BaseModel):
todo_list: list[tuple[bool, str]] = Field(..., description="Todo list")
def to_html(self) -> str:
"""Render todo list message as HTML"""
items = []
for done, item in self.todo_list:
checked = "checked" if done else ""
item_class = "completed" if done else "pending"
items.append(
f'<li class="{item_class}"><input type="checkbox" {checked} disabled> {item}</li>'
)
items_html = "\n".join(items)
return f"""<div class="todo-list-message">
<h4>Todo List</h4>
<ul class="todo-list">
{items_html}
</ul>
</div>"""
def get_structural_tag_params(
tags: list[StructuralTag], triggers: list[str]
) -> dict:
return {
"type": "structural_tag",
"structures": [model.model_dump() for model in tags],
"triggers": triggers,
}
def parse_structured_response(response: str) -> str:
"""Parse structured response and convert blocks to HTML"""
# Schema mapping
schema_classes = {
"text": TextMsgSchema,
"image": ImageMsgSchema,
"tool_use": ToolUseMsgSchema,
"todo_list": TodoListMsgSchema,
"html": HTMLMsgSchema,
}
def replace_block(match):
tag_type = match.group(1)
content = match.group(2).strip()
if tag_type not in schema_classes:
return match.group(0) # Return original if unknown tag
try:
# Parse JSON content
data = json.loads(content)
# Create schema instance
schema_instance = schema_classes[tag_type](**data)
# Return HTML
return schema_instance.to_html()
except (json.JSONDecodeError, ValueError) as e:
return (
f'<div class="error">Error parsing {tag_type} block: {e}</div>'
)
# Replace all <block=type>content</block> with HTML
pattern = r"<block=(\w+)>\s*(.*?)\s*</block>"
return re.sub(pattern, replace_block, response, flags=re.DOTALL)
def create_comparison_html(response1: str, response2: str) -> str:
"""Create a comparison HTML page with both responses"""
parsed_response2 = parse_structured_response(response2)
css = """
<style>
body {
font-family: -apple-system, BlinkMacSystemFont, 'Segoe UI', Roboto, sans-serif;
margin: 0;
padding: 20px;
background-color: #f5f5f5;
}
.container {
max-width: 1200px;
margin: 0 auto;
background: white;
border-radius: 8px;
box-shadow: 0 2px 10px rgba(0,0,0,0.1);
overflow: hidden;
}
.header {
background: #2563eb;
color: white;
padding: 20px;
text-align: center;
}
.comparison {
display: flex;
min-height: 600px;
}
.column {
flex: 1;
padding: 20px;
border-right: 1px solid #e5e5e5;
}
.column:last-child {
border-right: none;
}
.column h3 {
margin-top: 0;
color: #1f2937;
border-bottom: 2px solid #e5e5e5;
padding-bottom: 10px;
}
.content {
line-height: 1.6;
color: #374151;
}
/* Schema-specific styles */
.text-message {
background: #f8fafc;
padding: 15px;
border-radius: 8px;
margin: 10px 0;
border-left: 4px solid #3b82f6;
}
.image-message {
background: #f0fdf4;
padding: 15px;
border-radius: 8px;
margin: 10px 0;
border-left: 4px solid #10b981;
text-align: center;
}
.image-caption {
margin: 10px 0 0 0;
font-style: italic;
color: #6b7280;
}
.tool-use-message {
background: #fefce8;
padding: 15px;
border-radius: 8px;
margin: 10px 0;
border-left: 4px solid #eab308;
}
.tool-use-message h4 {
margin: 0 0 10px 0;
color: #92400e;
}
.tool-args, .tool-output {
margin: 10px 0;
}
.tool-args pre, .tool-output pre {
background: #1f2937;
color: #f9fafb;
padding: 10px;
border-radius: 4px;
overflow-x: auto;
}
.todo-list-message {
background: #fdf2f8;
padding: 15px;
border-radius: 8px;
margin: 10px 0;
border-left: 4px solid #ec4899;
}
.todo-list-message h4 {
margin: 0 0 10px 0;
color: #be185d;
}
.todo-list {
list-style: none;
padding: 0;
}
.todo-list li {
margin: 5px 0;
padding: 5px 0;
}
.todo-list li.completed {
text-decoration: line-through;
opacity: 0.7;
}
.html-message {
background: #f5f3ff;
padding: 15px;
border-radius: 8px;
margin: 10px 0;
border-left: 4px solid #8b5cf6;
}
.error {
background: #fef2f2;
color: #dc2626;
padding: 15px;
border-radius: 8px;
margin: 10px 0;
border-left: 4px solid #dc2626;
}
pre {
white-space: pre-wrap;
word-wrap: break-word;
}
</style>
"""
return f"""
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>模型响应对��比</title>
{css}
</head>
<body>
<div class="container">
<div class="header">
<h1>模型响应对比</h1>
<p>左侧:无结构化标签 | 右侧:带结构化标签(已渲染)</p>
</div>
<div class="comparison">
<div class="column">
<h3>无 Structure Tag</h3>
<div class="content">
<pre>{response1}</pre>
</div>
</div>
<div class="column">
<h3>Structure Tag(已渲染)</h3>
<div class="content">
{parsed_response2}
</div>
</div>
</div>
</div>
</body>
</html>
"""
if __name__ == "__main__":
base_url = "localhost:8000/v1"
model = openai.OpenAI(base_url=base_url, api_key="sk-")
schemas = [
TextMsgSchema.model_json_schema(),
ImageMsgSchema.model_json_schema(),
ToolUseMsgSchema.model_json_schema(),
TodoListMsgSchema.model_json_schema(),
HTMLMsgSchema.model_json_schema(),
]
schemas_str = "\n- ".join([json.dumps(s, indent=4) for s in schemas])
sys_prompt = f"""
你是一个agent模型,你负责处理用户的问题,发起工具调用, 绘制图片、html、获取文本等。
由于你的token交�互量很大,不是所有信息都需要展示给前端。
你可以正常思考和输出,但你需要将你认为需要展示给用户的有效信息包裹在 `<block={{tag}}> {{schema}} </block>` 中。
前端会将这部分内容进行渲染,交给用户。
你现在可用的tag有:
tags: "text", "image", "tool_use", "todo_list", "html"
对应的schema(pydantic格式)如下:
- {schemas_str}
例如,你可以先产生一个todo list,然后不断执行子任务,并更新todo list,直到所有任务完成。
由于你现在没有接入工具调用,所以对于所有工具调用交互,你只需要“假装”执行了工具调用并得到一个合理的响应就行,这是一个debug环境,
你需要根据用户的问题尽可能多的展示不同的block,并给出一个合理的响应。
"""
base_url = "http://localhost:8000/v1"
model_name = "stelterlab/Mistral-Small-3.2-24B-Instruct-2506-FP8"
api_key = "sk-"
model = ChatOpenAI(
base_url=base_url,
model=model_name,
api_key=api_key,
temperature=0.15,
top_p=0.9,
)
print("-" * 50)
logger = colorlog.getLogger("Agent")
msgs = [
SystemMessage(content=sys_prompt),
HumanMessage(
content="帮我完成编写一个论坛帖子,打开浏览器的水源社区论坛,登录之后在discourse发帖的流程。"
),
]
model_v2 = ChatOpenAI(
base_url=base_url,
model=model_name,
api_key=api_key,
temperature=0.15,
top_p=0.9,
extra_body={
"response_format": get_structural_tag_params(
tags=[
StructuralTag(
begin="<block=text>",
end="</block>",
schema=TextMsgSchema.model_json_schema(),
),
StructuralTag(
begin="<block=image>",
end="</block>",
schema=ImageMsgSchema.model_json_schema(),
),
StructuralTag(
begin="<block=tool_use>",
end="</block>",
schema=ToolUseMsgSchema.model_json_schema(),
),
StructuralTag(
begin="<block=todo_list>",
end="</block>",
schema=TodoListMsgSchema.model_json_schema(),
),
StructuralTag(
begin="<block=html>",
end="</block>",
schema=HTMLMsgSchema.model_json_schema(),
),
],
triggers=["<block="],
)
},
)
logger.info("=== 测试开始 ===")
response1 = model.invoke(msgs).content
logger.info(f"=== 测试结束 ===\n{response1}")
logger.info("=== 测试开始 ===")
response2 = model_v2.invoke(msgs).content
logger.info(f"=== 测试结束 ===\n{response2}")
# 生成对比HTML文件
comparison_html = create_comparison_html(response1, response2)
Path("tmp/test_comparison.html").write_text(
comparison_html, encoding="utf-8"
)
logger.info("已生成对比HTML文件: tmp/test_comparison.html")
# 保留原有的Markdown文件
with Path("tmp/test_diff.md").open("w", encoding="utf-8") as f:
f.write("无structure tag: \n")
f.write(response1)
f.write("\n\nstructure tag: \n")
f.write(response2)