CS144 Lecture Notes
Unit 1: Internet and IP
网络四层模型:application, transport, network, link
7层OSI, 拆app,trans,link为更细的两个
网络的基础和底层是IP, 只有IP model是不可替代的“细腰”,上层的application、transport和下层的link都是可以替换的
application 应用层,smtp, ftp, http, ssh
transport 传输层,tcp, udp, rdp
link 连接层,4G, WiFi, ...
网络连接的几种常见例子:
client-server, BitTorren 一服务器多client的集群, ......
网络 application上 :read/write
传输过程 app->...->link->(link->network->link)(router) ->... link->...->app
IP(Internet protocol) service model:
设计目标:简单甚至笨拙,端到端(end-to-end),意味着尽可能减少中间router的工作量,能放在end的计算机上的都放在end的计算机上。对上下做非常少的假设。
几个特点:
- Unreliable(不保证能传到) 由上层的协议,如tcp来实现重传等确保传到
- Best effort: 尽量传到,只有在必要时才丢弃数据包(什么是必要时?例如中间路由器满了无法处理新请求)
- Datagram:传输的每一个包(packets)都是自路由(individually routed),也就是保存了
Src_IP和Dst_IP不需要依赖其他包来传输,同时传输依靠路由器一跳一跳(hop-by-hop) - Connectionless: 无状态,包的顺序可以被打乱,发送和接受也没有要求“建立连接”
一些细节:
-
Tries to prevent packets looping: packet内简单对跳转次数计数,达到某个值时router会丢弃
-
大数据包会拆成多个 (fragment)
-
使用IP 标头校验是否发送错误和重新组合
-
允许加入新字段
IP 标头

大部分字段都是不言而喻的,flags和fragment offset用于拆分数据的重新组合,checksum是标头的,用于检测是否损坏,protocol ID根据ID指定协议,比如TCP, version指定IPv4, TTL用于跳转计数避免循环,type of service是一个服务器标识符,用于表达这个包的重要性
可以用traceroute查看包在路由器中的路径
TCP Byte Stream
通过{IP, port}来通信,中间过计算机或者router, 例如wifi第一跳是过wifi接入点路由器
路由器转发:转发表模式匹配(最大前缀匹配)
如果在地址匹配过程中,不能和路由表中任何条目所匹配,packet将被丢弃。
【一个名为 Destination Unreachable(目标不可达)的ICMP信息将发回给源地址】
TCP 三次握手(3-way handshake)
- client \-> server SYN 请求
- server \-> client SYN/ACK 确认请求
- client \-> server ACK 确认请求
packet switching:
Independently for each arriving packet, pick its outgoing link. If the link is free, send it. Else hold the packet for later.
早期的跳跃是这样的,每一个路由器将src_ip改成自己(这就是NAT,网络地址转换,将大量的私有IP隐藏在少量公有IP里面),然后继续往下走
安全网关处于私有网络和公有网络的连接处。当内部PC(10.1.1.2)向外部服务器(202.1.1.2)发送一个IP包1时,IP包将通过安全网关。安全网关查看包头内容,发现该IP包是发向公有网络的,然后它将IP包1的源地址10.1.1.2换成一个可以在Internet上选路的公有地址202.1.1.1,并将该IP包发送到外部服务器,与此同时,安全网关还在网络地址转换表中记录这一映射。外部服务器给内部PC发送IP包1的应答报�文2(其初始目的地址为202.1.1.1),到达安全网关后,安全网关再次查看包头内容,然后查找当前网络地址转换表的记录,用内部PC的私有地址10.1.1.2替换目的地址。这个过程中,安全网关对PC和Server来说是透明的。对外部服务器来说,它认为内部PC的地址就是202.1.1.1,并不知道10.1.1.2这个地址。因此,NAT“隐藏”了企业的私有网络。
但安全问题比较大,路由器不希望目标知道自己的ip, 就改成全dst, 每次跳跃都将src改为下一跳的ip
结果
- 简单的packet传播
- 高效的链接共享
No per-flow state required:
两端不需要知道router的state, router不需要存储其他的state(因而不需要考虑清除错误的状态)
由于是以包作为最小单位,链接共享和流量分配很简单->根本不需要管谁传过来的,有包就发
Layering 分层:
seperation concerns
模块化,重用,明确的上下边界,关注点分离,Peer-to-peer communication
装包是灵活的
VPN example
从里到外HTTP data \-> TCP(to web) ->IP(to web) \-> TLS(to VPN)->TCP(to VPN)->IP(to VPN)\-> Ethernet(to next hop)
字节序,内存:网络字节序,大端序
IPv4
32位 a.b.c.d 192.168.0.1
netmask 子网掩码:apply this mask, if it matches, in te same network (if IP_A & mask == IP_B & mask,在一个子网里面)
例如 netmast 255.255.255.0 意味着前24bit match
第一跳时,如果Src_IP 和 Dst_IP在同一子网内,不走外面路由器 \-> 127.0.0.1 和 127.X.X.X
> ifconfig
...
inet 127.0.0.1 netmask 255.0.0.0
...
地址结构(historical):

问题:不够灵活
目前:CIDR Classless Inter-Domain Routing
171.64.0.0/16 /16意味着16位子网掩码,171.64.0.0 ~ 171.64.255.255都是
ICANN ip地址分配
Longest Prefix Match(最长前缀匹配)
转发表实际上是 a set of CIDR entries
| dest | link |
|---|---|
| 0.0.0.0/0 (x.x.x.x, default, 每个router都有) | 1 |
| 171.33.0.0/16 (171.33.x.x) | 5 |
Address Resolution Protocol(ARP) 地址解析协议
解决问题:我有IP, 那发送到哪个硬件?(Link层,描述特定网卡,有唯一ID)
eg 48bit Ethernet 00:13:72:4c:d9:6a
例如,有一个网关gateway交换机,他有不同的接口,对应不同的ip
从IP_A -> IP_B的内部请求,IP_A先由子网掩码把请求发到gateway接口A, gateway识别packet的dst_IP之后通过接口B发出,再由子网掩码发送到IP_B
ARP link 和 network层之间,缓存 ip <-> link 地址的mapping
简单的 request-reply 结构
要发送消息给ip X, 先查缓存, 如果没有, sent request to link layer broadcast address “谁有IP X?”
当IP_X接收到数据的时候给Src发“我有IP X"(不走广播)
Unit 2: Transport
The TCP Service Model
Reliable byte delivery service
- Acknowledgments indicate correct delivery
- Checksums detect corrupted data
- Sequance numbers detect missing data
- Flow-control prevents overruning receiver
- Congestion Control 拥堵控制
TCP Segment Format
Unique TCP connection: IP DA, IP SA, Protocol ID="TCP", Source Port, Destation Port

通过sequence 和acknowledgment sequence可以确定前N个字节已经正确发送,sequence是TCP Data的首个字节在TCP试图发送的字节流中位置
FIN flag 标志关闭,关闭TCP连接的过程就是一方A先发FIN, 关闭A-\>B的管道, 之后B确定发送完数据后发送FIN到A, 关闭B到A管道。 PSH指示立刻发送新数据而不是等待更多老数据
window-based flow control
retransmission and timeouts
UDP Service Model
UDP 标头只有四个段:
Source Port, Destination Port, Checksum, Length
No connection established
Packets may show up in any order!!!
没有确认,没有检测丢包和乱序的机制,没有流量控制
ICMP Internet Control Message Protocal
Communicates network layer info between end hosts and routers
Reports error conditions
- Reporting Message
- Unreliable - no retries
典型的ICMP IP header | ICMP header | ICMP data
ICMP header里面主要就是 type 和 code, 两者合起来描述了一个message(通过对照表, 例如 )
| 0-Echo响应 | 0 | Echo响应报文 |
|---|---|---|
| 3-目的不可达 | 0 | 目标网络不可达报文 |
用于 ping, traceroute等
traceroute怎么实现?很精巧的设计
clientA-\>B A发送一个TTL为1的UDP message,然后第一个router接受,TTL为0, 决定丢弃并回传一个ICMP消息
| 11-ICMP超时 | 0 | TTL超时报文 |
|---|
clientA拿到这个报文就得到了第一个router节点的信息,之后就可以发送一个TTL=2的...以此类推
End-To-End Principle
Error Detection
- Checksum:简单将data 加和,弱但快
- CRC校验:计算多项式余数 强一些,慢一些,纠错一位,查错2位
- 消息验证码MAC -> TLS, 需要密钥 剩下的一点问题在与一个k位的码如果发生单位翻转,有2^-k的可能检测不出来,从这个角度上可能不如CRC
IP/UDP/TCP Checksum: 报头中所有其他16位字的反码和的16位反码
检验,整个IP标头的求和结果应该为0(修改标头比如TTL时需要重新计算)
快,但只保证查1位错
Link Layer广泛使用CRC
MAC
有限状态机 FSM

Flow Control
sender可以send 500000个packet/s
receiver 只能receive 200000个
原则是sender减少发送的包数量,receiver give feedback
- stop & wait sender发一个就等一个ACK, 除非超时没有接受ACK重发,receiver接一个回一个ACK
有一个问题是ACK Delay
如果sender发了一个包A0,但ACK在timeout了,尝试重发A1后才收到,于是sender继续发下一个包B0,sender如何区分此时接受到的ACK是A1的ACK还是B0的ACK?
一种部分的解决方法是加入一些标志位来标识是这个packet是复制还是原始数据,但还是有一些问题,例如这样假设了网络传输的数据不是复制的,还有无法解决长延迟的问题(假设有k个标志位,最多记录第2^k^次重发,如果有超过2^k^次timeout的延迟,就还是会出现无法区分重发和新包的问题)
当然通过动态调节timeout和把ACK做成一个够长的标志(比如下面的序列号)是可以做的,比如下文的滑动窗口就是stop & wait的泛化,
linux 下这个timeout被动态地(通过测量发出到ACK的时间采样等方法)调节为略大于传输时间,为了处理网络的波动性,如果发现一个包重传之后还是丢,就把timeout设置为原来的2倍
对于重复的更优处理还会有SACK字段(选择性确认),receiver回传数据表明哪里是复制了,sender知道之后就继续发送了
更大的问题在于速度,假设两地有50ms延迟,来回100ms, 一个包比如1.5KB, 这样的网络最大只能有15KB的速率!
- sliding window
允许多个未确认的片段 (multiple un-acked segments)
将一些绑起来的片段叫做window,始终保持管道速率拉满
什么意思?原先只能有1个包在路上,现在可以有n个
Sender
每个片段都有一个序列号(SeqNo)
维护三个变量:Send window size(SWS),Last ack received(LAR), Last seg sent(LSS)
维持的要求:LSS-LAR <= SWS, 保证�中间飞的包 <= SWS 个 (一个SWS大小的buffer
Receiver
还是维护三个变量:RWS, last acceptable seg(LAS), last seg received (LSR)
要求 LAS - LSR <= RWS, 也就是说如果窗口是5, 上一个接受的是3, 不会接受9以后的SeqNo的包,并且 LAS <= LSE + RWS都接受,也就是说9之前的都是可以的,比如2,会接受并回一个ACK = 下一个字节
也就是说 第一个包假如是 0-999字节 ACK 就是1000
下文中 ack 忽略掉这个值区别 包1,ACK1只表示逻辑上的第一个包和第一个ACK
(逻辑上下一个包,例如发送1,2丢,345,回的ACK是1 222)
如何知道包丢了
目前的方法就是等超时,例如2丢了一直等ACK 3,到timeout了重发2
有没有更好的方法呢?比如我在发12345,2丢了,回ACK1 222, 连续3个2表明确实是2丢了,那就可以不用等超时立刻触发重传(TCP快速重传)
那如果ACK丢了呢?
如果是前面的ACK丢了无所谓,最后一个ACK就表明这个之前的所有都已经接受,不然就重发呗
重传多少?
- Go-back-N 一个包loss,整个window重传 对网络情况悲观
- Selective repeat 只发loss的 对网络情况乐观
看实际情况,不一定哪个快,这是一个trade-off
RWS <= SWS
所以这里面的
window size就是滑动窗口的大小,Seq 和 ACK Seq就是上文所述的序列号
一个发送第4000-4999字节的包,seqNo会是4000, Ack会是4999+1=5000=下一个包应该的seqNo
RSVD: reserved
Hlen,也叫offset,表明data段从哪里开始
Flags:ACK表示ACK 是否有效(第一个发出包的ack就无意义,其他都有意义), SYN/FIN 位掌管TCP连接(第一个包, ack not set,syn set)
所以后面传回的就是syn/ack ,从第二个包开始就结束了syn且有合法ack,就是ack
RST: reset the connection
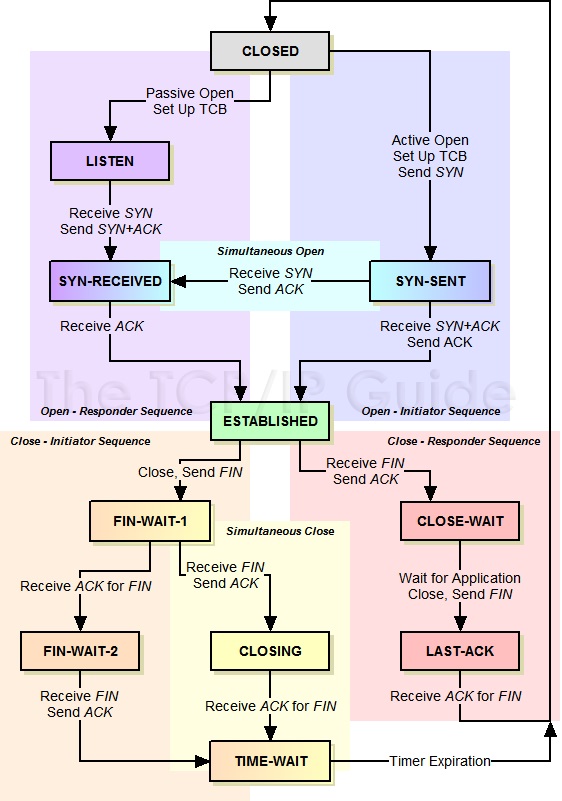
TCP Setup/Teardown
Setup
需要注意的是,seqNo通常不从0开始(安全原因),所以第一次握手
active 带上 {SYN, SA} (A means active) 我的序列开始是Sa
passive 回复{SYN, SP, ACK, Sa+1} (P means passive) 表明我的序列开始是Sp
active 回复 {Sa+1, ACK, SP+1}
以上为 0字节 data
Teardown
使用FIN bit
A->B FIN,seq Sa, ack Sb
B->A ack Sa+1
B->A FIN, seq Sb, ack Sa+1
A->B ack Sb+1
cleaning up safely
如果teardown的部分(final ack)丢包怎么办?-> 不管丢不丢,在发出FIN之后,active 都会到TIME_WAIT状态,大约会keep socket twice the maxium segment lifetime,之后关掉并重置
Unit 3: Packet Switching
Circuit Switching 电话
Problems
- Inefficient (for brusty req)
- Diverse Rates
- State Management
Packet Switching
-
通过路由表独立路由
-
所有的包共享相同的最大连接速率(router需要大buffer来收包)
-
router无连接状态
好处:
- efficient use of expensive links 共享速率使router不闲置
- resilience to failure of links & routers, no state -> 轻松切换线路
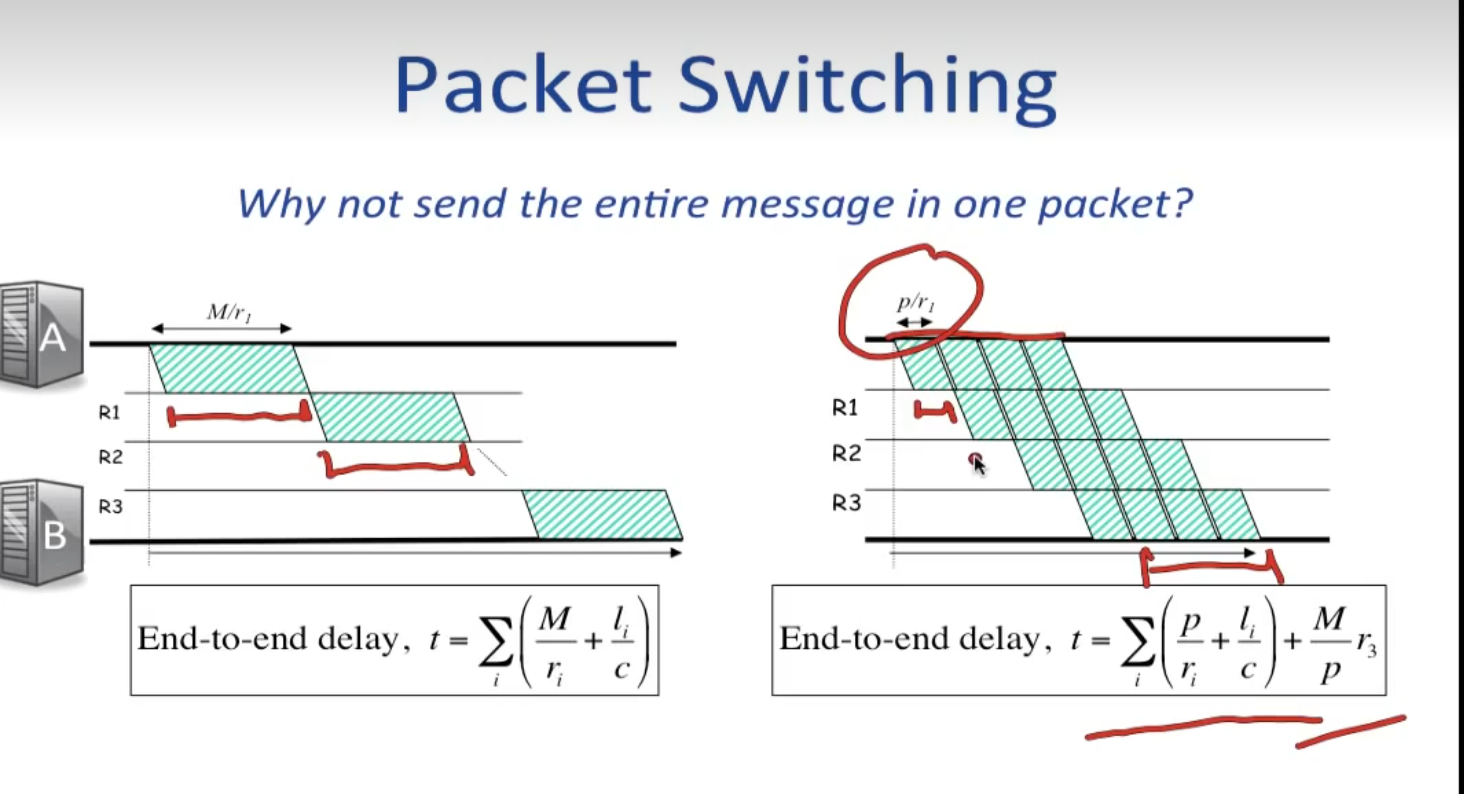
Delays
Propagation Delay 距离 l / 光速c
Packetization Delay 包长度p / 每秒能放到连接上的bit数r
Queueing Delay 在路由器的buffer queue之中排队等待发射时间
End-to-end delay 对所有经过的router ri
前两个是固定的,queueing delay是随机的,导致了端到端时间具有一定的波动性
Real-Time Apps 为了避免queueing delay带来的体验下降,会引入
Playback buffers 视频缓冲区
playback buffer -> video decoder -> screen
也不是固定值,会增大buffer来尽量不要停
queue model: FIFO
需要注意的是字节数随时间的变化是分段的(包一个个来),近似可以认为每一段是直线
Small packet help reduce end-to-end delay
小包的情况下 各个中间router的Queue delay + Packetization delay可以并行,如图,类似cpu流水线, 关键是一个包是最小传输单位
Statistical Multiplexing Gain
由于从一个link输入的packet的速率A具有波动性和随机性,设要使他不丢包需要R的输出速率
假设有另一个link 输入B, 也需要R,同时接受AB的路由器需要的输出速率R' < 2R, 因为AB的最大值时间点大概率不重叠
让我们在处理多路流量的时候反而更高效
Queues With Random Arrival Processes
-
Burstiness increase delay -> 包不重叠,平均delay低
-
Determinism minimizes delay -> 如果queue为空,就无法利用输出,不确定的到来时间加剧拥挤
-
Little's Result 平均到达率 平均排队者数量L,平��均排队延迟d, L =
-
M/M/1 queue
将收包事件近似为泊松过程,相互独立且t时间内到达的包数n, E(n)=
(注意网络包实际很突发,不是泊松过程,但这个model work for new flows, 新连接是近似泊松的)
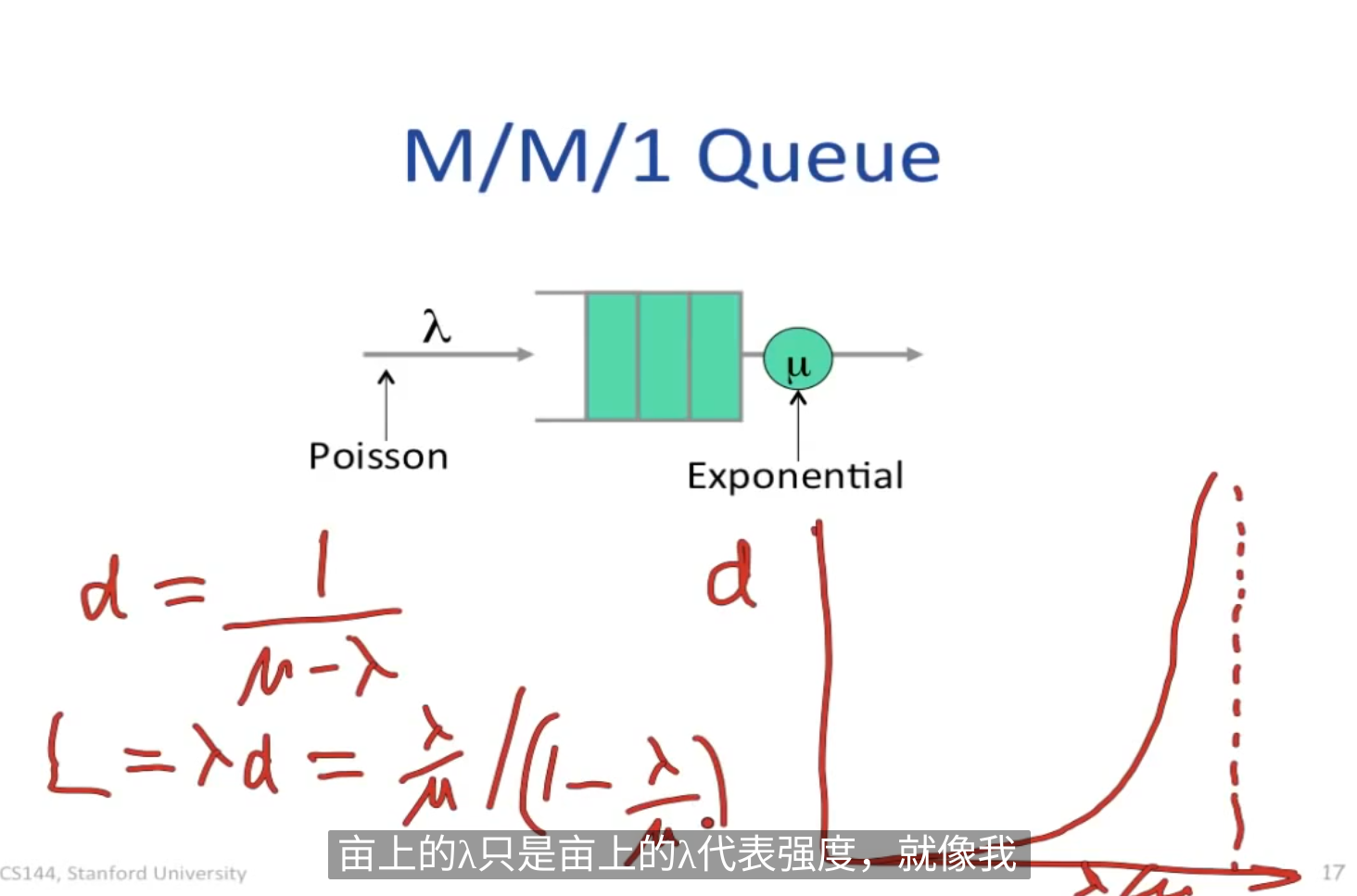
当入包速率接近出包速率时,等待时间会大幅度上涨
平均排队者数量就是
packet switch 交换机
一个包来之后 -> 查地址 -> 更新header -> 进入排队 -> 发送
Internet router
1, 如果DA 不等于自己,丢
2, 检查ip version和datagram长度
3, 减少TTL, 更新校验和
4, TTL == 0?
5, 查路由表, IP DA决定下一��跳, 找到对应的Ethernet DA, 发送到电线
IP match -> binary TRIE 或者 三进制可寻址内存-> 01X暴力并行比较,很快
Ethernet match -> hash
Input Queued Packet Switch
一个有 N 个输入口的交换机,每发送一个packet耗时R,最坏情况下的输出delay是(N+1) * R (假设输出速率足够大)
如果把排队放在输入,最坏情况下delay,理想状态下可以降低到2R
但问题是,如果马上要输出的几个包是同一个输出口,一个输出口同时只能输出一个,就和原来的没有区别了
一种解决方法是Virtual Output Queues,在每个输入口都做M个队列,M是输出口的数量,每次输出都从M个不同的输出口取
举了一个有趣的例子是红绿灯车道,车在进入路口前(“输入口”)分好队列,同时输出的就可以增加,排队时间就可以减少,但要求的道路宽度变多
FIFO的问题和其他选项
经典排队问题,如果有一个大包堵着,所有包的排队时间都会增加
strict priority
很符合直觉,同一个输入口再来几个队列,并分好优先级,同一个端口接受多个队列输入的时候总是优先取高优先级的包
也是经典问题:饿死,但问题不像sys那样严重,饿死就饿死了(),广泛应用
或者weight priority,解决饿死问题
取每个队列的概率 p = wi / sum(wi) (用Round方法)
考虑到每个包的大小不一样,理论上概率应该应用到字节上而不是包上,但又不能拆开包发送,怎么做呢?
WFQ, 利用我们在知道包大小这个事实
在每个队列计数(virtual_time),权重为w的队列在发送一个size大小的包后,self.vt += size / w, 之后把self.vt push进最小堆
调度下一个包时从最小堆里pop()就行
rate guarantees (Guaranteed Delay)
RSVP RFC2205

给出连接总耗时10ms上界, 传输时间 路程/c = 5ms, 打包时间=每个包的字节数/数据线最大速度 = 0.48ms
剩下最多4.52ms的排队延迟, 分在3个router, 要保证不丢包, 就需要至少 15 Mb * 4.52 / 3ms = 24000bit = 3KB的 buffer
buffer的设计在 “给定一定最大延迟的情况下,不允许丢包”
Unit 4: Congestion Control
堵塞控制
tcp堵塞控制
堵塞是不可避免的
堵塞带来丢包,由于重传等,会带来更多的数据流量,进一步加深堵塞
max-min fair: 不能通过减少另一个流的速率的方法增加其中一个流的速率时
先前的想法
- 简单的在各个可能的router上平均分配流量 问题在于没有任何反馈机制
- network-based 显式反馈ECN,当router堵塞发生的时候,给数据源发送包指示拥堵
- end-host-based 通过在发送端观察网络的行为(发送的请求是否超时?是否丢包?)调整发送速度
实际的TCP采用end-host based
TCP varies the number of oudstanding packets in the network bt varying window size:
Window size = min{Advertised Window(given by receiver), Congestion Window}
AIMD(Additive Increase Multiplicative Decrease)
If a packet receive OK : W <- W + 1/W
If a packet is dropped(at Window size W): W <- W/2
称为tcp锯齿或者AIMD锯齿
需要注意的是,实际上在加的中间过程中,网络速率就已经拉满了,后面再加实际上是在嗅探router的缓冲区大小
single flow AIMD
前期 router buffer空
RTT = constant
吞吐量T=W=dN/dt
dW/dN = 1/W , dW/dt = T/W = const
W,T 正比于t
当W大于输出速率R(常数), router buffer开始积累
dW / dt = R/W ⇒ W = sqrt (Rt+C)
此时吞吐量为R,RTT=k* buffersize+D
趋势上和W相同(但不完全一样,因为T输入=R+buffersize变化率=W/RTT),可以得到buffer size 随时间变化
multi flows AIMD
在多道数据流的情况下,之前的AIMD不是很适用
问题在于减少的时机不是所有流同步的,部分流减少后buffer又不满,其他流就不减少,总体发生丢包的时间就很分散随机,导致宏观上router的buffer一直趋于满的
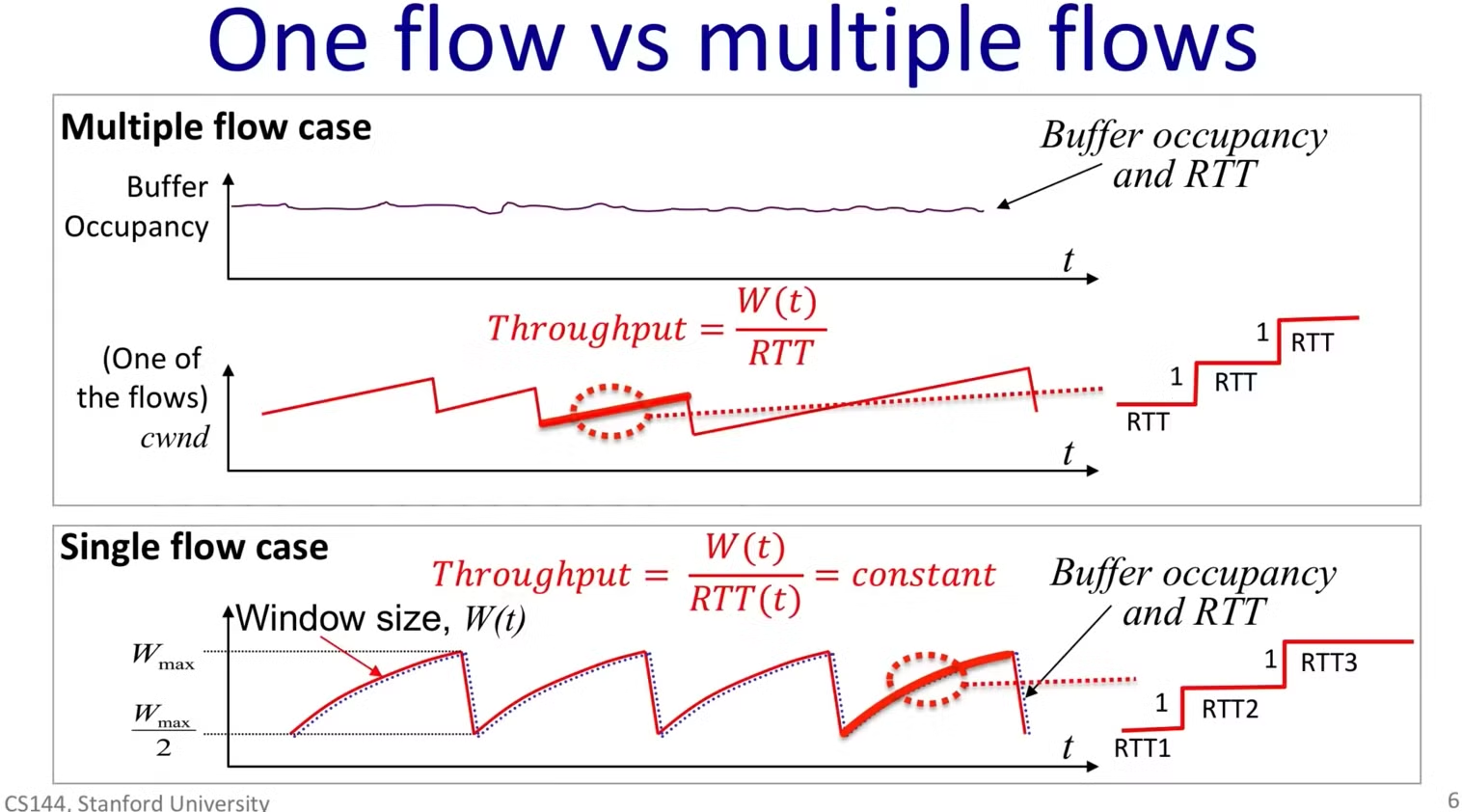
多流时 吞吐量T也不再等于(忽略常数)窗口大小W(多个流的平均)
(buffer始终趋于满的)
总吞吐量近似恒等于R
RTT也近似为常数
那么对于每一个流,都是W/2 → W → W/2的流程
又由于buffer是满的,RTT恒定,dW/dt = T/W = 1/ RTT = const ,直线
平均吞吐 T‘ = 3/4 Wmax/RTT
一次丢包前发送的包数A = 3/8 Wmax^2 ,则丢包率p=1/A
则T’ = sqrt(3/2) * 1/RTT*sqrt(p)
考虑到每个包字节数不同,再乘一个平均字节数MSS
T’ = sqrt(3/2) * MSS/RTT*sqrt(p)
也就是说,AIMD对两个量敏感: RTT(服务器有多远,router 排队时间多大)和 丢包率p
TCP堵塞控制

早期TCP(没有堵塞控制)的问题在于,端的速率超过router的速率太多,receiver返回的windows size实际上远远超过了网络实际能容纳的大小,不断丢包重传
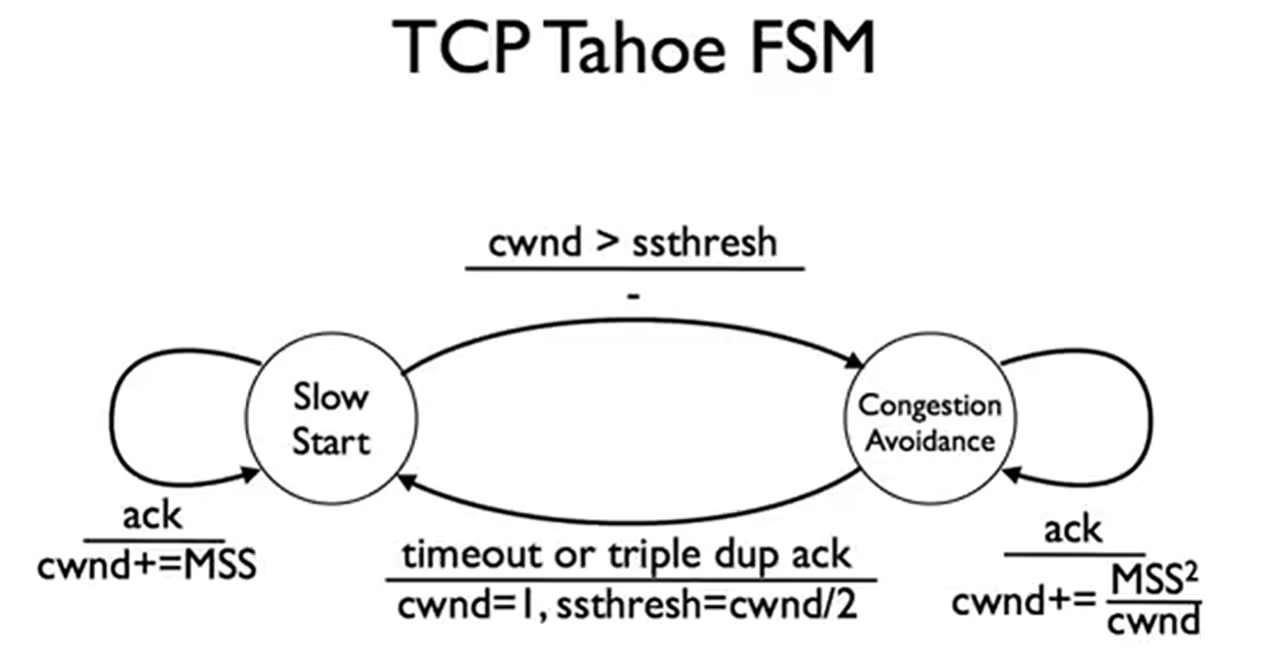
TCP Tahoe: 加上congestion window, timeout estimation和self-clocking
congestion window中的二阶段congestion control
- Slow start:在连接建立或者发生丢包时,AIMD前面线性增加疑似有点太慢了,加速一下
- Congestion avoidance: AIMD
Slow Start
Window starts at Maximum Segment Size MSS
Increase window by MSS for each ACK packet
dW/dt = dN/dt = W ⇒ W = exp(t)
指数增加试探吞吐上限
Congestion avoidance
- Increase by MSS^2/congestion window for each ACK
- Behavior: increase by MSS each RTT
- Linear increase
在两种状态间切换使用3个信号作为信息:
- Inc ACK: 传输良好
- Dup ACK: 发生丢包/延迟
- Timeout: 网络崩溃
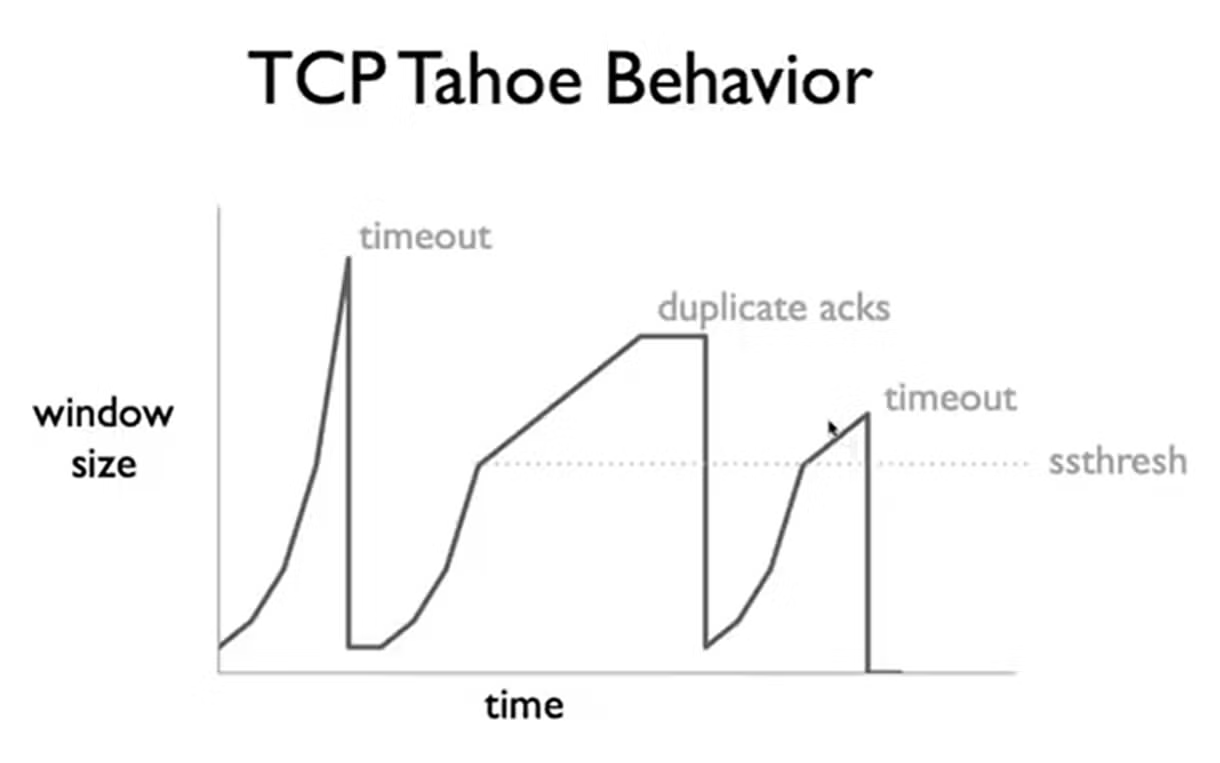
Timeout Estimation
太小,会频繁超时,回到slow start,影响速度
太长,会频繁重发,影响速度
挑战在于RTT是高度动态且负载相关的
早期的算法

问题在于假设了RTT的方差不是很大,但这是不对的
大方差下的RTT会频繁带来过小或者过大的问题

将方差纳入考虑,实验效果好
self-clocking
应该叫一个原则/实现方式,体现为TCP的堵塞窗口不由外部时钟决定,而是根据收到的ACK频率自动改变发送速率(即前面的slow start和AIMD)
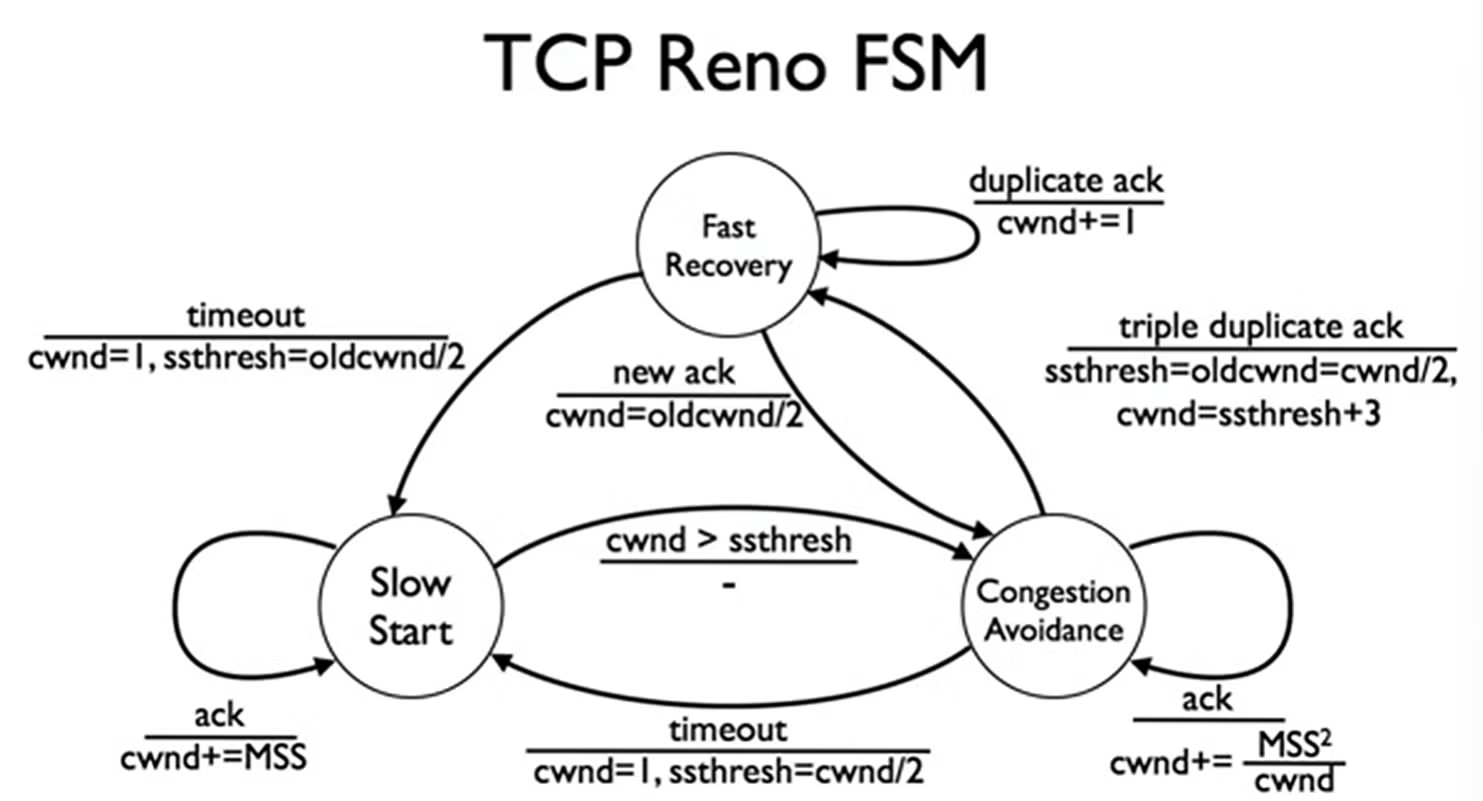
TCP Reno
- 3-Dup ACK�不再返回到1,返回1/2 * Wmax (fast recovery)
- 当3-Dup的时候立刻重传
(不等待重传计时器超时, 并且立刻增大堵塞窗口1/2 * ssthreld + 3,也就是把这个Dup的包立刻加到这一次重传之中,混入正常的发送流,不等待几次RTT扩大window size)
Unit 5: NAT Application
DNS, HTTP, BitTorrent
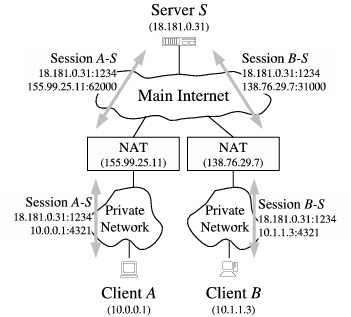
NAT 当内部接口收包时,改写源地址为NAT的外部接口地址
例如家庭wifi 多设备连接实际上共享相同的IP
NAT 原则上是一个map
看看自己的public IP https://whatismyipaddress.com/
还有个内网IP的常识
私有IP地址是在互联网上不被路由的IP地址,专为内部网络使用。私有IP地址范围包括以下几个段:
- 10.0.0.0 - 10.255.255.255:这个范围内的IP地址被划分为一个单独的A类网络,通常用于大型企业或组织的内部网络。
- 172.16.0.0 - 172.31.255.255:这个范围内的IP地址是14个连续的B类网络,常用于中等规模的组织。
- 192.168.0.0 - 192.168.255.255:这个范围内的IP地址是256个连续的C类网络,通常用于家庭或小型企业网络。
NAT 分类
- Full Cone NAT
- Restricted Cone NAT
- Port Restricted Cone NAT
- Symmetric NAT
区别在于Full Cone NAT只是一个map,不做安全检查
允许不是Dst IP的主机通过NAT的外部接��口给内部接口发包,允许外部主动连接内部
Restricted Cone只允许Dst IP的主机发包,同时必须内部先连接外部
Port 就是不仅要求IP相同,还要求端口号也相同
Symmetric 的不同点在内部,在Port的基础上,如果内部一个{IP,port}尝试连接两个不同的外部{IP,port}, NAT会给这个内部的分配两个不同的{IP, port},然后和外部一对一链接
如果不符合要求,有的不翻译,有的会返回一个ICMP错误
Symmetric有一些问题
例如有游戏的多人在线服务器把不同的游戏内地图服务放在不同的端口/IP上来分流,当同时需要两种服务的时候,建立了两个连接,server没有办法知道这两个连接都是同一个东西发出来的(端口不一样)
static mapping
NAT hairmapping NAT回流
例如,在内网中有一台服务器S,其通过NAT暴露给外面的DNS,内网有一个客户端C想要访问S,如果使用DNS的话,得到的是S暴露给外面的NAT IP。这个时候,走外面还是走里面?
NAT hairmapping有多种可能的配置,一种让内部访问走外部,牺牲性能换取对内安全性,一种是主动识别内部到外部的请求,并把它放在内部解决不走NAT
这个例子里面更严重的问题在于如果想要走里面,B向外部IP发送包,却从内部IP接受包,IP不同根本不会接受
NAT带来的问题
例如B想要与NAT后面的A通信,但mapping里面没有,不能主动连,也不会用A的NAT加B的mapping
Connection Reversal, 
公网B->中转R->请求内网A,A->B连接,因为这个请求是反向的(B想要连A,但实际上变成A连B),所以叫Connection Reversal
Relay 中继,A、B都在内网,通过��中继R做转发
要求加密(除非信任R),且消耗服务器性能
NAT Hole-Punching NAT打洞(一般用于UDP)
两个Client都在NAT后面,参考这篇文章https://mthli.xyz/p2p-hole-punching/
主要步骤:ClientA,B给中间公网服务器S注册自己的内网地址,并通过获取对方的公网IP、内网IP, 之后A向着B发请求打通A的NAT(加上B的公网IP的mapping),B向A发请求打通B的NAT(加上A的NAT的公网IP的mapping),之后AB就可以正常通话了(隧道打通)
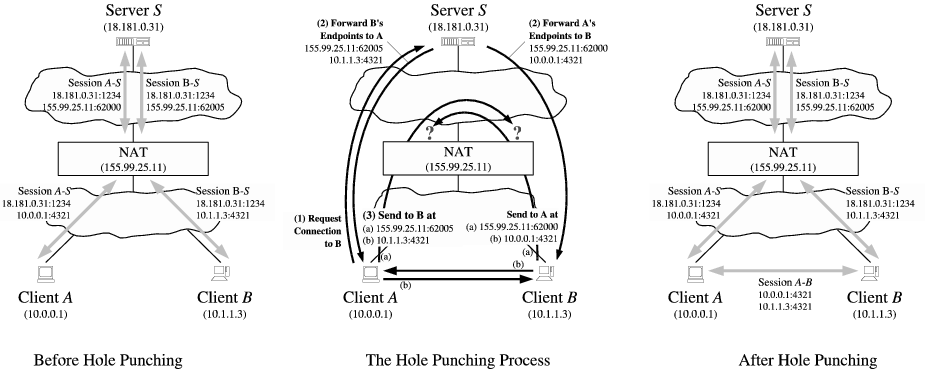
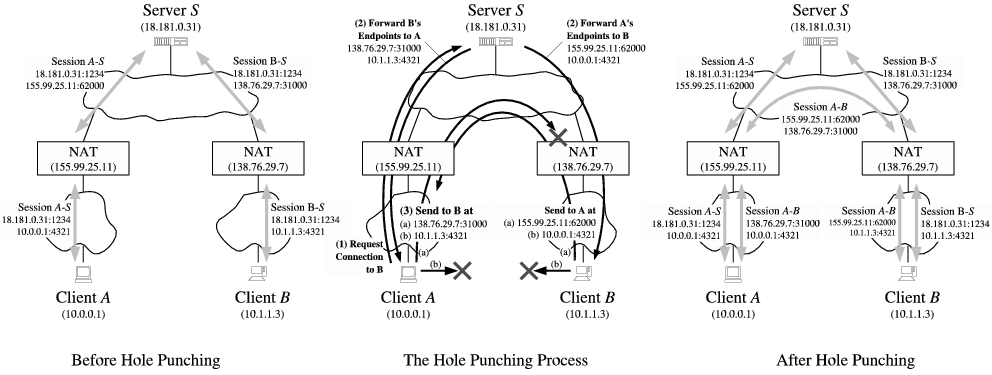
如果NAT不一样深,有多层深呢?
AB在发送自己信息,得到对方信息的时候需要把一路上每一级NAT的公网IP带出,而在打洞的时候需要从外到内一级级打(由于缺乏拓扑信息,往往不是最优,也可能会超时)
注意
Since
and
are on different private networks and their respective private IP addresses are not globally routable, the messages sent to these endpoints will reach either the wrong host or no host at all. Because many NATs also act as DHCP servers, handing out IP addresses in a fairly deterministic way from a private address pool usually determined by the NAT vendor by default, it is quite likely in practice that
.
TCP Hole Punching TCP打孔
Establishing peer-to-peer TCP connections between hosts behind NATs is slightly more complex than for UDP, but TCP hole punching is remarkably similar at the protocol level. Since it is not as well-understood, it is currently supported by fewer existing NATs. When the NATs involved do support it, however, TCP hole punching is just as fast and reliable as UDP hole punching. Peer-to-peer TCP communication across well-behaved NATs may in fact be more robust than UDP communication, because unlike UDP, the TCP protocol's state machine gives NATs on the path a standard way to determine the precise lifetime of a particular TCP session. 在 NAT 后面的主机之间建立点对点 TCP 连接比 UDP 稍微复杂一些,但 TCP 打洞在协议级别非常相似。由�于它还没有被很好地理解,目前支持它的现有 NAT 较少。然而,当涉及的 NAT支持时,TCP 打洞与 UDP 打洞一样快速且可靠。事实上,跨行为良好的 NAT 的点对点 TCP 通信可能比 UDP 通信更稳健,因为与 UDP 不同,TCP 协议的状态机为路径上的 NAT 提供了一种标准方法来确定特定 TCP 会话的精确生命周期。
Sockets and TCP Port Reuse 套接字和 TCP 端口重用
The main practical challenge to applications wishing to implement TCP hole punching is not a protocol issue but an application programming interface (API) issue. Because the standard Berkeley sockets API was designed around the client/server paradigm, the API allows a TCP stream socket to be used to initiate an outgoing connection via
connect(), or to listen for incoming connections vialisten()andaccept(), but not both. Further, TCP sockets usually have a one-to-one correspondence to TCP port numbers on the local host: after the application binds one socket to a particular local TCP port, attempts to bind a second socket to the same TCP port fail. 对于希望实现 TCP 打洞的应用程序来说,主要的实际挑战不是协议问题,而是应用程序编程接口 (API) 问题。由于标准 Berkeley 套接字 API 是围绕客户端/服务器范例设计的,因此该 API 允许使用 TCP 流套接字通过以下方式发起传出连接:connect(),或者通过以下方式侦听传入连接listen()和accept(),但不能两者兼而有之。此外,TCP 套接字通常�与本地主机上的 TCP 端口号一一对应:应用程序将一个套接字绑定到特定本地 TCP 端口后,尝试将第二个套接字绑定到同一 TCP 端口会失败。For TCP hole punching to work, however, we need to use a single local TCP port to listen for incoming TCP connections and to initiate multiple outgoing TCP connections concurrently. Fortunately, all major operating systems support a special TCP socket option, commonly named
SO_REUSEADDR, which allows the application to bind multiple sockets to the same local endpoint as long as this option is set on all of the sockets involved. BSD systems have introduced aSO_REUSEPORToption that controls port reuse separately from address reuse; on such systems both of these options must be set. 然而,为了让 TCP 打洞发挥作用,我们需要使用单个本地 TCP 端口来侦听传入 TCP 连接并同时启动多个传出 TCP 连接。幸运的是,所有主要操作系统都支持特殊的 TCP 套接字选项,通常称为SO_REUSEADDR,只要在所有涉及的套接字上设置此选项,它就允许应用程序将多个套接字绑定到同一本地端点。 BSD系统引入了SO_REUSEPORT选项,可以与地址重用分开控制端口重用;在此类系统上,必须设置这两个选项。
更多细节可以看 https://bford.info/pub/net/p2pnat/
由于S和A是两个外部节点,所以S试探出的ip, port要能用,还要求B的NAT不是symmetric的,A也一样
教授还提出了个很幽默的问题是
要求NAT支持打洞(甚至其他那些高级措施)是违背p2p的,需要NAT的支持,NAT原则上不会为不流行的新协议提供打洞支持(需要NAT起码知道哪里是IP,哪里是port,etc),而在现在广泛使用NAT的情况下,不支持穿过NAT的协议难以流行起来,死循环了
NAT Debate:
Pros:安全性,��地址重用
Cons:不是p2p依赖大规模的硬件支持,统一规范的困难,添加新行为的困难,应用程序编写增加的困难
NAT Operations
RFC 4787 UDP
- A NAT MUST have an "Endpoint-Independent Mapping" behavior(mapping和外部端口无关,禁止symmetric NAT)
- ......
RFC 5382 TCP
- 一样,禁止symmetric NAT
- 必须允许同时的开启TCP连接(A打洞连接B的public IP,SYN;然后B连接A的public IP,SYN。此时需要能连接,打洞完成,NAT必须允许且正确处理A SYN, B SYN这种TCP State)(NAT不限制任何遍历TCP状态图的连接实现方式)
- 收到没有map的TCP SYN时必须至少保留6s才可以发送ICMP响应 (如果一个在范围外的打洞用TCP SYN传入,然后给他拒了,自己这边尝试打对面的时候可能会因为对面TCP连接关闭删了这个mapping打洞失败)
- ......
HTTP:
REQ/RES API
text protocal, document-centric
HTTP Req Format:
method | URL | version
header field name | value
...
header field name | value
blank line
body
HTTP/1.0
- Open connection
- Issue GET
- Server closes connection after response
HTTP/1.0 Speed
Latency 50ms
Req size:1 seg, Res 2 seg
Seg packetization delay: 10ms, full duplex(全双工,收发互不影响)
Maximum open connections: 2
window足够大
Case 1: Single Page
SYN: 50 + SYN/ACK 50 + ACK/req 60 + res/70 = 230ms
Case 2: page loads 2 images
step1(page): Setup 100ms, req/res 130ms
step2(images): Setup 100ms,produce 2 response, 100 + 60 + 2*20+50 = 250ms
总共250 + 100 + 130 = 480ms
TCP连接占了很大的开销,HTTP无状态影响TCP服用
HTTP/1.1 Keep-Alive
1.0 的问题
- 多连接每次都要Setup太慢了
- 很多的传输大小都很小,TCP 的window size难以变大(Slow Start & AIMD)
HTTP/1.1
-
Added Connection header for req
- keep-alive: 告诉server不要关闭这个connection
- close: 告诉server关闭
- Server can always ignore
-
Added Connection header for res
- keep-alive: 告诉client不会关闭这个connection
- close: 告诉client会关闭
-
Added Keep-Alive header for res
- 告诉client connection可能被维持打开多久
SPDY
- req pipelining
- remove redundant headers
- Becoming basis of HTTP/2.0
BitTorrent
他讲的太快了
bt种子原理还可以参考
https://jaminzhang.github.io/p2p/BitTorrent-Principle-Introduction/
https://www.cnblogs.com/HMingR/p/13703917.html
https://www.zhihu.com/question/49829233/answer/160765176
https://zh.wikipedia.org/wiki/BitTorrent_(%E5%8D%8F%E8%AE%AE)
DNS
原理细节(层次系统)直接看b站或者小林就行,没什么新东西
设计时 DNS应该是
- 读远远多于写
- 弱一致性要求
- 可较长期缓存
- 单点故障不影响整个系统工作
分布式,多DNS server -> 强大的DDoS抗性
DNS cache poisoning 篡改DNS resolver里面的cache指向恶意网站
DNS info -> Resource Records (RR)
name [TTL] [class] [type] rdata
- name: domain name
- TTL: time to live (in seconds)
- class: for extensibility, usually IN 1(Internet)
- type: type, two critical: A(Ipv4 address) and (NS name server)
- rdata: data depends on type
DNS Message
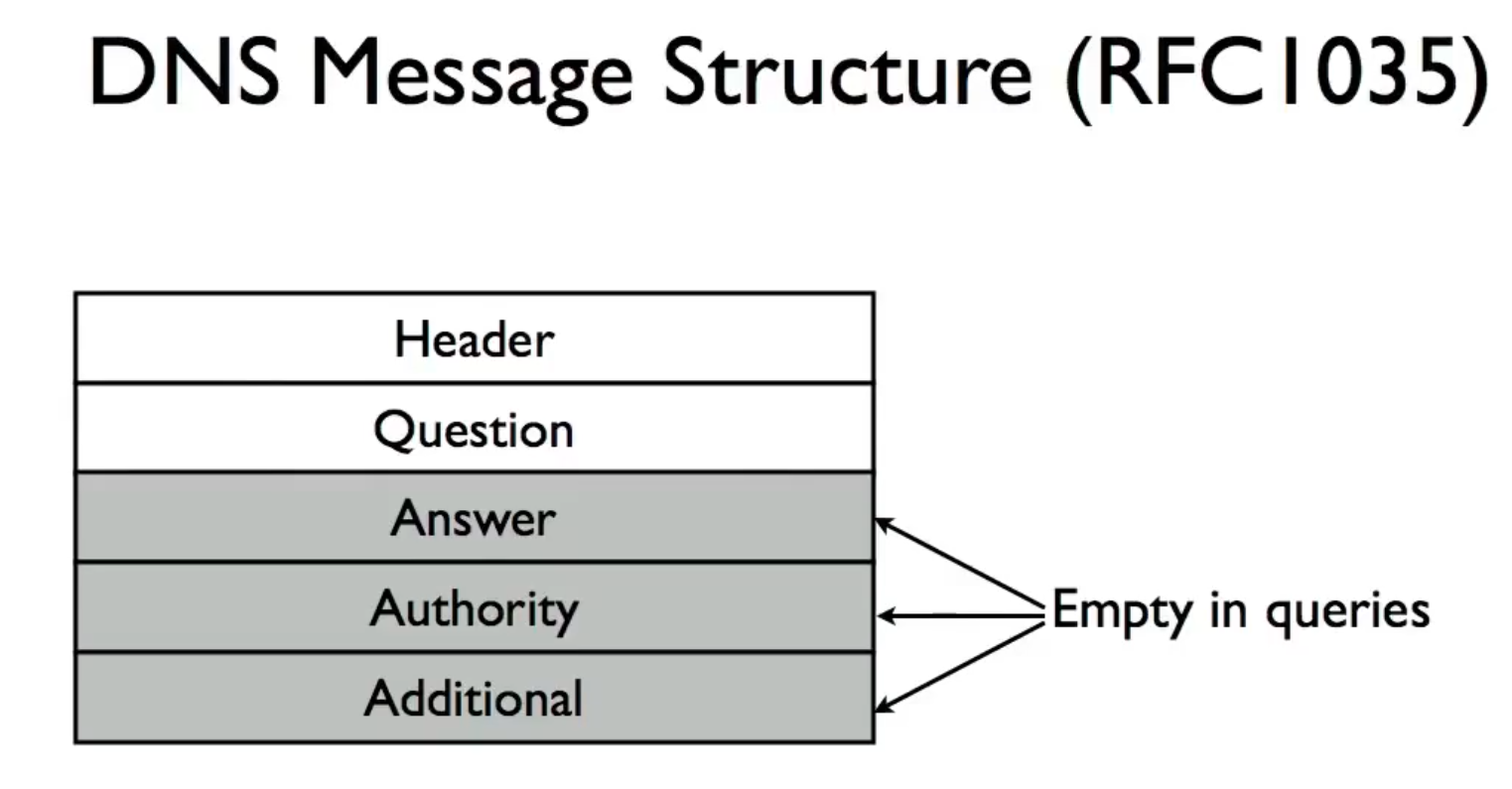
dns name compression
整个DNS包 < 512字节
Other Kinds of Records
CNAME: to create an alias DNS name
SOA: start of authority
TXT: some text(for extension)
PTR: map address to name
AAAA: Ipv6
DHCP
与IP通信至少需要:
- IP地址
- 子网掩码
- 网关 Gateway router, 传出去的第一跳
- [optional] DNS
问题:从一个新电脑,如何得到这些值?
曾经:手工配置
现在:DHCP协议,Dynamic Host Configuration Protocal
https://info.support.huawei.com/info-finder/encyclopedia/zh/DHCP.html
常见的DHCP服务器:路由器/光猫
课程讲得远不如动画清楚
虚拟机的网络模式:
-
网络地址转换NAT, 理解为为每一个虚拟机虚拟了一个DHCP服务器作为一个只出不进的NAT,给虚拟机分配了虚拟设备MAC, 虚拟机内连接外部ok(宿主机会作为NAT进行转发), host连接虚拟机不行(NAT外公网连内网), 虚拟机之间不能互连(有自己独立的DHCP)(不考虑端口转发等)
-
NAT网络,在虚拟机前加一台虚拟交换机,交换机连接宿主机,DHCP地址、网关地址不再一样,这样虚拟机可以连接虚拟机,其�他同上
-
桥接(网卡),把虚拟机放在宿主机的局域网里面,也作为一个“独立设备”去连接宿主机器连接的DHCP server,消耗宿主所在局域网的IP地址,此时全部可以连
-
内部网络:可以互相ping, 不能ping宿主和外部网络,一个隔离的内部网络
-
Host-only(仅主机):虚拟机和宿主构成的内部网络,虚拟机不能连外部互联网和被连,比如docker采用host-only多
Unit 6: Routing
Approaches
- Flooding 在每个节点广播,效率低,但能保证可达性,仅在对网络拓扑一无所知时考虑
- Source routing 另一个极端,端点完全知道内部的拓扑,进而直接指定一条路
- Forwarding table 核心在于如何填充这些转发表
- Spanning tree 一种填充转发表的方法,可以是距离的最小生成树,跳数的最小生成树,延迟的最小生成树......
实际上采用的路由算法也称路由协议
Metrics
Shortest path spanning trees
Other types of routing
- Multipath 最小生成树的问题在于有些节点的的度会很高,吞吐压力很大,将不同的包分配到不同路径上均匀负载
- Multicast 多个目标优化的情况,例如,广播,想要以尽可能少的传输代价发送到大量主机
Bellman-Ford 算法
这里他用的“到X的最小生成树”实际上是X的单源最短路径树
分布式Bellman-Ford
- 初始所有点到源的距离设为无穷,记为距离向量C=(C1,C2,...)
- 每过T时间,将C发送到所有邻边
- 如果发现发送过来的Ci比自己的Ci小,更新自己的Ci
- 重复23
运行时间:最长无循环路径
收敛性:一定收敛
当连接的cost改变/连接挂了:Bad news travel slowly(Count to Infinity Problem)
R1->R2->R3->R4的图,R3->R4断了,R3会把R3-R4更新为R2-R3 + R2-R4的值而不是无穷!
这样Ri->R4的值都是慢慢增加,对切断完全不敏感
解决方法有很多:
- 设置“无穷”为一个小的值,迭代到超过它就是无穷,停止,认为截断
- split horizon: R2从R3处得到最小的cost, 不反向传回R3(或传回无穷)
- ......
split horizon不一定总是有效的,比较容易构造例子
Bellman Ford 算法和split horizon等机制构成了第一代路由协议(Routing Infomation Protocol, RIP)
优点是路由器的计算量很小
Dijkstra算法 大家都很熟了
注意一下Dijkstra在cost改变或者link出错的时候需要对所有节点重新计算单源最短路径
计算量大,但错误立即传播
OSPF(Open Shortest Path First)协议的基础
Hierarchy and Autonomous Systems(AS)
前面把互联网看成路由器的集合,对也不对
核心问题是规模太大了,导致交换和同步开销太大,即使按照O(E)也不现实, 实际上是多个小集合连接起来
每一个小集合称为一个AS,AS内部自己决定路由协议,通过一个或者多个出口和外部连接
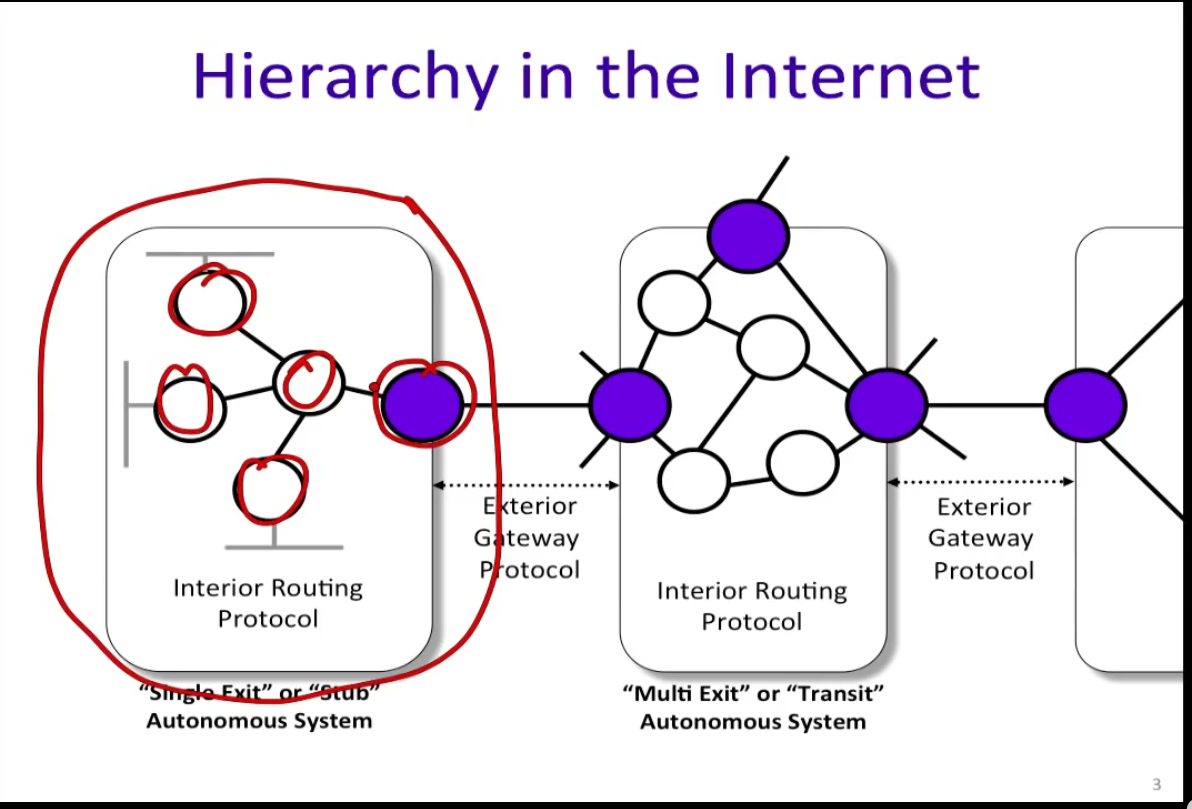
在AS之间,必须使用BGP-4(Border Gateway Protocol, rfc 1771)
AS的粒度大概在大学校,大企业这样
找找交大的AS
❯ traceroute electsys.sjtu.edu.cn
traceroute to electsys.sjtu.edu.cn (202.120.35.189), 30 hops max, 60 byte packets
1 * * *
2 * * 10.3.2.217 (10.3.2.217) 4.413 ms
3 10.32.31.246 (10.32.31.246) 4.915 ms 4.895 ms 4.874 ms
4 10.32.73.226 (10.32.73.226) 4.305 ms 4.732 ms 4.090 ms
5 202.120.35.189 (202.120.35.189) 4.033 ms 4.014 ms 3.995 ms
❯ whois 202.120.35.189
% [whois.apnic.net]
% Whois data copyright terms http://www.apnic.net/db/dbcopyright.h
tml
% Information related to '202.112.0.0 - 202.121.255.255'
% Abuse contact for '202.112.0.0 - 202.121.255.255' is 'abuse@cernet.
edu.cn'
inetnum: 202.112.0.0 - 202.121.255.255
netname: CERNET-CN
descr: China Education and Research Network
descr: China Education and Research Network Center
descr: Tsinghua University
descr: Beijing, 100084
country: CN
admin-c: CER-AP
tech-c: CER-AP
abuse-c: AC1685-AP
status: ALLOCATED PORTABLE
remarks: origin AS4538
mnt-by: APNIC-HM
mnt-lower: MAINT-CERNET-AP
mnt-routes: MAINT-CERNET-AP
mnt-irt: IRT-CERNET-AP
last-modified: 2020-09-03T09:16:29Z
source: APNIC
irt: IRT-CERNET-AP
address: Network Research Center,
address: Main Bldg, Tsinghua Univ
address: Beijing 100084, China
phone: +86-10-62784301
fax-no: +86-10-62785933
e-mail: abuse@cernet.edu.cn
abuse-mailbox: abuse@cernet.edu.cn
admin-c: CER-AP
tech-c: CER-AP
auth: # Filtered
remarks: timezone GMT+8
remarks: http://www.ccert.edu.cn
remarks: abuse@cernet.edu.cn was validated on 2024-07-04
mnt-by: MAINT-CERNET-AP
last-modified: 2024-07-04T04:10:10Z
source: APNIC
role: ABUSE CERNETAP
address: Network Research Center,
address: Main Bldg, Tsinghua Univ
address: Beijing 100084, China
country: ZZ
phone: +86-10-62784301
e-mail: abuse@cernet.edu.cn
admin-c: CER-AP
tech-c: CER-AP
nic-hdl: AC1685-AP
remarks: Generated from irt object IRT-CERNET-AP
remarks: abuse@cernet.edu.cn was validated on 2024-07-04
abuse-mailbox: abuse@cernet.edu.cn
mnt-by: APNIC-ABUSE
last-modified: 2024-07-04T04:10:19Z
source: APNIC
role: CERNET Helpdesk
address: CERNET Center
address: Beijing 100084, China
country: CN
phone: +86-10-6278-4049
fax-no: +86-10-6278-5933
e-mail: helpdesk@cernet.edu.cn
remarks: abuse@cernet.edu.cn
admin-c: XL1-CN
tech-c: SZ2-AP
nic-hdl: CER-AP
mnt-by: MAINT-CERNET-AP
last-modified: 2020-09-03T09:14:12Z
source: APNIC
% This query was served by the APNIC Whois Service version 1.88.25 (W
HOIS-AU1)
是中国教育和科研计算机网络()
mac上支持traceroute -a但是ubuntu好像不支持
Interior Routing Protocols
RIP:
- 使用分布式Bellman-Ford
- 每30s更新一次
- 没有身份验证
- 曾经广泛使用,现在多被OSPF和ISIS取代
OSPF:
- 连接信息直接暴力flooding
- 每一个路由器都跑Dijkstra
- 身份验证
- 很多复杂的细节(doge)
单个出口的AS非常简单
-
每一个路由器的default routing(路由表第一项)都是出口
-
路由表通常很小
多出口:
必须指定每一个router的出口和对应前缀
Approach 1: hot-patato routing, 分配离路由器最近的出口
Approach 2: 分配离目标最近的出口
BGP-4 尝试解决的问题:
- 网络拓扑复杂
- AS 的 COST 五花八门,所以不可能找最短路径,找到一组路径就行
- 有些AS不信任其他的一些AS,隐私保护
- 不同AS的策略和目标不同
the structure of Internet
从 Global ISP 到 Regional ISP 到 access ISP
BGP4
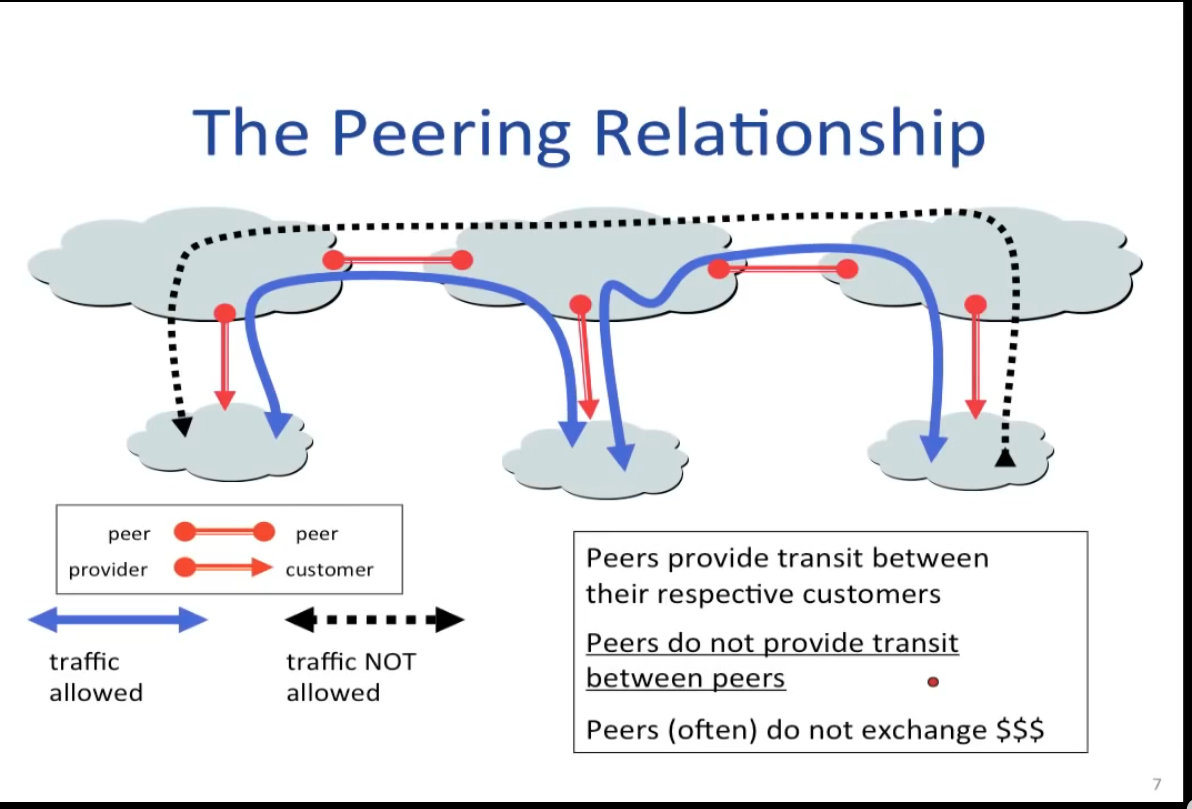


例如商业上的local pref可能是
customer > peer > provider
Multicast
Reverse Path Broadcast(RPB)
aka Reverse Path Forwarding(RPF)
重用已有的最短路径树,Flooding但是只在最短路径树上Flooding
进一步可以给最短路径树加上剪枝
如果说对每个节点都维护一个最短路径树开销太大,也可以比如所有节点都采用中间的某个节点的最短路径树
多播常常不知道也难以知道接受者,这时候需要接受者主动表示接受数据包的意愿
IGMP host和直连router的协议,host要求router接受某些多播组的数据;router轮询host是否还想要
一些协议 DVMRP, PIM
multicast使用的比想象的少, 并且早期效率确实不高,并且安全、控制之类的问题也很多
Spanning Tree Protocol
Ethernet是如何避免循环的?(没有TTL字段的情况下)——构建生成树

现在的算法又有很多变化和改进
IPv6 128位地址 16 * 8 8个 4个16进制 字母块
https://[2001:470:806d:1::9]:80
大地址空间简化配置和IP分配问题
Unit 7: Physical and Link
Link
连接层
Channel capacity = B log2(1+S/N)
- B 带宽,S 信号强度,N噪声
电磁波->信号:
- Amplitude Shift Keying ASK振幅调制
- Freq Shift Keying FSK频率调制
- Phase Shift Keying PSK相位调制
有线网络一般ASK 慢的PAM-5,快的PAM-16
振幅调制需要环境干扰小且稳定
类似无线网络,环境干扰大,就常用PSK
BPSK two phases (0, pi)
QPSK (0, 90, 180, 270)
相位的优点有一个是可以很轻松地得到任意相位的波
I/Q Moudulation 一个0,一个180,线性叠加
QAM 同时使用ASK和PSK来得到物理层上表示更多信息的符号
eg. 16-QAM for 3G
Bit Error and Coding
Bit Error 噪声必定带来错误的symbol
Coding 通过在物理层加入冗余的bit来检错纠错
m/n code: m位bit转化为n位物理层bit 1/2 3/4
物理和链路原理
如何在没有全局时钟的情况下从电磁波得到symbol(接受者不知道发送者的时钟)
异步通信:
收到Start的下降沿之后开始按照自己的时钟周期接受
适用于 数据量小(积累偏移少,无需同步)的情况
例如红外遥控器
同步通信:
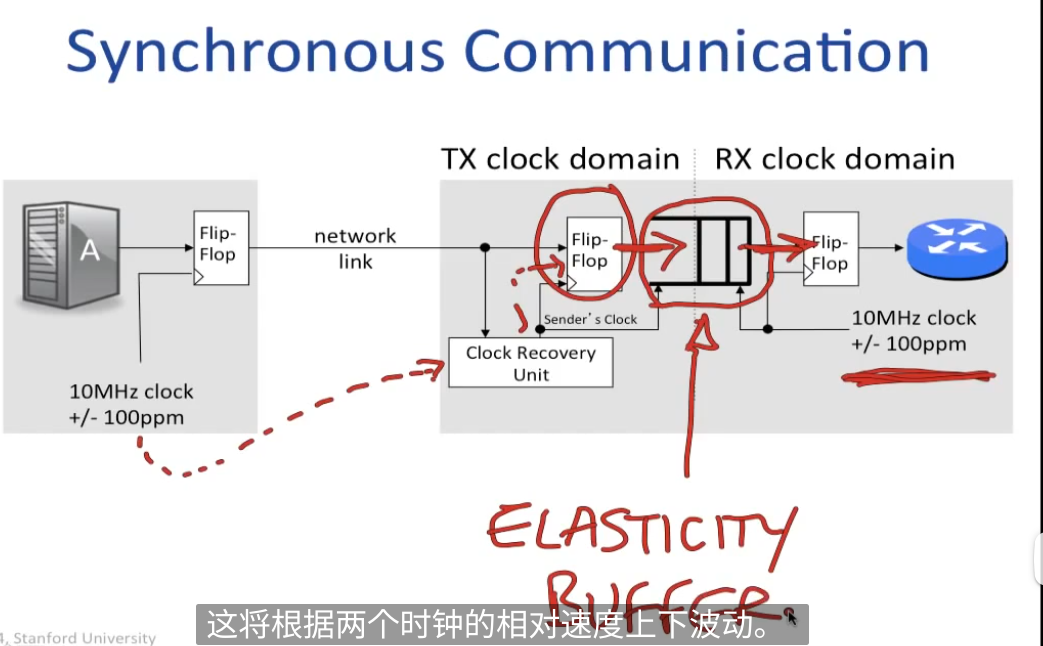
从时钟恢复单元通过过滤等手段从发送信号中得到原始时钟
以原始时钟速率压入FIFO, 另一端以接收端的时钟弹出FIFO
如果不发送原始时钟信号,要完成clock recovery需要原始data有上升/下降沿
如何处理全0/全1?
Manchester Coding:
在曼彻斯特编码中,每一位的中间有一跳变,位中间的跳变既作时钟信号,又作数据信号。
曼彻斯特编码有两种相反的约定。
其中的第一种约定由1949年由GE托马斯(GE Thomas)首次出版,随后有众多作家使用,例如,安迪·塔南鲍姆(Andy Tanenbaum)。 [3]它指定对于0位,信号电平将为低高电平(假设对数据进行幅度物理编码)-在位周期的前半段为低电平,在后半段为高电平。对于1位,信号电平将为高-低。
第二种约定也被众多作者使用(例如William Stallings) [4],IEEE 802.4(令牌总线)和IEEE 802.3(以太网)标准的低速版本所遵循。它指出逻辑0由高-低信号序列表示,逻辑1由低-高信号序列表示。
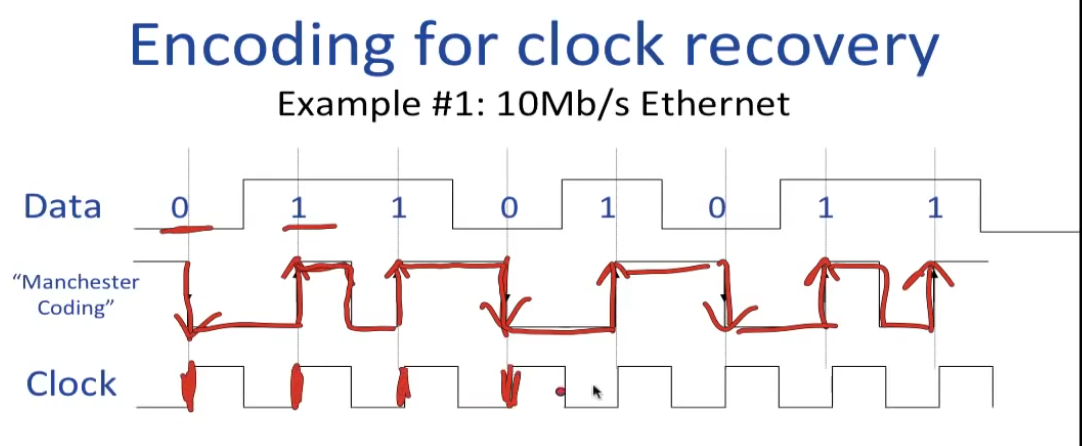
问题:中间那个跳变为什么无影响?
答:对面也需要有大概频率,过一个过滤器(找频率的主成分),时钟能差两倍还是太离谱了
Pros:
- 保证一个bit一次转换
- 保证了 d.c balance (相等的high/low, 有效电压稳定)
Cons: 曼彻斯特编码的问题是最坏需要两倍的带宽
4b5b encoding

Coding
物理性错误的概率低但不是没有
加冗余:forward coding
Reed Solomon 编码(CD, DVD, RAID6, ...)
- 从data中取k块
- 让这k块作为一个k-1的多项式f的系数
- 用f计算n个不同点(n>=k)
- 把这n个点作为k块的附加也发送
- n个中任意k个可以恢复原始多项式
最多校正 (n-k)/2个error,可以查所有错
可以通过interleaving来提升纠错能力,避免burst errors
The Link Layer
Ethernet上通过介质(空气,总线等)连接的多台主机的发信协议?
-
Aloha 非常简单,有话就直接对介质说,冲突(自己说完听,如果不一样就冲突了)就稍后重发
-
CSMA/CD(实际使用的) 比较Aloha,加了1.说前先听有没有在说(CS) 2.(CD)如果冲突立刻停止,冲突后根据当前负载随机决定重发时间(0, 2^n^)512 bit times
-
更复杂的token ring之类用的不是很多,容错性也不是很好
CSMA/CD 有最小包大小要求
如果距离最远两个点距离L, 传输速率c, 每个包至少要有2L/c这么长,否则collision信号传输到一个已经发完包的节点是令人疑惑的
Ethenet
更快的Ethenet 由于 2L/c 的限制,数据包大小不变,L只能缩小
早期:使用Hub 集线器
后来Ethenet越来越快,冲突增加,L减少,需要进行更多分区,不再能一个Hub全管,同时芯片技术升级,成本降低,就从粗放管理产生了交换机
并且交换机的线还可以做成全双工,进一步减少冲突
Hubs to Switches
对于集线器而言,信号将沿其端口进行传输,并广播到其他端口,正因如此容易产生广播风暴,当网络规模较大时其性能会受到影响。而交换机只有发出请求的端口和目的端口之间才会相互响应,并不会影响到其他端口,因此交换机能够在一定程度上有效抑制广播风暴的产生。
此外,集线器的所有端口都是共享一条带宽,在同一时刻只能有两个端口进行数据传输,其他端口都处于等待状态。而交换机的每个端口都有一条独立的带宽,当各个端口进行工作时,每个端口之间互不受影响。而且交换机会保留与之连接的所有设备的MAC地址,可查询到数据转发到了哪个端口上。也就是说交换机确切地知道将数据发送到了哪个端口,能有效节省网络响应时间。但集线器却没法区分将数据转发到了哪个端口。
| 区别 | 集线器 | 交换机 | 路由器 |
|---|---|---|---|
| 工作层次 | 物理层 | 数据链路层 | 网络层 |
| 作用 | 信号放大和传输作用,可将计算机网�络连接在一起。 | 将一个网络端口分成多个网络端口,用于连接更多的设备;同时可管理端口和配置VLAN安全管理。 | 连接不同的网络,以及选择信息传输的线路。 |
| 数据传输形式 | 电信号 | 帧和包 | 包 |
| 端口 | 4/12端口 | 多端口,通常在4~48端口数之间 | 2/4/5/8端口 |
| 传输方式 | 泛洪、单播、多播或广播 | 先广播在单播或多播 | 先广播在单播和多播(取决于需求) |
| 设备类型 | 非智能设备 | 智能设备 | 智能设备 |
| 应用 | 局域网 | 局域网 | 局域网/城域网/广域网 |
| 传输模式 | 半双工 | 半双工/全双工 | 全双工 |
| 速率 | 10Mbps | 10/100Mbps, 1Gbps | 1 |
| 用于数据传输的地址类型 | MAC地址 | MAC地址 | IP地址 |

Wireless Networking
Radiates over space -> 最坏r^2^的信号衰减
Uncontrolled medium -> 易受影响,随时变化
can reflect
wifi 具有高丢包率,且波动巨大->必须考虑tcp等重传机制
CSMA/CD对wifi不适用:核心在于碰撞检查,在无线情况下,自己监听到的情况和实际接受者处的情况区别较大(比如衰减太多以至于听不到)
问题有:
- 如何区分是碰撞还是信号衰减太多没收到
- Exposed terminal, B->A, C->D, 圆形区域以为信道碰撞,实际没有碰撞可以使用
- Hidden terminal, 例如A-B-C,中间有山, A感知不到C, C感知不到A,无法碰撞检测
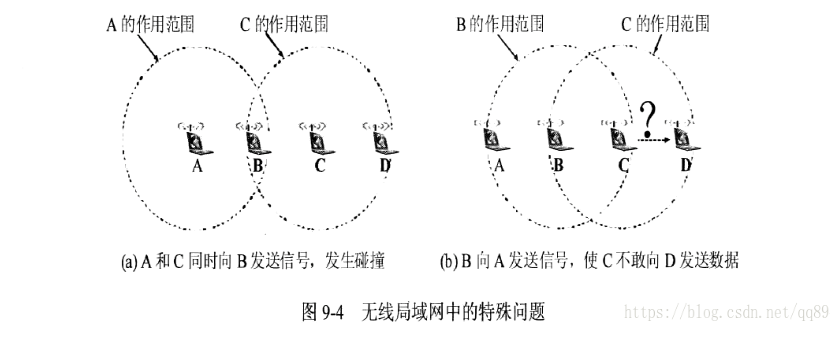
CSMA/CA (collision avoidance)
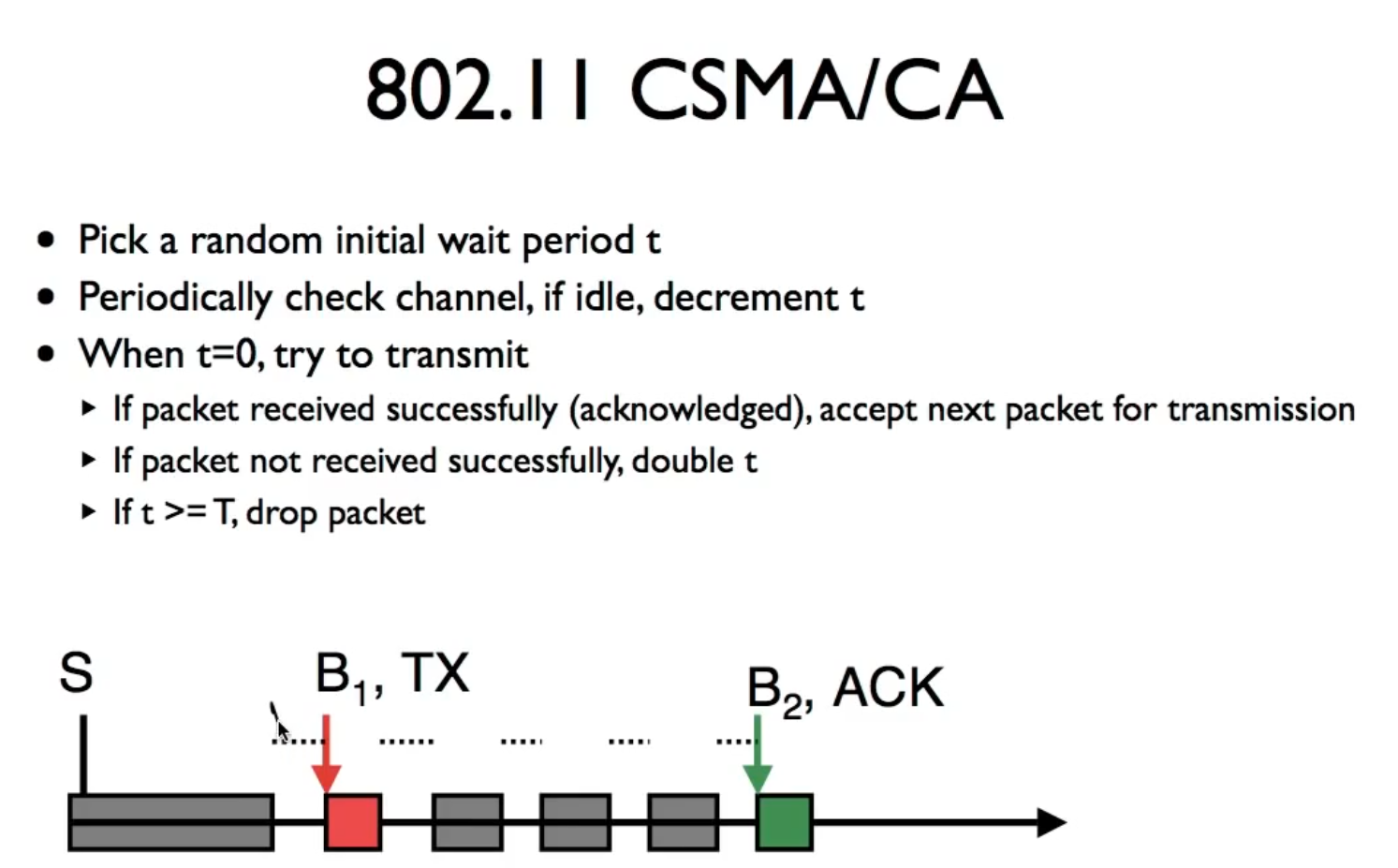
把碰撞检测改成碰撞检查,尝试发送包的时候先给目标发送一个确认,当目标返回确认时才发包,否则等待并重试,如果等待太久丢弃这个包
参考 https://www.cnblogs.com/cpaulyz/p/12461500.html
CSMA/CA尝试降低碰撞的概率,但没有解决上面Exposed terminal等问题
在CSMA/CA上的补充:RTS/CTS
简要流程
在送真的封包之前,先廣播一個 request to send 封包。這個封包不只有目的地會收到,發送者傳輸範圍內的其他裝置也會收到。而目的地如果順利收到這個 RTS 的封包,則必須廣播一個 clear to send (CTS) 封包,代表已經準備好接收封包。
並且規定:聽到 CTS 廣播的那些節點,也就是上圖中的紅色節點,在一段足夠向 𝐶 傳輸完訊息的時間內,都不能向 𝐶 傳輸訊息
https://en.wikipedia.org/wiki/IEEE_802.11_RTS/CTS
这个讲得很好 https://hackmd.io/@0xff07/SJO5VTpmY
解决了Hidden terminal, 对另外两个效果不是很好
但是实际的WIFI系统不怎么用,开销问题
传输速率越高,实际数据需要的时间越少,在传数据前进行RTS/CTS沟通的开销就越大,11Mbps的时候已经占了25%的开销
802.11 Format
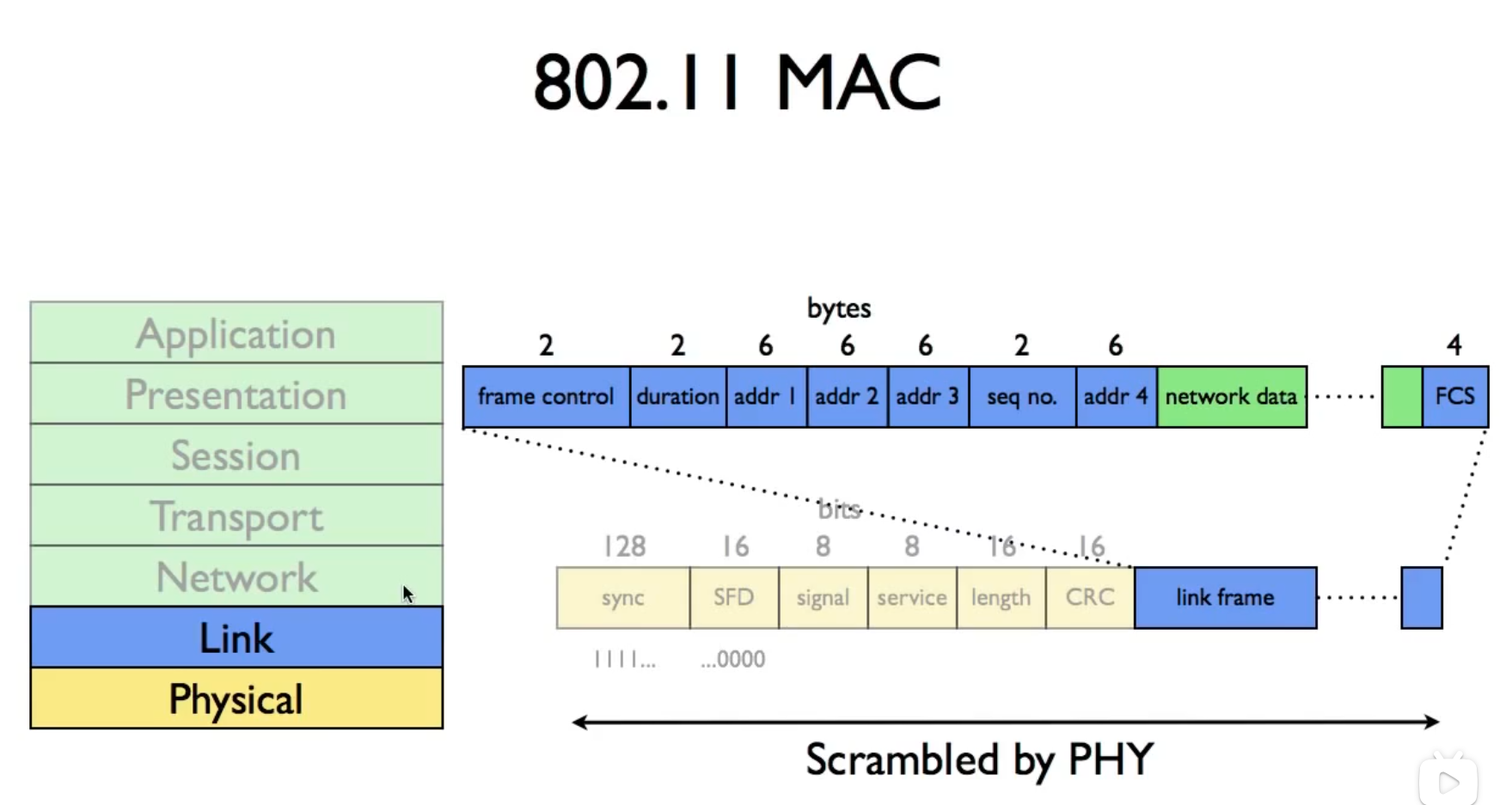
duration可以用来提供CTS对其他节点需要等多久的通知
wifi为了向前兼容性
前面的控制头是以最低速率1mbps 发送的,后面的data段才可以加速
这也是为什么速率上不去(2020的144说最大600mbps左右(for 802.11.n 2008))和RTS/CTS实际上开销很大的原因
Fragementation:
不同的Link层对包的大小最大限制是不同的
一个大的数据传输时会被分成许多小包,而在传输过程中如果分成的小包还是超过了这一段的传输限制,就会继续拆分,但直到dst之前都不会被重新组装。
过多的小包带来了速度和容易丢失(一旦有一个IP包拆出来的几个小包丢失就需要重发整个IP包)等问题,所有要避免
一个技术手段是使用IP的DF(don't fragment)bit,指定之后如果发现还需要进一步分片,就丢弃并返回一个ICMP error
分片细节参考
https://packetpushers.net/blog/ip-fragmentation-in-detail/
现在的分段问题少了很多,一个是基本使用Ethernet 1500MTU, 二个是会提前使用ICMP检测路径上最短的MTU(maximium transmition unit),控制包小于MTU来避免分块,不过对于UDP,参见上面的blog,还是有不少问题
Unit 8: Security
- Secrecy
- Integrity
- Authentication
- Uninterrupted communication
这个章节建议看看他的动画demo听故事(bushi)
Layer2 ATTACK(Link)
MAC Overflow attack: 交换机从包的src,dst中学习路径,如果表里面没有就全端口广播,为了让攻击者看到交换信息,攻击者产生大量{src,dst}包用于LRU驱逐交换机原有的路径表,使得其他人发包产生广播
DHCP ATTACK 建立恶意DHCP server, 并先于好的server发出响应
同理的ARP ATTCAK
TCP Hijacking(TCP劫持)ARP ATTACK的基础上,作为TCP连接的转发中间人窃听信息
Layer3 ATTACK(IP)
ICMP ATTACK 在路由不到的时候会返回一个ICMP error,攻击者通过恶意路由器充当中间人/重定向到恶意地址
BGP hijacking 非常严重,几乎无法防备。从运营商层面进行攻击,提供错误的路由“路标” https://www.cloudflare.com/zh-cn/learning/security/glossary/bgp-hijacking/
More Specific Prefix
DDos 大规模变化肉鸡向server发送消耗资源无意义请求,例如flood ping,占用大量网络带宽至服务不可用
更精妙的是可以有其他服务器充当放大跳板,有些请求的响应会比请求大几倍,向某个跳板服务器发送目标为攻击服务器的请求,跳板服务器的响应洪流就可以比原始攻击流放大几倍,也更不好追踪
还有SYN Attack 多台攻击机器向服务器发起tcp请求,又不建立链接,让被攻击服务器自己超时才释放,消耗系统资源。类似还有发送部分IP链接碎片的IP Fragment flooding
还有UDP echo攻击,SSL攻击......
解决方法:加密 && 可拓展(高可用)系统 && 信任链 && ......
后面的密码学感觉没有什么特别研究的必要,都是数学细节,非对称加密、证书、TLS之类看看科普也行,写过web多少知道些。知道咋回事,拿来用就行。用课程的一句话:
It's easy to make a mistabke. Use existing, open source implementions. Be careful and follow best practices.