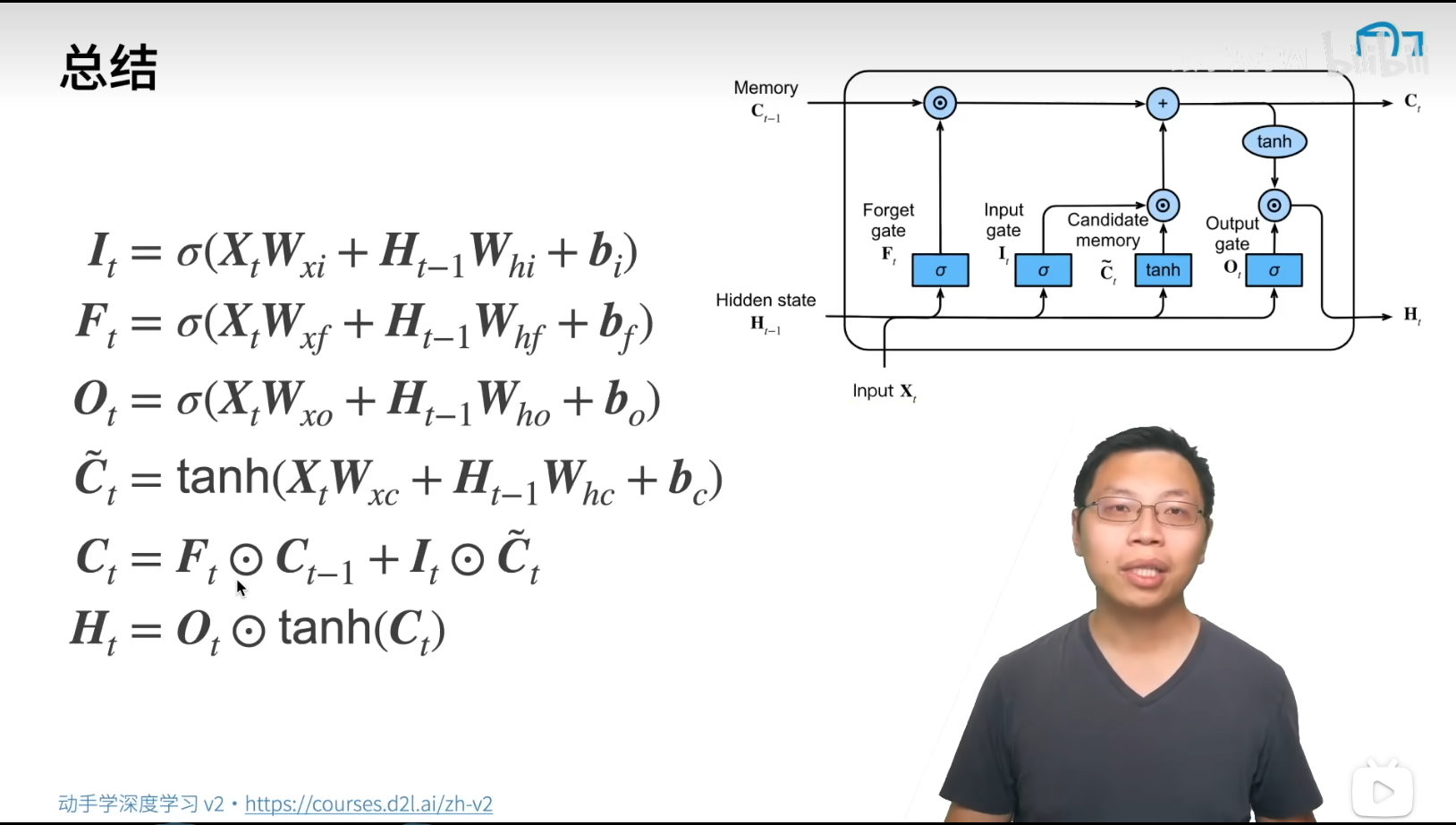
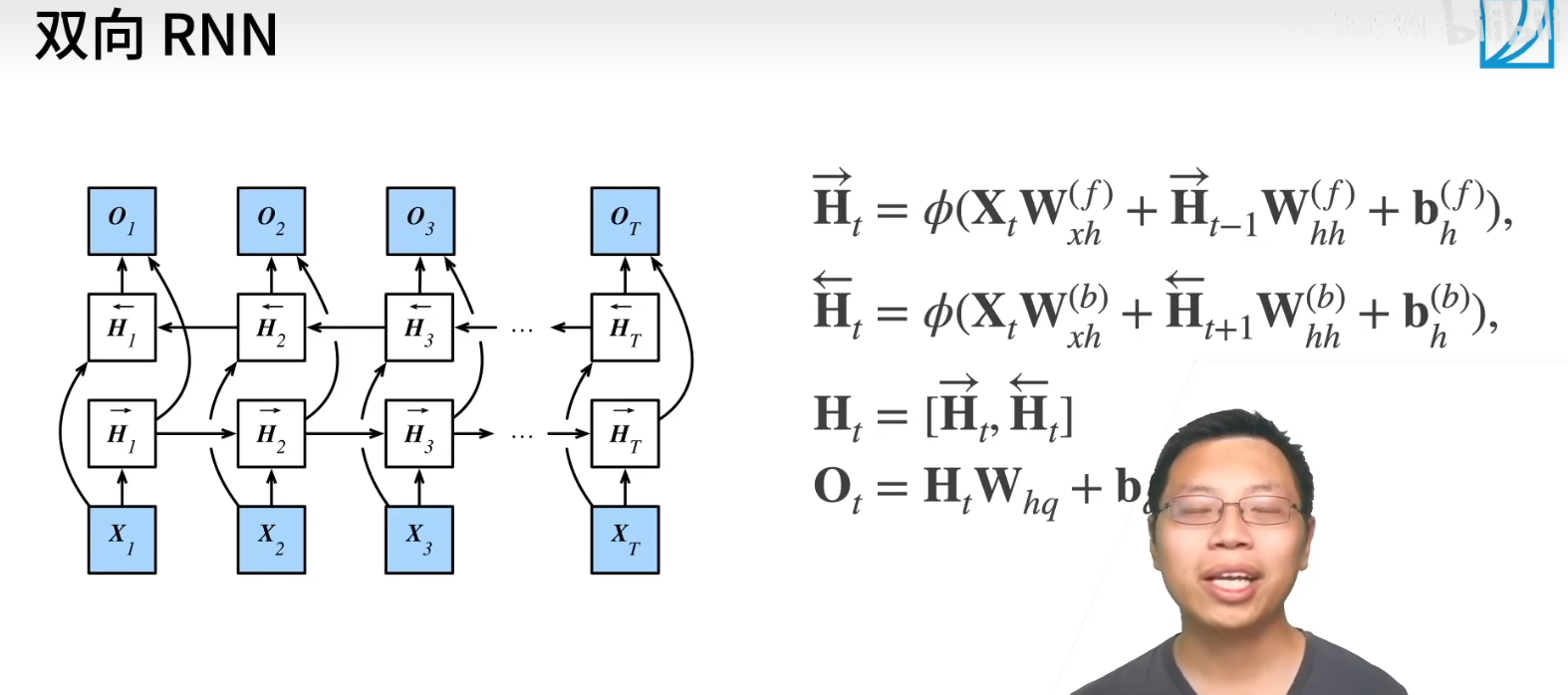
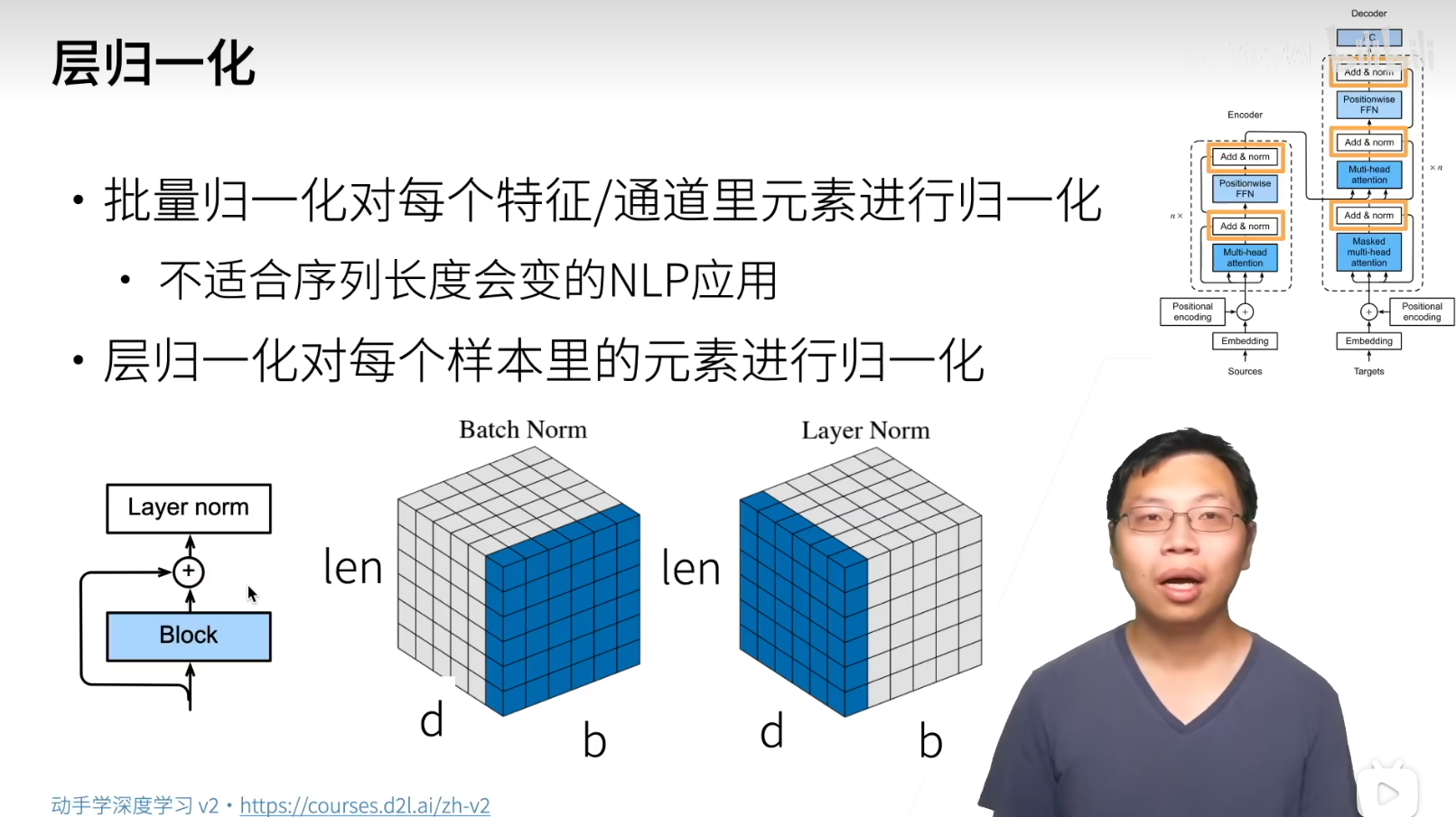
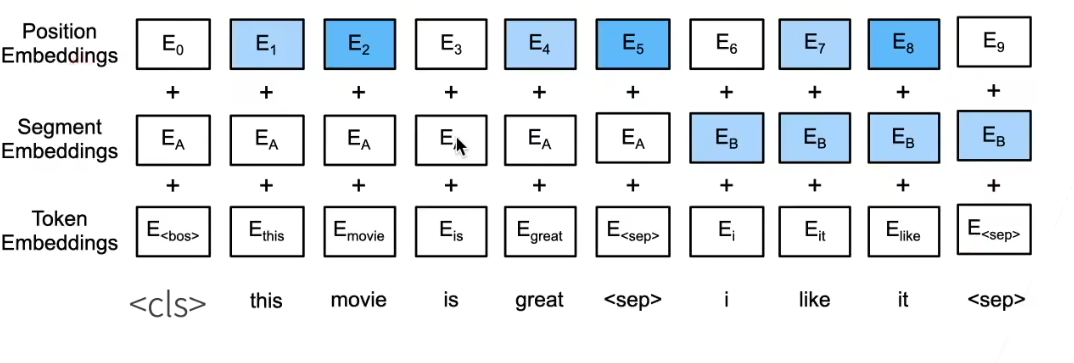
NJU操作系统(jyy OS)课程笔记-虚拟化部分
lec14 操作系统上的进程
cpu有初始pc地址->放置固件上的初始程序(固件状态机)->启动OS(os状态机)->load init程序(程序状态机), 之后OS完全把行为转交给init(进程树的root)
llm 知道存在与知道的界限正在模糊: 知道存在且合理 逐渐趋同于 能做
例如 qemu 相关的一些东西
问llm发散出的概念->知识体系的快速建立
fork? 以状态机的视角理解
经典的for fork + printf
写了个示例
#include <cstddef>
#include <cstdio>
#include <cstdlib>
#include <stdio.h>
#include <unistd.h>
#include <vector>
#include <mutex>
#include <sys/wait.h>
#include <map>
#include <string>
using namespace std;
const size_t buf_size = 1024;
const std::map<int, std::string> mode_map = {
{_IONBF, "no buffer"},
{_IOLBF, "line buffer"},
{_IOFBF, "full buffer"},
};
void test(int __modes) {
printf("test in mode %s\n", mode_map.at(__modes).c_str());
fflush(stdout);
vector<int> childs;
std::mutex mtx;
setvbuf(stdout, nullptr, __modes, 0);
for (int i = 0; i < 2; ++i) {
int pid = fork();
printf("hello from pid %d\n", pid);
if (pid > 0) {
std::lock_guard<mutex> lock(mtx);
childs.push_back(pid);
}
}
}
int main() {
// _IOLBF, _IOFBF, _IONBF
test(_IOFBF);
printf("\n");
fflush(stdout);
return 0;
}
在_IOLBF和_IONBF的情况下会出来6个hello
每次printf都直接刷新/检测到换行符刷新缓冲, fork的时候没有IO状态
而_IOFBF会有8个hello, 在fork第二次的时候会带着缓冲区(就是一段内存空间)进行fork,所以最后的4个进程每个都带着2个hello
系统里面没有魔法
fork: 把所有的知道的不知道的都复制了
“是不是这样?” -> 不知道的底层状态被复制了
execve: 重置状态机 argc, argv, envp -> main()
execve是唯一一个可以新建一个状态机的系统调用
exit?
- main return
exitlibc提供的_exit系统调用退出(== asm volatile("mov ..., %rax; syscall"))- 直接
SYSCALL
前两个在c语言的空间, 是“normal exit”
后两个不是normal的, _exit exit_group , __exit exit self
行为区别? strace
lec15 进程的地址空间
pmap
/proc/[pid]/maps
vvar(r), vdso(rx), vsyscall
os内只读的syscall -> 可以以内存的形式共享
其实只需要进程能和OS交互一些数据就行 —— why not进程写page, OS轮询?
- 在极端的时候能提高一些高优先级的进程的性能, 某篇OSDI
地址空间应该是在运行时可变的
所以我们需要一个不存在于c世界的操作(syscall)去操作地址空间 -> mmap, munmap
入侵进程的地址空间: gdb, perf
Game Genie 物理入侵地址空间
- 外接电路: 当cpu读地址a的时候读到x, 则替换为y
jyy现场演示mini CE(雾)
gdb attach到虚拟机,查找满足某个模式的内存值, 修改之
/proc/[pid]/mem 修改器 = 调试器
xdotool: cmd X11 automation tool
ydotool: better xdotool -> 按键精灵
evdev 按键显示脚本
xdotool测试vsc插件, crazy
或许不需要那么多的“魔法工具”
OS: 解放编程能力, 什么事情在OS上可以做
变速齿轮: syscall是感知时间的唯一方法
gdb 脚本之中, 在gettimeofday打断点, 然后修改寄存器, amazing!!!
hook
patching: 整活, kpatch, 不停机更新(软件动态链接)
old func, rx -> 修改为rwx -> 修改old func为, jmp到new func
在chcore里面看看? 或许有必要研究一下gdb(attach with qemu)
lec16 syscall & unix shell
everything is a file
thing: 操作系统里面的对象
gpt时代的“编程”——自然语言?
//OS: API:
// get_object_by_name(
// "the address space file of pid=1234"
// )
文件描述符: 指向OS对象的“指针”
windows: handle(句柄)
IPC endpoints: 例子, 管道
管道是同步的
fork + pipe? 本质是"指针"的拷贝
现在两个进程都有读口和写口啦
shell, kernel 的外壳
cli: 高效简洁的编程语言
算力的提升: cli -> gui -> 自然语言
shell as pl: 基于文本替换的快速工作流搭建
job control: 类比窗口管理器的"x", 最小化
或许不需要tmux, shell就是最简单的tmux
手册: complete ref
AI是“被动的”, 读一读shell manual
复刻unix shell
“抛开系统库”
-ffreestanding -nostdlib -static
gdb init已经很常见了, 但gdb init到python再在python里面转回/proc/[pid]/fd打印, 最后结合gdb的内置hook,在stop时候打印, fancy!
这打印的不是我们go的channel语法吗, 更有趣了
sh manual
lec 17 syscall的封装: libc
pipe write如果小于PIPE_BUF, 是原子的
pipe 7
读者关闭: Broken pipe
libc 标准化, 稳定可靠, 移植性极好
C runtime library: -Wl, --verbose看到链接列表
调试glibc? 历史包袱重, 大量内联汇编, musl
只要实现了C ABI指定的堆栈排布的系统调用, 就可以轻松移植musl等到自己的OS上, 底层的计算由硬件指令集给出
System V ABI
脱开workload 做优化就是耍流氓
- 在开始考虑性能之前, 理解需要考虑什么样的性能
workload哪里找? 当然是paper了(顺便白得方案)
- 看wkld调性能
mm alloctor: 根基
- 大对象应该有长生存期, 否则是performance bug
- 越小的对象创建/分配越频繁
- 小对象, 中对象, 大对象
瓶颈几乎是小对象
链表/区间树不是一个好想法: 上锁, 不能很好的并行化
设置两套系统:
- Fast path 性能极好,并行度极高,覆盖大部分情况
- Slow path 不在乎速度,但把困难的事情做好
- 例如cache
init ram fs
ISA -> OS 对象/syscall -> libc -> 系统工具 coreutils, busybox -> 应用程序
initramfs
-
加载剩余必要的驱动程序, 例如磁盘/网卡
-
挂载必要的fs
-
将根文件系统和控制权移交给另一个程序, 例如systemd
initramfs作为一个非常小的启动fs, 再把磁盘这个OS Object mount进来, 最后switch root把控制权给到磁盘的的根系统
启动的第二级阶段 /sbin/init
疯狂的事情不断有人在做, 但疯狂的事情的起点其实经常很小
lec 19 可执行文件
elf不是一个人类友好的“状态机数据结构描述”
为了性能, 彻底违背了可读(“信息局部性”)原则
可执行文件=OS的数据结构(core.dump), 描述了程序应该的初始状态
支持的特性越多, 人类越不能理解
人类友好: 平坦的
回归连接和加载的核心概念: 代码、符号、重定位
my_execve
elf file -> parse as struct
-> 将各个section load到指定的地址(mmap)->asm volatile布置好ABI调用栈(根据手册)->jmp!
如何释放旧进程的内存资源?proc里面需要有记录
lec 21 syscall & ctx switch
dynamic linker
se给的os基础还是很扎实的 很难想象ics2里面讲了GOT和PLT
SEE ALSO是一个宝藏 man ld.so
hacking: LD_PRELOAD不需要修改libc, 动态加载的全局符号, 先到先得
劫持大法!
kernel memory mapping
低配版Linux 1.X 分段, 内核在低位, 只是分个段
低配版Linux 2.X 内核还是在物理低位, 但程序看到虚拟地址已经是高位了
today: complete memory map
qemu is a state machine simulator: 调试syscall(gdb并不能si从用户态进kernel)
另一种理解中断的方式:"被"插入一条syscall
中断, 把状态机的整个寄存器状态存到内存里面
在汇编之中小心排布内存和搬运寄存器, 返回到c之中就是结构体的context
schedule的核心: 调用一个“不会返回的函数”
这个(汇编)函数以context为参数, 并且根据context, 返回到另一处控制流...
-> coroutine 也是如此! OS作为一个“状态机管理器”就在做一个"coroutine event handler"的作用
lec 22 process
进程: “戴上VR”的thread
有自己的地址转换, 对一切的load/store会应用一个f,作用在addr上
硬件提供了“戴上VR”的指令
这个f从ds的视角来说就是int->int的映射
查页表(int->int的映射)这件事, 如何加速? --自然想到radix tree
普通实现是radix tree(x86, riscv, ...收敛到的最终方案)
每一次访存都要查这么几次的话不可接受
因此有了TLB, 但立刻带来的一个设计问题是, 谁来管TLB(以及对应的miss处理?)
x86选择放到硬件, 但丧失灵活性的后果是即使有些进程只想要f(x)=x, 也必须要老实查表, TLB在和cpu cache抢带宽
MIPS选择放到软件, miss了直接丢出来异常, 让软件来决定怎么处理TLB
疯狂的想法: inverted page table
把key从VPN�换成 (VPN, pid), 然后从一一映射改成hashtable, 支持每个进程有自己的页表
缺点在例如hashtable带来的冲突时(TLB miss, etc)时间不可控(O(1) ~ O(n))
每个进程都有自己的“VR眼镜”这件事情还带来了更多的优化空间, 例如多个进程, 不同的虚拟地址块映射到同一个物理地址, 以及cow
KSM(kernel samepage merging/mermory deduplication), demand paging
fork: 进程快照, redis
cow fork的缺点: 让系统实现变复杂
改革: 砍掉所有的内核部分, 剩下的全部交给xv6
lec 23 处理器调度
trampoline code
跳板代码, 例子
- call printf -> call *GOT(printf)
- JIT编译器
- 软件热更新(patch 函数头)
资源调度(分配)是一个非常复杂的问题
建模, 预测, 决策 -> 调度策略的设计空间
调度策略
再加一层机制 "niceness", 管理员控制nice, 越nice越能得到cpu
10 nice ~ 10倍性能差异
taskset 绑定一个process到一个cpu上
round-robin时代: MLFQ, 动态优先级
-
让出CPU(I/O) -> “好”
-
用完时间片 -> “坏”!
1960s: breakthrough!
2020s: 对很多负载都欠考虑
今天的调度: CFS(complete fair scheduling)
但有vruntime, "好人"的钟快一些
真实的处理器调度: 不要高兴得太早...
- 低优先级的在持有mutex的时候被中间优先级的赶下处理器, 可以导致高优先级的任务等待mutex退化到低优先级
->火星车
Linux: 没法解决, CFS凑合用
实时系统: 火星车在CPU Reset, 不能摆烂
-
优先级继承, 条件变量唤醒?
-
lockdep预警
-
...
然而不止有锁, 还有多处理器...
今天的计算机系统: SMP
多处理器的矛盾困境
- 绑定一个线程:"一核有难, 八方围观"
- 谁空丢给谁: cache, TLB白干
更多的实际情况: NUMA, 异构, 多用户
-
numa: 远近cpu性能差达到数倍
-
多用户的cpu共享? namespaces, cgroups, 例如一个程序开并行, 另一个程序是串行的, 是否需要给串行的保留一个核, 而不是开得越多抢得越多
-
异构, 大小核超小核, GPUNPU, 每个核的独有缓存和共享缓存...
-
更少的处理器可能更快...(反直觉, 同步cacheline带来的开销)
复杂的系统无人掌控
ghOSt: Fast & Flexible User-Space Delegation of Linux
开始下放给应用程序做调度
Others
早期优雅的设计可能会成为后续发展的包袱: fork+exec带来的膨胀, 所有涉及到OS内部状态的api都需要考虑fork行为, 例如文件偏移量...
总线, 中断控制器, DMA
总线: 提供设备的“虚拟化”, 注册和转发, 把收到的地址(总线地址)和数据转发到对应的设备上
这样cpu只需要直连一根总线就行了!
PCI总线
- 总线可以桥接其他总线, 例如
pci -> usb
lspci -tv可视化
"即插即用"的实��现——非常复杂!
cpu: 只有一根中断线
启动多个cpu: cpu给其他cpu发中断!
中断仲裁: 收集各个设备中断, 选一个发给cpu
APIC(Advanced PIC):
- local APIC: 中断向量表, IPI, 时钟, ...
- IO APIC: IO设备
DMA: 很早期就有了, 解放cpu, 设计专用的电路只做memcpy
今天: PCI总线直接支持
文件 = 实现了文件操作的“Anything”
设备驱动程序: 一个 struct file_operations的实现, 就是一段普通的内核, “翻译”read/write等系统调用
/dev/null的驱动: read永远什么都不做返回0, write永远什么都不做返回count
一种"duck type"
设备不仅仅是数据, 还有配置
配置设备:
- 控制作为数据流的一部分(自定义一套write的指令编码)
- 提供一个新的接口
ioctl: 非数据的设备功能几乎完全依赖ioctl, 完全由驱动决定
数量最庞大,质量最低的shit
unix的负担: 复杂的hidden spec
/dev/kvm 硬件虚拟化, 支撑了几乎所有的云产商虚拟化方案
unix的设计: 目录树的拼接
将一棵目录树拼到另一棵上
回想最小linux系统, 只有/dev/console和几个文件
/proc, /sys, /tmp都是mount系统调用创建的
"看到的fs!=磁盘的fs", is just a view
像是procfs这种并非实际的fs更是, 可以挂载到任意的地方, 以任意的数量(因为他只是fake了read/write的“file Object”)
根本设计哲学: 灵活
灵活性带来的
/,/home,/var都可以是独立的设备, 把有些快的放在一个目录存可执行文件, 另一些存数据...
mount一个文件? loopback device
设备驱动把设备的read/write翻译成文件的rw
FHS: Filesystem Hierarchy Standard
ln -s 图结构 as 状态机
fs: 一个”数据结构题“, 但读写的单元是一个block
FAT: 集中保存所有"next"指针, 可靠性? 存n份!
fat manual
fat 小文件ok, 大文件不行