ColBERT-后期交互方法
如果简单引入语义搜索,那么第一时间想到的肯定是向量搜索的方法
先不论小的优化,向量方法现在大体上就是两种架构,单塔和双塔,对应Cross-Encoder和普通的Encoder模型。
双塔模型如下,查询和文档分别通过两个独立的编码器,得到向量表示和,然后计算相似度(内积,余弦,等等)。
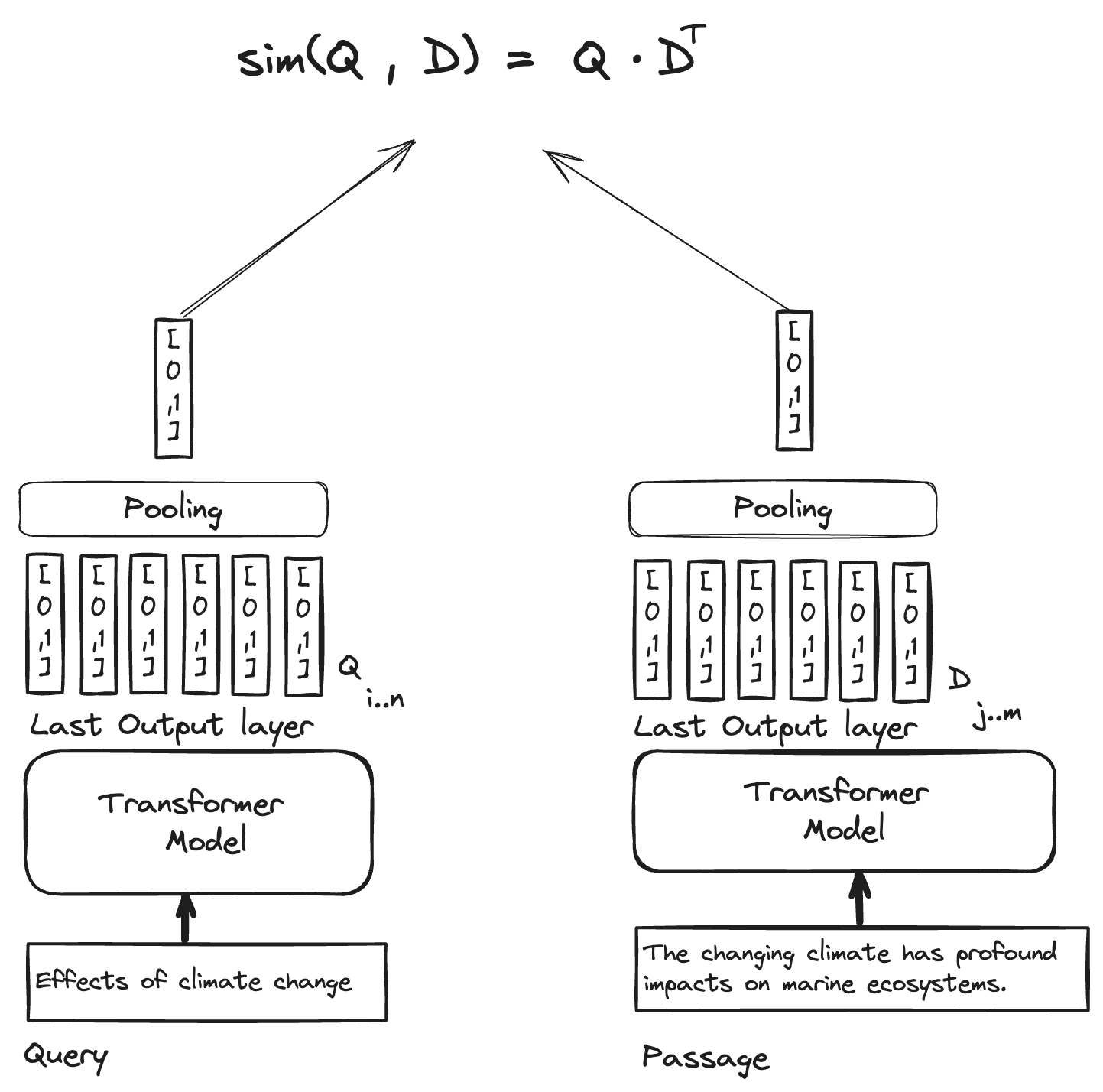
而单塔模型则是将查询和文档拼接在一起,输入到一个交叉编码器中,这个交叉编码器很多时候就直接输出相关性得分score了,即为我们所说的reranker
单塔虽然精度远高于双塔,但有无法离线计算的缺点
而双塔的一大精度困境在于,当编码的文档变长时,文档的大部分内容可能都和查询没什么关系,这会导致查询向量和文档向量的相似度计算不准确。实际上,在楼主之前的一些实验之中,一整个很大的文档集合内,和某个查询最无关和最相关的文档的余弦相似度相差也就0.2左右,这就是长文档带来的问题。
但客观地讲,长文档是无法避免的,如果把文档切成更细粒度的句子,在上下文补齐语义�,后续合并等麻烦可能更多,并且会出现"长文档实际上是在让相似度检索考虑上下文"这样的情况,一个例子是,问题是"上海交大的用户论坛中,....",而文档可能是"...水源社区是上海交大的用户论坛。水源社区....." 如果仅在句子等短文本上面匹配,那缺少了上下文的情况下,"水源社区"当然和"上海交大"没什么关系。
那么,如何保证精度的同时又能离线计算呢?
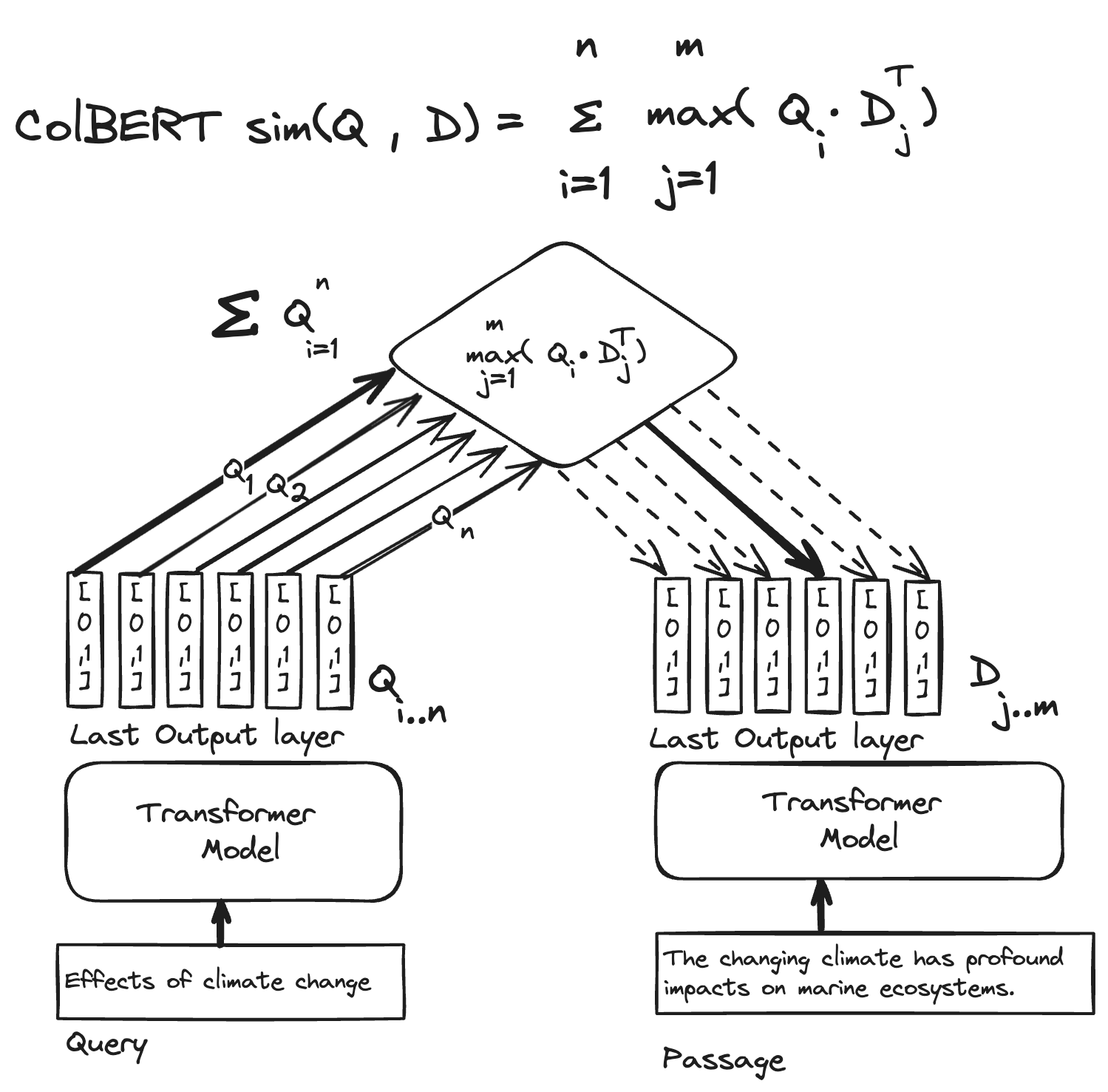
ColBERT的思路是,使用双塔模型来计算相似度,但在编码文档时,使用了一个更细粒度的向量表示。
ColBERT给每个token一个向量表示,而不是给每个文档一个向量表示。这样,查询和文档的相似度计算就可以在token级别进行。
如下图,ColBERT在拿到最后一层的输出之后(这一层有非常多的语义信息!),将每一个token对应的vector都存下来,这一部分是离线的。
而在计算相似度的时候,将query的tensor和文档的tensor进行一个算子
是一个最大池化操作,取出每个token的向量中与查询向量最相似的那个向量,然后计算相似度。
ColBERT的性能是逼近reranker的,这个也很好理解,毕竟交叉编码器的优势就是可以考虑之间的交互,而ColBERT除了保留语义嵌入之外,比起更暴力的加大embedding维度,更重要的是它保存了上下文次序的信息
而ColBERT的最后一层MaxSim,而没有采用神经网络的方案,让他带来了良好的可解释性

那看了上面立刻就会想到,这每一个token保存一个768/1024/...维的向�量,存储开销不会很大吗?
ColBERT也考虑到了这个问题,因此在ColBERTv2中,采用了这样质心编码的方法来降低存储开销,能降低8倍
-
对每个token的向量进行聚类,得到个质心(k是一个预定义的数字)
-
对每个token的向量,找到距离最近的质心,并将其索引存储下来,也就是从
-
将质心向量库构建ANN索引,例如FAISS, ScaNN
-
在计算相似度时,查询向量也进行同样的处理,找到距离查询最近的质心索引,然后从质心向量库中取出对应的质心向量进行相似度计算
在实际使用的时候,商业rag公司甚至对大规模检索做更狠的二值化向量压缩(说实话这也能检索出来真的有点现代模型神力了),让ColBERT的开销可以和单独的embedding媲美
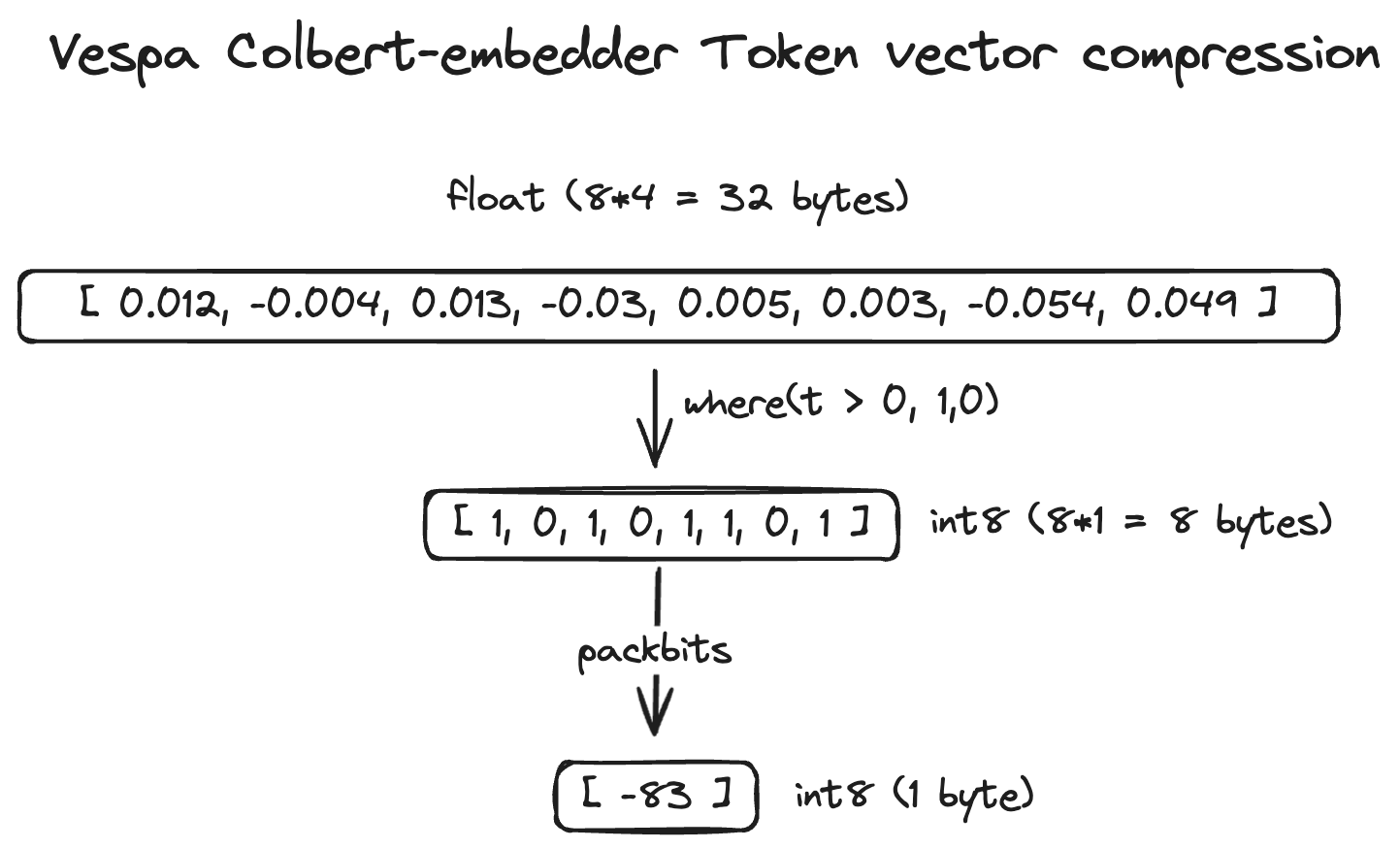
二值化的说法是这样的:
压缩方法通过将正维度表示为 1、负维度表示为 0 来简化文档标记向量。这种二进制表示有效地指示了文档标记向量中重要语义特征的存在与否。 正维度有助于增加点积,表明相关的语义相似性,而负维度则被忽略。
ColBERT的使用上,很多公司都有了支持,例如vespa, jina等等,开源方案则有早期的ragatouile和后来的上下游如milvus,llamaindex的支持
但是,文档ColBERT还不是它发挥全部潜能的时候,据说SPLADE算法就比他效果好不少(这个我没有实测过),它在图像又活出了第二世,即所谓的ColPali架构
ColPali是MRAG、MLLM那边的�新论文和解决方案,几个月的时间砍了1.9k star,ColPali的想法是这样的
- OCR的多个组件和分块带来误差传播,且预处理流程耗时也长,能不能直接端到端一次使用文档截图解决
- 但是如果将整页的文档编码成一个向量,肯定精度不够
- 我的ViT等视觉编码器会将整页文档变成一系列的patch(可以理解为子图),进而变成一系列视觉token,那我重用ColBERT,不就又有了多向量吗?并且这个存储和交互上比每个token存一个向量更合理! 子图本身就有很多的空间位置信息
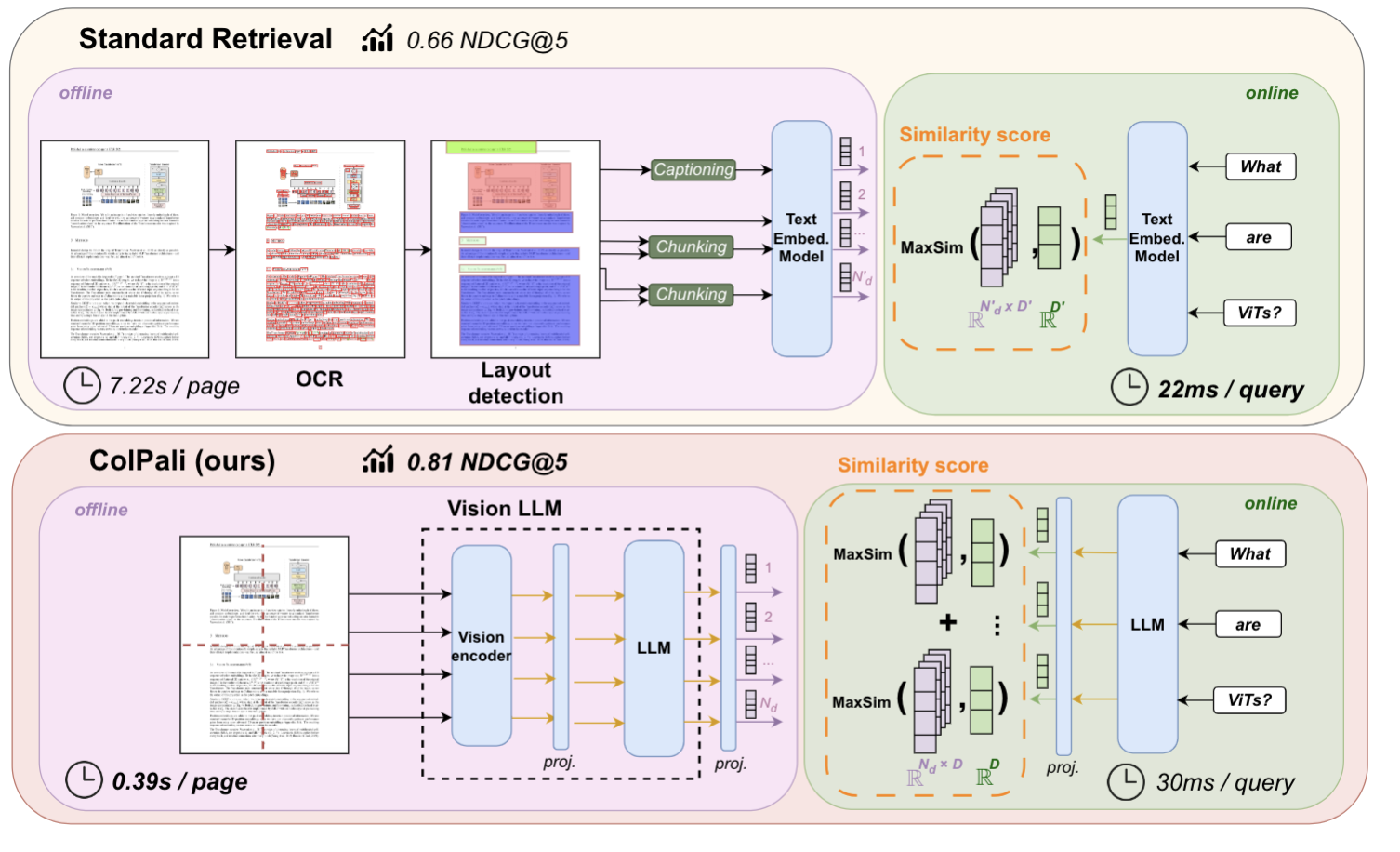
并且,你会发现ColBERT的强可解释性在图像上有更关键的作用!模型在文本中关注了什么可能是某个词,还需要人进行一点逻辑推理来判断关系是否合理,而图像中关注了什么,直接看图就知道了!
作为一种新的RAG范式,ColPali从源头上解决了复杂的OCR和切块的问题
虽然其在重文字领域上的泛化性还留待验证,精度的提升也依赖于未来VLM的发展,但无疑社区已经认同了这个想法的价值
基于 OCR 的文本提取,以及随后的布局和边界框分析,仍然是重要文档 AI 模型(例如 LayoutLM)的核心。例如, LayoutLMv3 对文档文本进行编码,包括文本标记序列的顺序、标记或线段的 OCR 边界框坐标以及文档本身。这在关键的文档 AI 任务中取得了最佳成果,但前提��是第一步——OCR 文本提取——能够顺利完成。
但通常情况并非如此。
根据我最近的经验,OCR 瓶颈导致现实世界生产文档档案中的命名实体识别 (NER) 任务的性能下降近 50%。
目前例如ColQwen2这种ColBERT + Qwen2.5-VL-3B-Instruct的方案也很火,很多榜上都刷到了SOTA,感兴趣的同学也可以自己试试