美团技术博客阅读
美团外卖基于GPU的向量检索系统实践
美团外卖的向量检索系统使用了GPU来加速向量检索过程。该系统主要包括以下几个方面: 美团外卖业务特点具有较强的Location Based Service(LBS)依赖,即商家的配送范围,决定了用户所能点餐的商家列表。以商品向量检索场景为例:向量检索结果集需要经过“可配送商家列表”过滤。
美团外卖向量检索基于Elasticsearch+FAISS进行搭建,实现了10亿级别+高维向量集的标量+向量混合检索的能力。为了在保证业务高召回率的同时进一步减少检索时间,我们探索基于GPU的向量检索,并实现了一套通用的检索系统。
相继使用了HNSW(Hierarchical Navigable Small World),IVF(Inverted File),IVF-PQ(Inverted File with Product Quantization)以及IVF-PQ+Refine等算法,基于CPU实现了向量检索能力
在HNSW算法中,这种导航小世界图的层次结构使得搜索过程可以从图的高层开始,快速定位到目标点的大致位置,然后逐层向下精细化搜索,最终在底层找到最近邻,在通用检索场景上有显著的优势。然而该算法在高过滤比下性能会有折损,从而导致在到家搜推这种强LBS过滤场景下会暴露其性能的劣势。业界有较多相关的benchmark可以参考,以Yahoo的向量检索系统Vespa相关博客为例
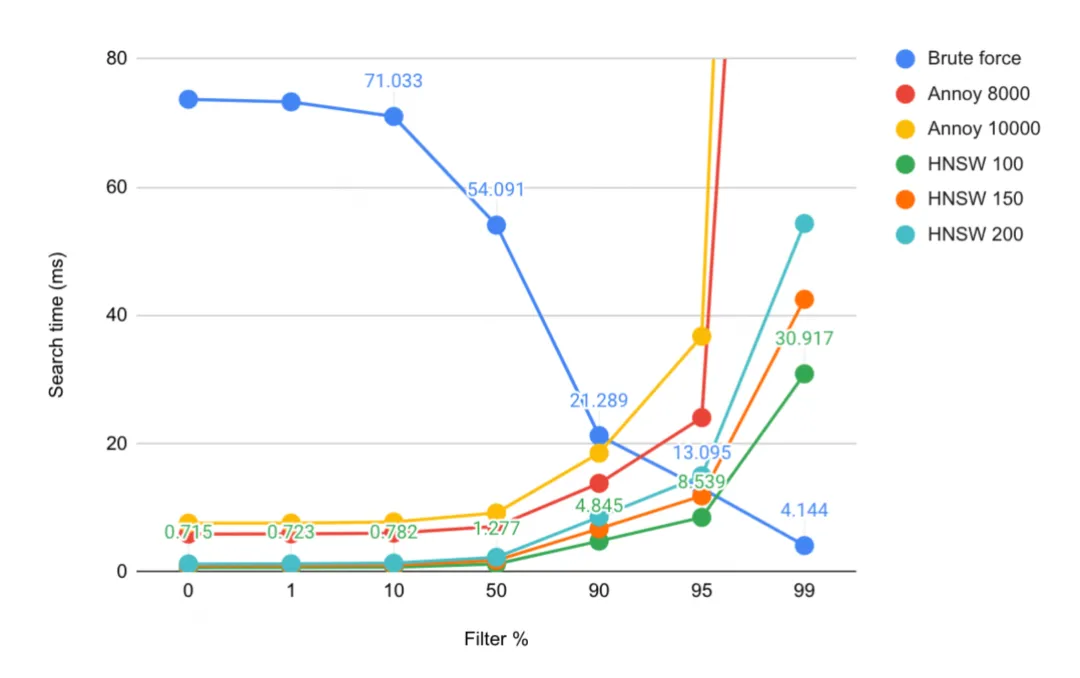
索引吞吐
Observations: 观察结果:
- Indexing throughput depends on corpus size for Annoy and HNSW, where throughput is halved when corpus size is increased by 10x. 对于 Annoy 和 HNSW,索引吞吐量取决于语料库大小,当语料库大小增加 10 倍时,吞吐量就会减半。
- Indexing throughput for RPLSH is independent of corpus size. RPLSH 的索引吞吐量与语料库大小无关。
- Annoy is 4.5 to 5 times faster than HNSW. Annoy 比 HNSW 快 4.5 到 5 倍 。
- RPLSH is 23 to 24 times faster than HNSW at 1M documents. 对于 1M 文档,RPLSH 的速度比 HNSW 快 23 到 24 倍 。
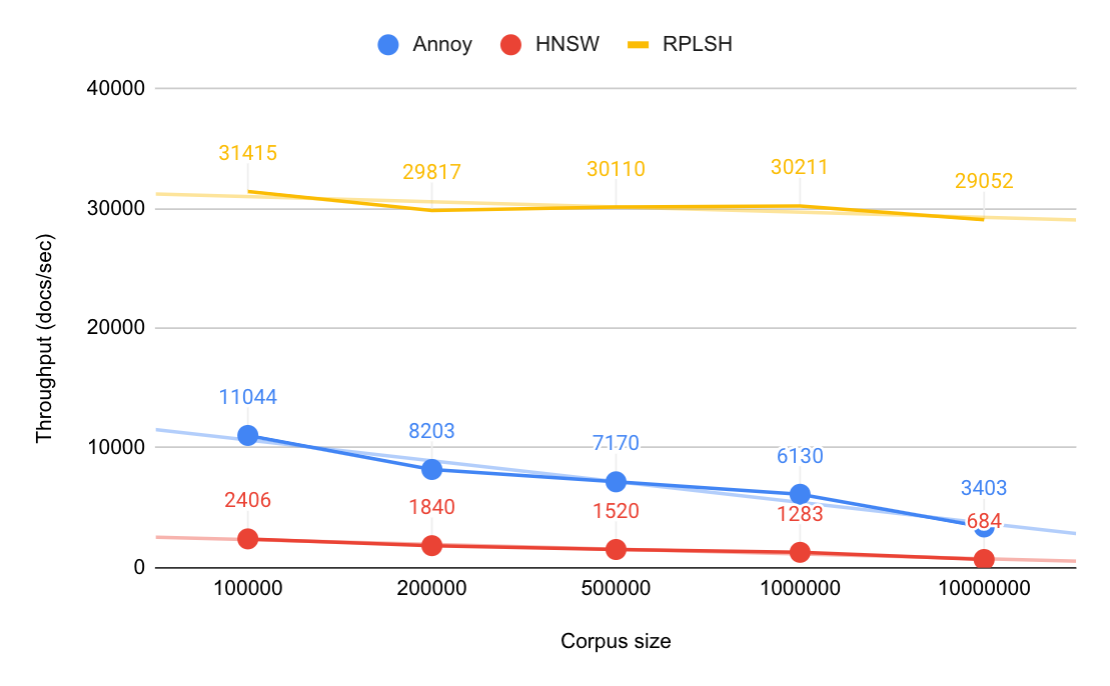
查询吞吐
Observations: 观察结果:
- HNSW outperforms Annoy and RPLSH. At corpus size 1M the QPS is 9 times as high as Annoy, and 16 times as high as RPLSH at comparable quality. Similar observations between hnswlib and Annoy are found in ANN Benchmarks, where the QPS of hnswlib is 5-10 times higher at the same quality on all tested datasets. HNSW 的表现优于 Annoy 和 RPLSH。在 1M 语料库规模下,其每秒查询速度 (QPS) 是 Annoy 的 9 倍 ,在同等质量下是 RPLSH 的 16 倍 。在 ANN 基准测试中也发现了 hnswlib 与 Annoy 之间的类似现象:在所有测试数据集上,相同质量下 hnswlib 的每秒查询速度 (QPS) 比 Annoy 高 5-10 倍。
- HNSW 搜索算法很大程度上取决于节点之间的链接数量,而链接数量又取决于语料库的大小。当语料库规模增加 10 倍时,QPS 会减半。在索引过程中,我们也看到了同样的情况,因为它使用搜索算法来查找要连接的候选节点。
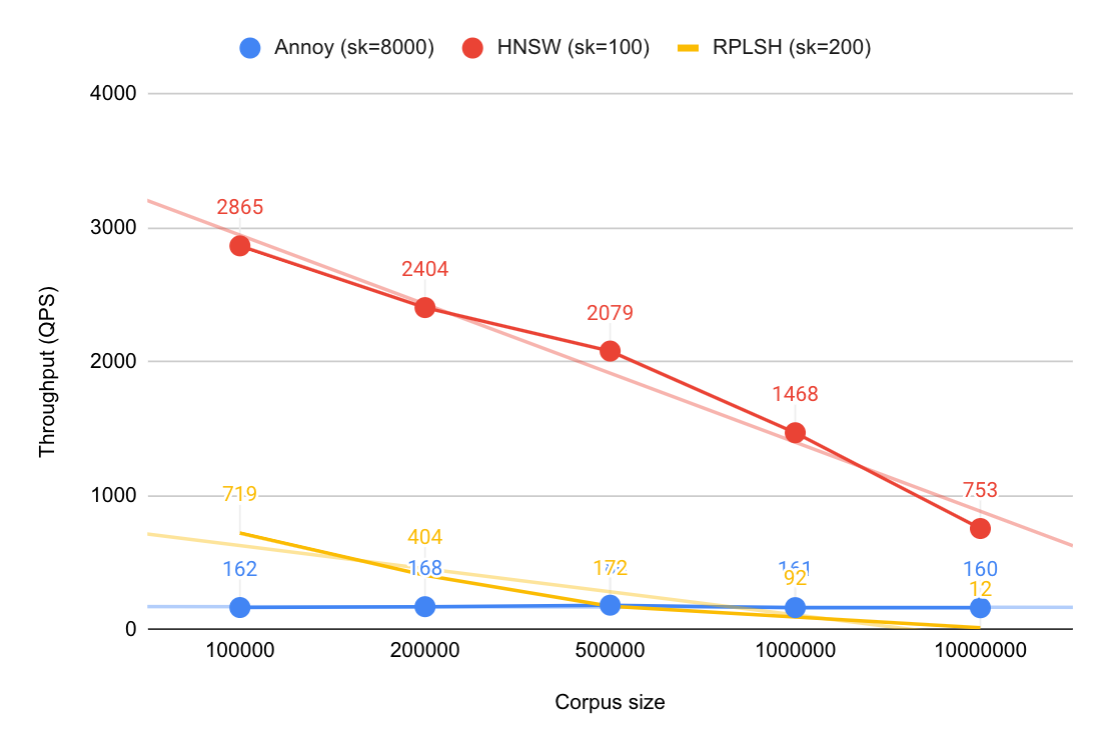
内存占用
Observations: 观察结果:
- The Annoy index is almost 3 times larger than the HNSW index, which results in ~40% more total memory usage in the 1M SIFT dataset. Annoy 索引几乎比 HNSW 索引大 3 倍,这导致 1M SIFT 数据集的总内存使用量增加约 40%。
- Both indexes are independent of dimension size, but max points in a leaf node (Annoy) and max links per level (HNSW) might need adjustments with higher dimensionality to get decent quality. 这两个索引都与维度大小无关,但叶节点中的最大点数(Annoy)和每级的最大链接数(HNSW)可能需要使用更高的维度进行调整才能获得不错的质量。
博客给出了一个很重要的观察是:当超过 90% 到 95% 的文档被过滤掉时,过滤后计算精确最近邻比搜索 HNSW 索引(过滤器会丢弃候选匹配项)的成本更低
2.2 IVF (Inverted File)
IVF是一种基于倒排索引的方法,它将高维向量空间分为多个簇(Cluster),每个簇对应一个倒排列表,存储了属于该簇的向量索引。这种方法大大减少了搜索时需��要比较的向量数量,从而提高了检索速度。它的缺点是需要存储原始的向量数据,同时为了保证检索性能需要将其全量加载到内存中,从而占用了大量的内存空间,容易造成内存资源瓶颈。
2.3 IVF-PQ(Inverted File with Product Quantization)
在候选集数量巨大的场景下,比如商品向量检索场景下,IVF带来的内存空间大的问题很快就显现出来,为了解决内存空间的问题,开始尝试使用了IVF-PQ方法。该方法在IVF的基础上,使用了乘积量化(Product Quantization,PQ)的方法来压缩向量数据。PQ将高维向量分为多个子向量,然后对每个子向量进行量化,从而大大减少了对内存空间的需求。
然而,由于量化过程会引入误差,因此IVF-PQ的检索精度会低于IVF,从而导致召回率无法满足线上要求,对召回率要求相对较低的场景可以使用IVF-PQ,对召回率有一定要求的场景需要其他解决方案。
2.4 IVF-PQ+Refine
为了提高IVF-PQ的检索精度,进一步采用了IVF-PQ+Refine的方案,在IVF-PQ的基础上,在SSD磁盘上保存了未经压缩的原始向量数据。检索时,通过IVF-PQ召回数量更大的候选向量集合,然后获取对应的原始向量数据进行精确计算,从而提高检索精度。这种方法既保留了IVF-PQ的存储优势,解决了内存资源瓶颈,又保证了召回率,因此在实际应用中得到了广泛的使用。
2.5 基于地理位置的向量检索
通过将经纬度编码为向量,优化具体做法是将用户或商家的经纬度以加权的方式加入查询Query和候选向量中,在计算Query和候选向量的相似度时,距离因素就可以在不同程度上影响最终的检索结果,从而达到让向量索引具备LBS属性的目标。
这里没有细讲,但怎么具体怎么融入的LBS属性还是比较有意思的,最直接的方法是将经纬度信息直接拼接到现有的文本embedding向量上,也可以将经纬度用geohash,或者以用户为中心的极坐标系统表示?
我觉得最复杂的在于:
- 如何确定经纬度特征的维度,这也算是一种权值
- 如何让经纬度特征和其他向量特征上对齐?美团是否有一个专用的embedding模型来嵌入地理信息特征,这个模型又是根据什么进行微调的?是类似推荐系统那种基于用户反馈的,还是内部有一个地理加权的人工设计公式,这个模型提供的地理特征使得整体效果向这个公式靠齐的?
https://docs.google.com/document/d/1R5nOiwFUn9ZJtuWywmos2yfB4aCWCGy1TUN5VAnMRaY/edit?usp=sharing
考虑到美团外卖的业务场景,目标方案应该满足以下要求:
- 支持向量+标量混合检索:在向量检�索的基础上,支持复杂的标量过滤条件。
- 高过滤比:标量作为过滤条件,有较高的过滤比(大于99%),过滤后候选集大(以外卖商品为例,符合LBS过滤的商品向量候选集仍然超过百万)。
- 高召回率:召回率需要在95%+水平。
- 高性能:在满足高召回率的前提下,检索耗时Tp99控制在20ms以内。
- 数据量:需要支持上亿级别的候选集规模。
实现向量+标量混合检索,一般有两种方式:前置过滤(pre-filter)和后置过滤(post-filter)。前置过滤指先对全体数据进行标量过滤,得到候选结果集,然后在候选结果集中进行向量检索,得到TopK结果。后置过滤指先进行向量检索,得到TopK*N个检索结果,再对这些结果进行标量过滤,得到最终的TopK结果。其中N为扩召回倍数,主要是为了缓解向量检索结果被标量检索条件过滤,导致最终结果数不足K个的问题。
业界已有较多的成熟的全库检索的方案,后置过滤方案可以尽量复用现有框架,开发量小、风险低,因此我们优先考虑后置过滤方案。我们基于GPU的后置过滤方案快速实现了一版向量检索引擎,并验证其召回率与检索性能。GPU中成熟的检索算法有Flat、IVFFlat和IVFPQ等,在不做扩召回的情况下,召回率偏低,因此我们在benchmark上选择了较大的扩召回倍数以提高召回率。
测试结果表明,以上三种算法均无法同时�满足我们对检索性能和召回率的需求。其中IVF与IVFPQ召回率较低,Flat算法虽然召回率较高,但是与全体候选集计算向量相似度导致其性能较差。
根据用户的地理位置信息计算其GeoHash值,并扩展至附近9个或25个GeoHash块,在这些GeoHash块内采用Flat算法进行向量检索,可以有效减少计算量。这种向量子空间划分方式有效地提高了检索性能,但是存在某些距离稍远的商家无法被召回的情况,最终测得的召回率只有80%左右,无法满足要求。
综上,后置过滤方案无法同时满足检索性能和召回率的需求,而GPU版本的Faiss无法实现前置过滤功能,考虑到美团外卖的业务场景,向量+标量混合检索能力是最基本的要求,因此我们决定自研GPU向量检索引擎。
基于GPU的向量检索,要想实现前置过滤,一般有三种实现方案:
- 所有原始数据都保存在GPU显存中,由GPU完成前置过滤,再进行向量计算。
- 所有原始数据都保存在CPU内存中,在CPU内存中完成前置过滤,将过滤后的原始向量数据传给GPU进行向量计算。(能存更大的数据集)
- 原始向量数据保存在GPU显存中,其他标量数据保存在CPU内存中,在CPU内存完成标量过滤后,将过滤结果的下标传给GPU,GPU根据下标从显存中获取向量数据进行计算。(省显存带宽)
由于GPU与CPU结构与功能上的差异性,使用GPU完成前置过滤,显存资源占用量更大,过滤性能较差,且无法充分利用过滤比大的业务特点,因此不考虑方案1。
实验结果表明,方案2在数据拷贝阶段耗时严重,时延无法达到要求。因为在美团外卖的场景下,过滤后的数据集仍然很大,这对CPU到GPU之间的数据传输带宽(A30显卡带宽数据如下 CPU-GPU:PCIe Gen4: 64GB/s;GPU-GPU:933GB/s)提出了很高的要求,因此我们最终选择了方案3。
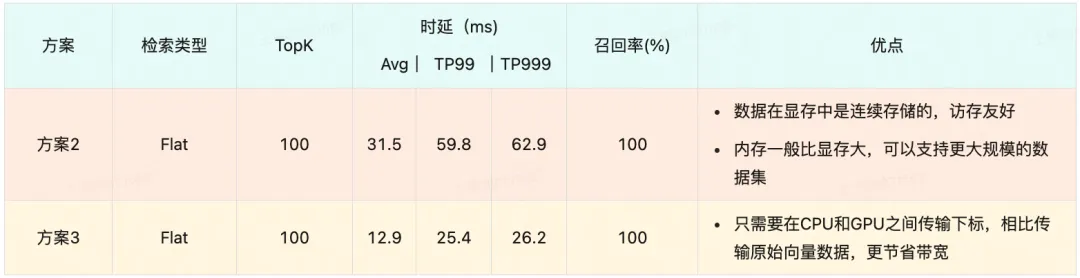
考虑到显存的价格远高于内存,因此我们在设计方案的过程中,尽可能将数据存储在内存当中,仅将需要GPU计算的数据存储在显存当中。
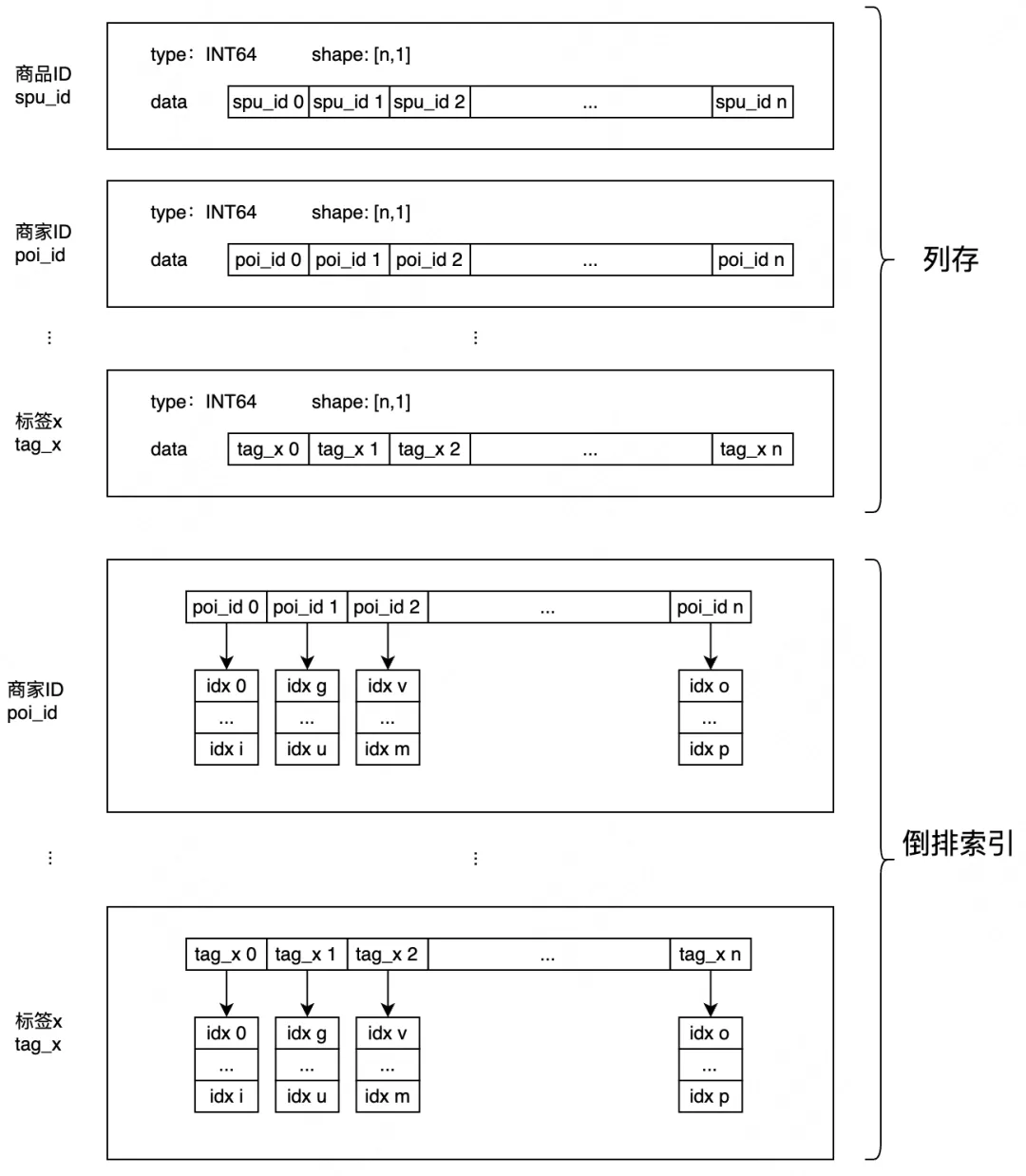
内存中保存了所有的标量数据,数据按列存储,通过位置索引可以快速找到某条数据的所有字段信息,数据按列存储具备较高的灵活性和可扩展性,同时也更容易进行数据压缩和计算加速。针对需要用于过滤的标量字段,在内存中构造了倒排索引,倒排链中保存了对应的原始数据位置索引信息,内存数据结构如下图所示
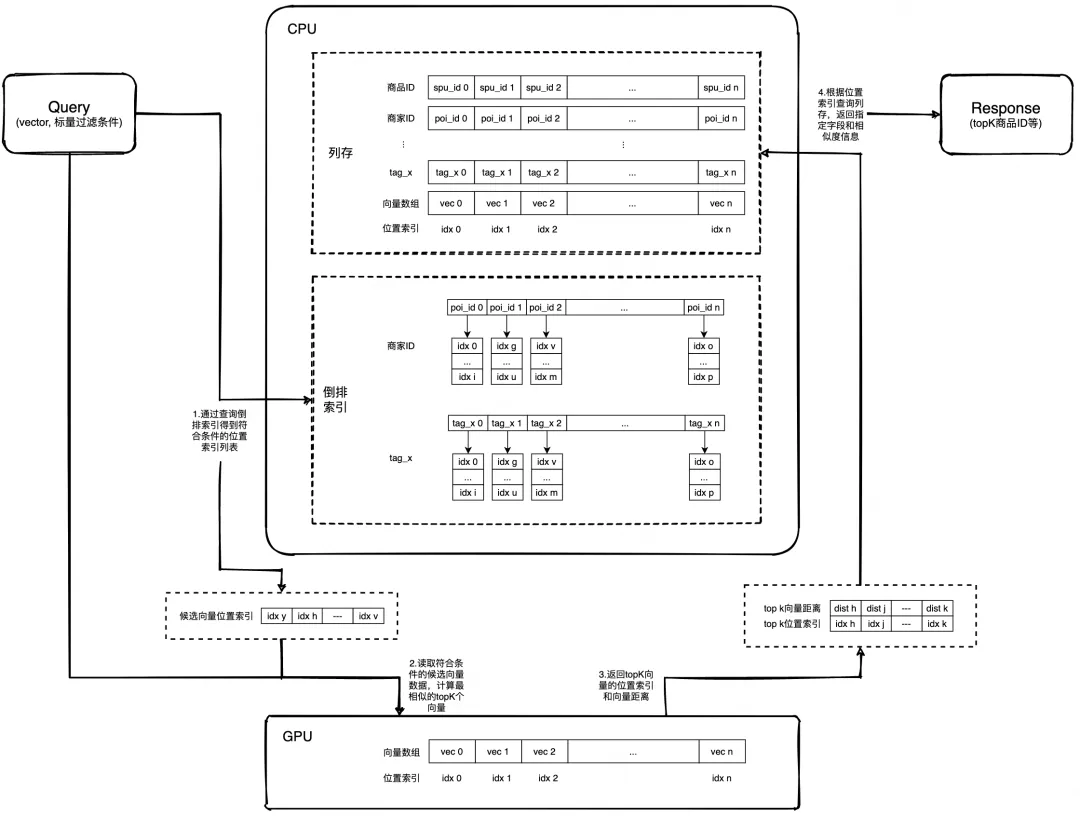
显存中保存了所有的向量数据,数据位置索引与内存中的数据一一对应,可以通过位置索引快速获取某条数据的向量信息,如下图所示:

最后的流程图(Flat)
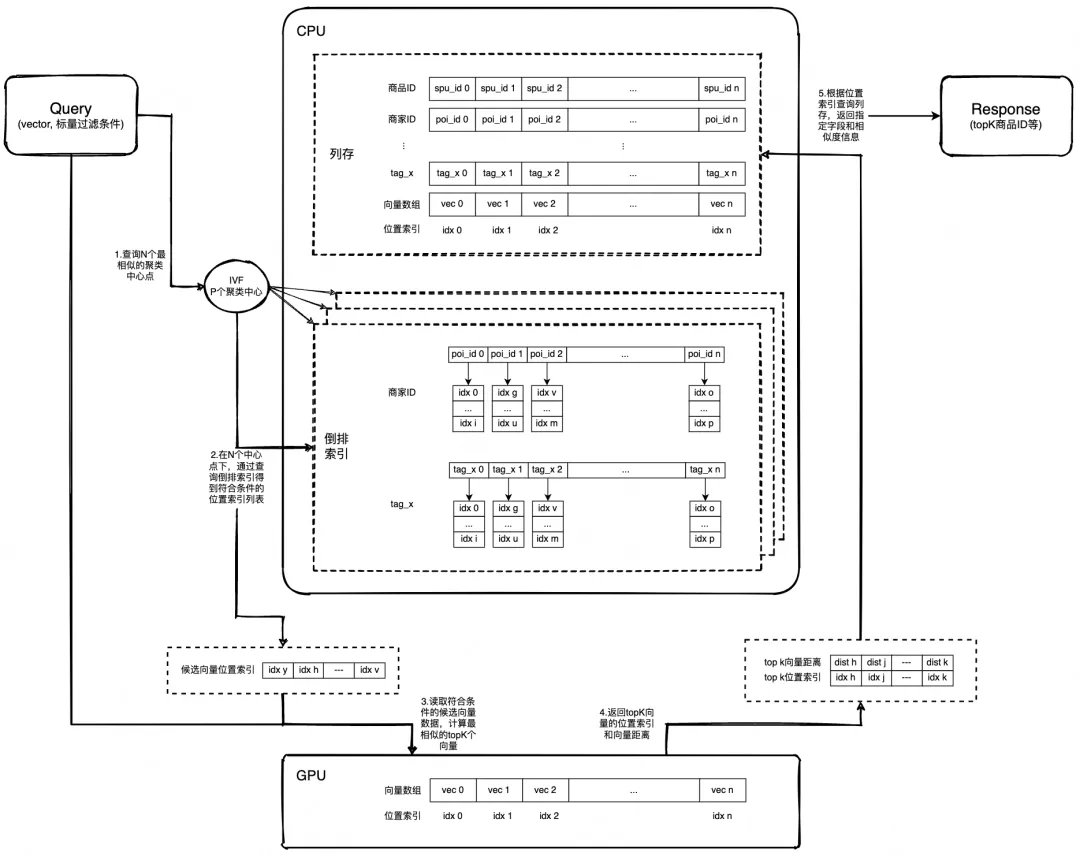
最后的流程图(IVF),放宽召回率,提升性能
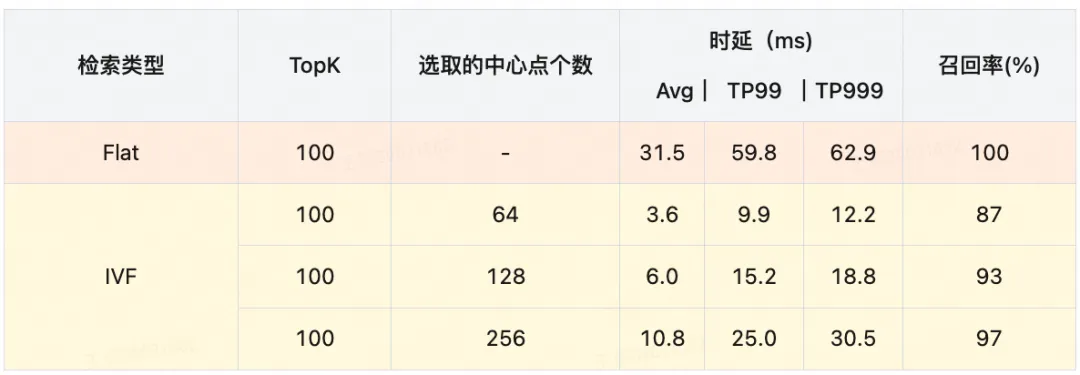
可见,无论是Flat还是IVF,在相同的召回率下,使用前置过滤的性能都要明显好于后置过滤。
性能优化
-
高并发支持,通过Cuda Stream,GPU可以并行处理多个查询请求,高并发压测下,GPU利用率可以达到100%。
-
通过GPU实现部分标量过滤功能,支持在GPU上实现部分标量过滤功能,向量计算与标量过滤同处一个Kernel,充分利用GPU并行计算能力
-
资源管理优化,支持句柄机制,资源预先分配,重复利用。每个句柄持有一部分私有资源,包含保存向量检索中间计算结果的可读写内存、显存,以及单独的Cuda Stream执行流;共享一份全局只读公有资源。在初始化阶段,创建句柄对象池,可以通过控制句柄数量,来调整服务端并发能力,避免服务被打爆。在检索阶段,每次向量检索需从句柄对象池中申请一个空闲的句柄,然后进行后续的计算流程,并在执行完后释放响应的句柄,达到资源回收和重复利用的目的
我们最终选择了单机多卡的数据分片方案,单台服务器部署多张GPU,检索时并行从本地多张GPU中检索数据,在CPU内存中进行数据合并。
为了支持更大规模的向量数据检索,我们还在GPU检索引擎上支持了半精度计算,使用FP16替换原来的FP32进行计算,可以节省一半的GPU显存占用,经验证Flat召回率由100%下降到99.4%,依然满足需求。使用半精度之后,单机可以加载近10亿数据,足够支撑较长时间的业务数据增长。
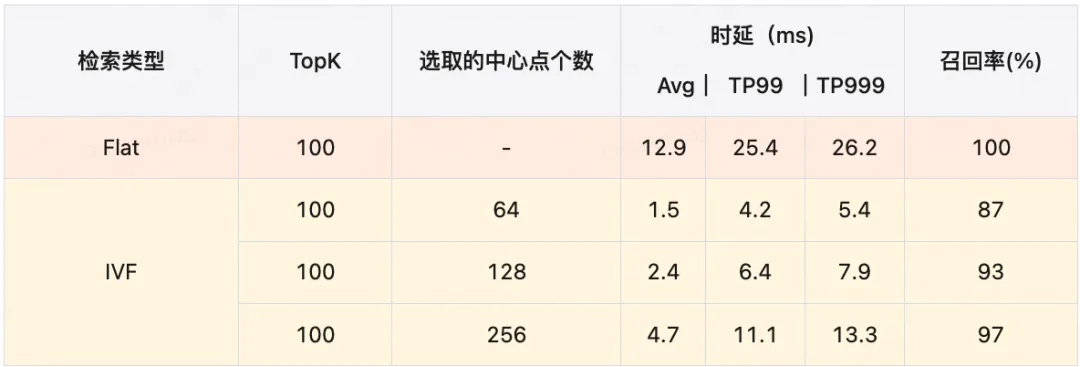
GPU 检索系统上线后实际性能数据如下(数据量1亿+):

22年还有一篇早期的搜索基于elasticsearch的优化实践
但这个就很工程很机架了