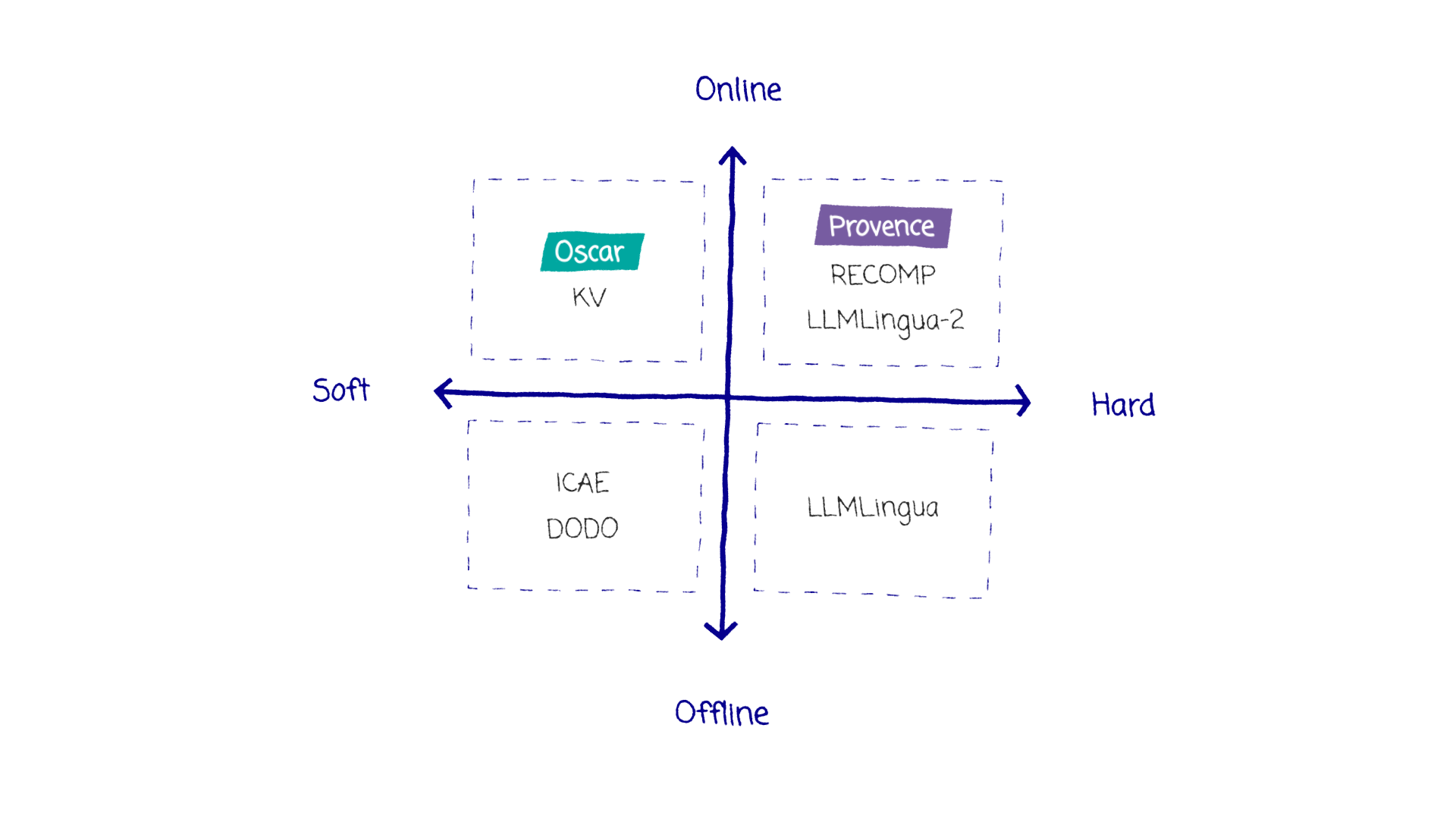
从现代Coding Agent视角回看代码搜索与嵌入
应该如何说起代码搜索呢,先说代码搜索的几个小的子流派吧,这方面可能略微和其他领域不同
代码的检索我认为是可以分解成以下几种的:
- 搜索引擎式
- grep传统搜
- 向量embedding搜
- 码仓index
每一种都是什么意思呢,举个例子
搜索引擎式是复用传统的搜索引擎,如elasticsearch, meilisearch等;也有一些变体,比如github的代码搜索,主要是弥补传统搜索引擎在代码搜索的不足
grep如其名字,基于linux grep或者riggrep,在agent内使用最广
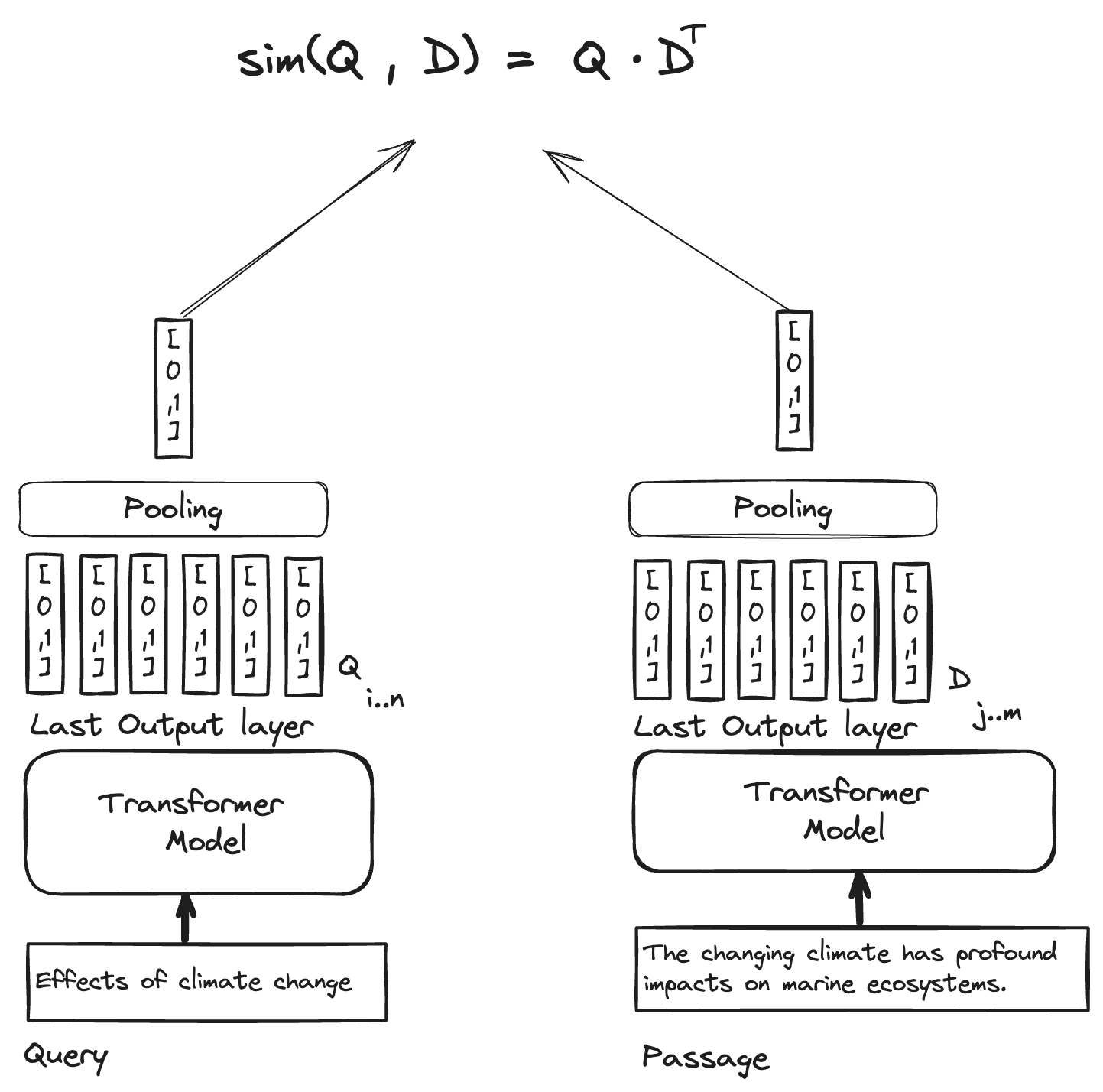
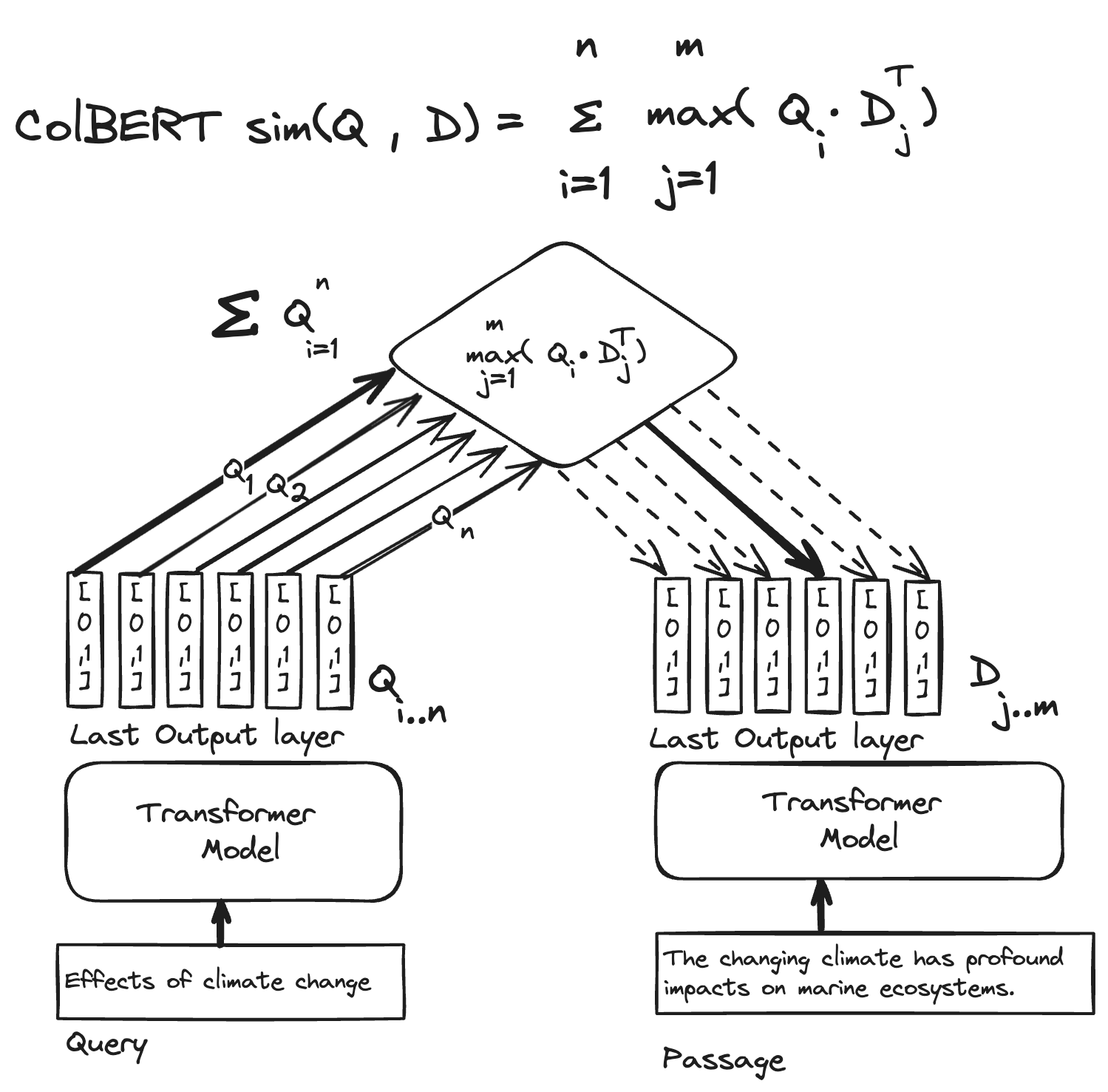
向量embedding搜则有多个子任务,如NL2Code, Code2Code, Code2NL等,每个还有一些细微差别,这个很有意思,待会讲;
码仓index呢,则大致有两种:一种基于传统的AST分析,希望构建整个码仓的符号树或者CKG来辅助搜,另一种则寄希望于新型的生成式大模型,希望让LLM读了仓库之后能生成”索引“,典型的做法比如deepwiki。
搜索引擎式
传统的搜索引擎其实在代码搜上有很多问题,参见
最严重的问题甚至不是想象的NL2Code的问题,而是传统搜索引擎的部分优化不够、部分优化又不足,总之不与代码适配
- 索引的开销, 恐怖的内存消耗
当我们第一次部署 Elasticsearch 时,需要几个月的时间才能索引 GitHub 上的所有代码(当时大约有 800 万个存储库)。今天,这个数字已经超过 2 亿,而且代码不是静态的:它不断变化,这对搜索引擎来说是相当具有挑战性的。
- 可不可以不要索引?对大规模库高并发是不可能的:
首先,让我们探讨一下解决问题的蛮力方法。我们经常收到这样的问题:“你为什么不直接使用 grep?为了回答这个问题,让我们使用 ripgrep 对这 115 TB 的内容进行一些数学计算。在具有八核 Intel CPU 的机器上,ripgrep 可以在 2.769 秒内对缓存在内存中的 13 GB 文件运行详尽的正则表达式查询 ,即大约 0.6 GB/秒/内核。 我们很快就会发现,这对于我们拥有的大量数据来说确实不起作用。代码搜索在 64 个核心、32 个机器集群上运行。即使我们设法将 115 TB 的代码放入内存中并假设我们可以完美并行化工作,我们也会在 96 秒内使 2,048 个 CPU 内核饱和,以处理单个查询!只能运行一个查询。其他人都必须排队。结果是每秒 0.01 次查询
-
分词器不需要了:搜索引擎依赖分词来减少构建倒排的成本和作为基础搜索单元,但就和Tokenizer的引入一样,这个开销的减少从来不是免费的,接下来的问题就是:代码如何分词?另一个问题是:停用词全部没用了!无论是
!@?/#$:{}()[]还是什么别的乱七八糟的符号,都是编程语言的最爱, 这使得传统的分词系统更加雪上加霜- 如果提前跑一遍AST分析呢?我们的CPU要算爆炸了
:), 并且你如何统一没有LSP小众语言,不同的语法版本(py2->3)... 工程量立刻爆炸了 - 能不能在char level倒排?太爆炸了索引,所以github是使用3-char的倒排的
argument -> arg、rgu、gum、... - 代码里面还有注释,注释还有多语言,甚至单个仓库都很常见中英两种语言的注释...看起来朴素的分词器比如jieba要全面阵亡了...
- 如果提前跑一遍AST分析呢?我们的CPU要算爆炸了
-
基于git的增量更新:增量更新本身可以用merkel tree,这也是cursor在用的技术,但结合git版本?你发现事情变得复杂起来了,这是纯工程的复杂性。一次git commit涉及到十几个文件的几行变化,需要触发至少十几个chunk的embedding更新?如何处理多分支呢?我的每一个存储代码块是否还得加一个tag标识它的branch,然后在搜索引擎里面支持完备地按tag过滤,省的不同branch的代码在同一个搜索引擎中返回?(然后发现branch name作为tag简直太烂了,它是一个完全动态的无限的集合)
鉴于恐怖的存储代码数量,github采用的搜索引擎相当简陋,甚至是弱化版本的完全匹配:3-grams索引
对于代码搜索,我们需要一种特殊类型的倒排索引,称为 ngram 索引,它对于查找内容的子字符串很有用。ngram 是长度为 n 的字符序列。例如,如果我们选择 n=3,则构成内容“limits”的 ngram 是
lim、imi、mit、its。(二元组的选择性不够,四元组占用了太多空间)
这个索引显然是非常大无法放入内存的,所以github采用了一些传统数据库里面的懒加载和流式优化技术,使得可以仅读取一个小子集完成搜索
而关于构建索引本身,github还有很多特殊设计,但这其实属于system/后端任务了,不细讲:
-
用Git blob object ID来分片,kafka分区
-
用path, branch, repository + 元信息(owner, visibility, etc.) 来构建增量索引key
-
commit-level的一致性
-
Github相当多的blob是相同的,使用增量编码很有吸引力, 这里用到了概率上的近似数据结构和一些分布式图(近似)算法
To determine the optimal ingest order, we need a way to tell how similar one repository is to another (similar in terms of their content), so we invented a new probabilistic data structure to do this in the same class of data structures as MinHash and HyperLogLog. This data structure, which we call a geometric filter, allows computing set similarity and the symmetric difference between sets with logarithmic space. In this case, the sets we’re comparing are the contents of each repository as represented by (path, blob_sha) tuples. Armed with that knowledge, we can construct a graph where the vertices are repositories and edges are weighted with this similarity metric. Calculating a minimum spanning tree of this graph (with similarity as cost) and then doing a level order traversal of the tree gives us an ingest order where we can make best use of delta encoding. Really though, this graph is enormous (millions of nodes, trillions of edges), so our MST algorithm computes an approximation that only takes a few minutes to calculate and provides 90% of the delta compression benefits we’re going for.
Grep
grep属实是在Coding Agent时代焕发了第二春,由于其系统级别自带+完美匹配Bash工具和Unix文本管道的特性,在现代的LLM之中都大量训练了如何写出各种米奇妙妙grep的数据
claude code这种经过更多优化的grep会更过分一点,它会有几个细节优化:
- 使用更现代的
rg(riggrep)代替原始的grep - 逆向cc源码可知,它的grep有七八个参数,分别对应grep里面的不同参数比如
-A-E-C, 除了一些呈现格式(比如带不带行号和文件名)之类的差别,主要的几个参数就是在匹配行前保留多少行、匹配行后保留多少行、和上下保留多少行- 如果读者熟悉coding agent的工作的话,其实早在swe-agent就已经探究过这个context window开多少的问题,原始论文的实验结论是50行
❯ tldr grep
grep
Find patterns in files using regular expressions.More information: https://www.gnu.org/software/grep/manual/grep.html.
- Search for a pattern within a file:
grep "{{search_pattern}}" {{path/to/file}}
- Search for an exact string (disables regular expressions):
grep {{[-F|--fixed-strings]}} "{{exact_string}}" {{path/to/file}}
- Search for a pattern in all files recursively in a directory, showing line numbers of matches, ignoring binary files:
grep {{[-r|--recursive]}} {{[-n|--line-number]}} --binary-files {{without-match}} "{{search_pattern}}" {{path/to/directory}}
- Use extended regular expressions (supports ?, +, {}, (), and |), in case-insensitive mode:
grep {{[-E|--extended-regexp]}} {{[-i|--ignore-case]}} "{{search_pattern}}" {{path/to/file}}
- Print 3 lines of [C]ontext around, [B]efore or [A]fter each match:
grep --{{context|before-context|after-context}} 3 "{{search_pattern}}" {{path/to/file}}
- Print file name and line number for each match with color output:
grep {{[-H|--with-filename]}} {{[-n|--line-number]}} --color=always "{{search_pattern}}" {{path/to/file}}
- Search for lines matching a pattern, printing only the matched text:
grep {{[-o|--only-matching]}} "{{search_pattern}}" {{path/to/file}}
- Search stdin for lines that do not match a pattern:
cat {{path/to/file}} | grep {{[-v|--invert-match]}} "{{search_pattern}}"
另一个有趣的事情是,现在的coding agent不约而同地使用了grep而不是rag作为其系统原生的工具,我觉得理由也是非常清晰的:
- grep的输出是标准可预测的,而rag的输出依赖于
{基础模型, 分块方法,召回topk,重排模型}等多个配置参数,一个标准的输出带来的好处是 可强化学习, 如果对一个 code llm + rag 的系统做RL,最后的搜索策略一定会是拟合到和rag的embedding模型和具体策略相匹配,丧失了可迁移性 - 除此之外的好处也有很多,比如RL环境不需要embedding的额外开销(存储和计算上甚至编码成本上),整体轨迹可解释,精确匹配效果好,速度快...
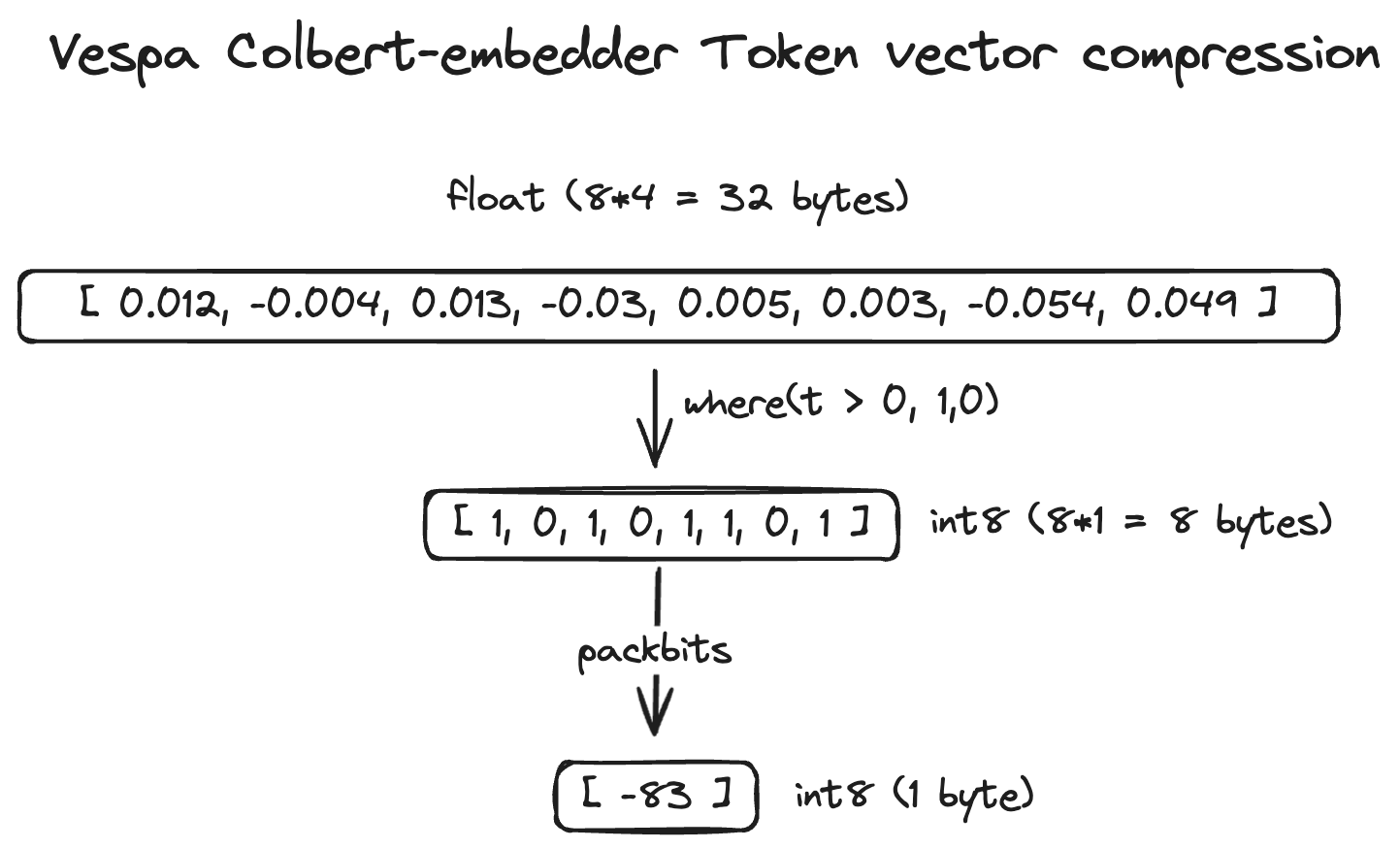
rag的index开销其实相当大,学界不在乎这个,为了提升精度每个token一个embedding的方法也有,但一个embedding是一个1024维的向量,光存储开销就是4KB,对于百万行级别的代码仓库,其chunk可能在数万,达到了GB级别的存储开销
而工业项目有百万码仓,在TB级别的存储上进行高效地索引和查询着实压力很大,可以参考 美团和milvus/lancedb的相关文章 ,索引优化也有相当多的新实践,但这是做DB的人考虑的(雾
但Grep就是万灵药吗?并非如此
Grep提供了一个切面,能够让模型Agentic Search,根据搜索到的局部反馈调整搜索方法,从部分开始探索整个代码仓库——大部分需求的完成不需要对全仓的理解
——吗?
一个Grep的bad case是高阶语义的需求:
- 哪里导致了这个bug?
- 某个模块的核心逻辑是什么?
- 整体的代码结构?
- ...
模型要么老实cat,要么就只能在log中见到它尝试“猜”你的变量名字,比如你问“...的实现”就会开始Grep impl,如果你把所有变量换成abcde,它立刻就GG了
比起失败的搜索浪费的上下文更糟地是浪费的交互轮数 —— 长达几百轮的agent轨迹是相当稀少的训练数据,如果再配合没那么好的历史压缩方法,或是没有精心设计的防止模型死循环的额外环境反馈,连续失败的grep会让agent的性能迅速地劣化
基于这方面的需求,在推理阶段Grep还是得配合别的工具,比如deepwiki,比如CKG(代码知识图谱,例如每个函数的caller和callee),
比如Code RAG
这方面也有一些新的探索,例如 https://cognition.ai/blog/swe-grep 的RL并行工具调用(关键不在速度,关键在减少交互轮数!),比如在工程侧融合Grep和RAG如https://github.com/daimh/mgrep 和 https://github.com/zilliztech/claude-context ,以及我们将要发的一篇文章(自吹自擂一下,关注主包后续的工作谢谢喵)
code embedding
主包主包,code embedding和文本的embedding有什么区别呢?为什么要强调code?
非常好问题,爱来自AI4SE。我认为code其实和图像比较像,某种意义上算是一种特殊的模态,不完全是文本—�—code某种意义上是“反语言常理”的,例如大部分语言的上下文有限,一句话很难和1000个字之前的某个东西形成强烈的联系,而这种长程交互在code之中非常常见——甚至有跨文件、跨模块、跨仓库的交互
而另一个很有趣的事情是,当我们在讲“某段代码的语义”的时候,这件事本身是模糊的,文本没有那么强的二义性,太阳就是太阳,月亮就是月亮,但一个递归斐波那契函数的语义到底是 “递归“ 还是 ”斐波那契“?这其实折射出了代码的某种特殊性,它同时具备字面义 ”斐波那契“ 和运行义 ”递归“(甚至”低效“、”算法“、“python”),而在一个代码仓库之中,代码还具备了上下游的属性:谁是我的caller,谁是我的callee?
这件事情为什么重要呢,因为传统的embedding向量相似度产出的是一个标量,它只能衡量一个维度的相似性!
- 当你在说“查找与function A相关的代码”时,你想要的到底是什么?
- function A的字面义相关的代码?
- function A的运行效果相关的代码?
- function A的caller/callee?
- ...
然后你就发现从这个角度上来说,Code2Code的向量搜是很诡异的一件事情,至少传统的cos相似度无法干这件事——
- 更悲伤(从学术研究的角度上来说或许是兴奋)的是,在现实需求中,我们真的不在意找到和一个function的字面意相关的function...假设你想要补全一段代码,你可能更需要关注谁会是它的caller,假设你需要优化一段代码,你可能搜索的方法是某种低效的pattern...而这些embedding相似度全部做不到
- 据我所知,企业对这个接近摆烂了,只有MSRA有一个group还在研究,我之前��溯源到的比较早的上下游建模技术是Order Embedding,感兴趣的或许可以试试做
直接结果是:我们只有NL2Code了
并且这个NL也只能关注一个方面...
什么样的NL才是真实会问会写的NL呢?Coding Agent的轨迹数据
没有轨迹数据怎么办?从大规模代码中挖掘注释作为NL
一个人写注释的方法和提问的方法不一样,这个语义空间的unmatch如何处理?各家自显神通
-
例如2025年5月快手的OASIS: Order-Augmented Strategy for Improved Code Search,认为现有的code embedding往往关注的是代码的字面相似性,即只把代码认为是一种特殊的“语言”,而忽略了代码的非文字意义上的相似性
- 对代码片段(结合其他静态分析信息),用LLM产生其作用的描述文本
- 计算这个描述文本和其他代码片段的相似性,以此来挖掘难负样本
- 因为这个文本描述的是相对High Level的函数作用,能够一定程度上避免变量名字等带来的影响,专注于实际作用
-
24年12月的Nomic AI的cornstack
- 强调
<文档,代码>对的相关性重要性,并采用双重过滤:如果文档与代码间相似度低,或者并不在topK,只要有一个满足就筛掉 - 动态硬负例挖掘策略:对于批内负样本挖掘,采用softmax概率采样,但是在训练过程中,逐步改变softmax的温度,前期温度高提高多样性,后期温度低,注重难负样本的区分
- 强调
-
25年5月的BAAI Towards A Generalist Code Embedding Model Based On Massive Data Synthesis
- 强调退火训练,第一阶段纯文本,第二阶段全数据训练text-code能力,第三阶段纯代码
码仓Index - DeepWiki/CKG
这个说起来就比较简单了,deepwiki重要的始终是LLM的能力,而CKG则是静态分析的质量,开源的tree-sitter固然可用,企业也有一些统一各种语言的私有AST,静态分析已经日趋成熟,困难的是如何将这个信息给到LLM?
很早在Google的博客中就有论述: 现在的vibe coding就像是把一个几千行的代码粘贴到记事本里面,然后让程序员来修改bug —— LLM看到的就是 “记事本”,而不是程序员的带有各种Lint和跳转的IDE界面
AST分析树如此庞大,除了摆烂式地提供一个获取caller/callee的mcp工具给agent之外,还可以做些什么?
先前在web领域有一个llms.txt的旨在LLM-friendly的格式,代码领域却暂时缺乏哪怕是新兴的统一处理格式
AI-friendly IDE可能对于Coding Agent的能力提升相当重要,这也是moonbit社区他们宣传的,不过我没有实际上手用过,也不是学PL的,就不瞎讲了,感兴趣的可以看张宏波的演讲
【AI时代下的基础软件 | 张宏波 刘子悦 蚂蚁&MoonBit Meetup杭州站回放】
https://www.bilibili.com/video/BV1wL8DzgEXZ/
除此之外,可能我们原先认为不能搜索或者没必要搜索的部分,现在也正在发挥着额外的作用:
- python的package,众所周知(可能并非),pip包只是一个特殊的压缩包,可以直接看到文本格式的原始代码,现代的claude-sonnet-4等模型在环境出错的时候会主动读/搜
pyproject.toml,.venv等特殊文件,遇到import的不了解api还会尝试进入package观看源码 - 而某些binary风格或是一串神秘哈希引入的包可能对于LLM并不是很友好...
除此之外也有很多新兴的想法,例如注释本身可不可以作为一个天生的码仓Index? ...
CLI版本的Coding Agent好处是可以在各处方便的引用,尤其利于大规模并发采集数据
但IDE版本的Coding Agent则会更加地“懂人”,原因是AI IDE在背后做了一大堆不仅仅是diff等格式渲染的工作,用户环境信息,用户系统信息,... 这些都被从后台塞入了Coding Agent的system prompt,使得你在Linux上运行Copilot的时候,模型不会让你执行 brew install命令
但文本本身依然有着局限,或许在某个未来,我们能看到真正的code native架构,不在绞尽脑汁地想把编译器的报错,AST的分析等等原本结构化的东西转成markdown再塞入永远不够的agent上下文...