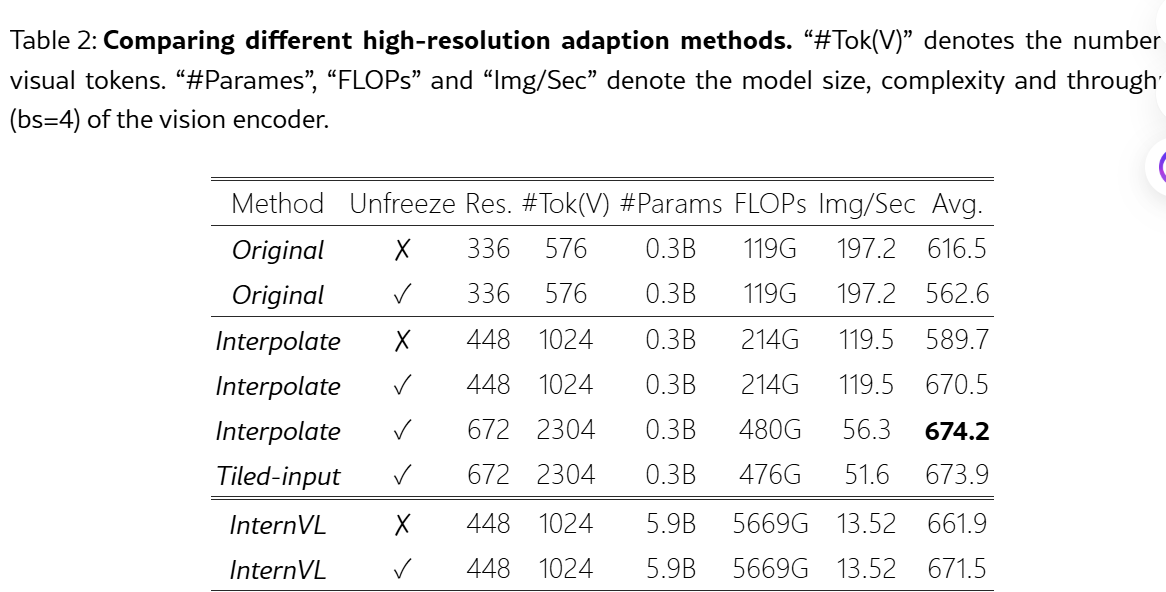
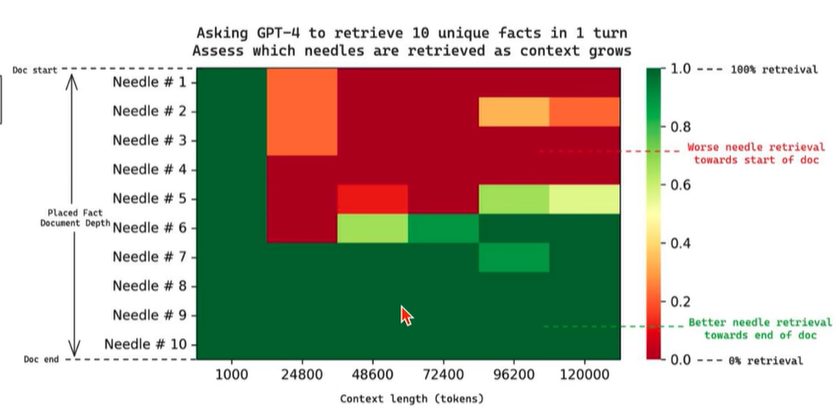
Langchain needle in haystack 实验
长上下文之后,越后面的部分的事实性细节越容易找,尤其是多事实的情况下
引发的一个思考是 rerank 时是否需要将最关注的块放在 prompt 的最后面,也就是倒序?
- 后补: 但其实又有attention sink相关的研究,可能还是需要具体任务具体测试分析
Maybe recency bias in LLMs:只记得最近的了
No retrieval guarantees
query analysis:将 question 联系到正确的文档
routing (to right DB)
full doc -> summary -> embedding: doc 中噪声非常大, summary 是必要的,语义层次的保留 level 通过 prompt 保证
self-reflection 听起来很美好,但实际常常用不到,太慢了,并且搜不出来更多是前期处理没做好,再换着花样也很难搜出来
HyDE 对于高度 Domain Knowledge 和抽象性理解的任务基本没用:
一些自己的解释
- 能否生成正确的假设文档, 难
- 即使通过先行的小批量搜索教导 LLM 根据这些 example 生成假设文档,也很难让 LLM 从这些文档中抽取某个泛化的问题,经常会 过度 specific 而导致后续漏掉文档
- 目前实验下来垂域脏文档类型最好的解决方案还是 reranker,embedder 如果不微调分布太接近了,例如全部的 chunk 都在 0.5~0.6 之间,意义寥寥
和数据分析的结合:
分析波动->(数据分析)找出波动的阶段-> 对每个波动的阶段做查询
GraphRag 这种 KG-based 的方法经常强调“对整个数据集信息的整合”
但这个要分领域,例如,个人知识库之中,这是好的
但垂域的知识文档常常是相似的格式,固定的路由,同时信息的整合关键不在“多实体”的关系上,而是在于“单个实体随时间的变化”上。
又或者说实体关系 R(e1,e2) 本身应该建模成一个包含时间的 R(e1,e2,t)
如果仅仅是靠新加入的文档来动态更新 KG 的话,滞后性会很强
在这种半结构化的模板式文档中,LLM 实际上在干一个 Fuzzy DB manager, 提取信息,充当一个搜索引擎
利用 KG 进行某种意义上的多跳推理本质上也只是对文档的多次检索,推理跳数越多,关系越复杂,离线生成 KG 就越难,不是所有领域都像是法律一样有一个明确的 A 判例引用 BCD 法条的连接关系的,这样复杂的 KG 在要想随时间变化也更不可能
从某种意义上来说,KG 是在横向生成,而类似金融这种领域的 RAG 做的是纵向的 Timeline, 这部分对于关键实体是有数据的,并且可能数据都不需要自己做(例如各种行情的图),而离线准备好这些 timeline 之后,如何在 timeline 上进行一个跳跃和查询分析才是关键的。
如果从 DB 的角度上分析的话,金融领域这种关注点快速变化的 RAG 系统(with cache)也就相当于 lazy generated timeseries DB 了,例如问了一个 A 的价格变化,就像是生成了一个 time, delta_price, event(detail) 的 timeseries DB 表,把生成 reason 这样的 LLM 工作 lazy 化了而已
chunk 的前总结和后总结(离线在线)
离线总结最大的问题在于总结哪些方面,实际上是文档预处理的一个部分
最简单的方法就是整个提示模板每个 chunk 问一次 LLM,有 langchain 的 map reduce 等稍微 high level 一点的工具可以支持这个事情
对长文档总结更有效一些的做法是利用好 embedding,先对 chunk embedding 做聚类,再每个聚类里面抽几个 chunk, 从而保证多样性和 chunk 数量的平衡
后总结,或者说 query-based 总结大体上是用 LLM 做比较多,但对于时延和开销的增加太高了,一个比较新的方法是 paragraph sentence-level mask bert(自己造的词),在段落中根据 q, d 的交叉编码得到句子级别的二进制掩码,从而删除无关部分。有一篇 ICLR2025 基于 bge 训了个,https://huggingface.co/blog/nadiinchi/provence
provence效果非常好,又快又几乎对齐例如GPT4.1这种顶级模型的效果
另一个思路就是绕过这个问题,切小块,依赖 rerank 和重新合并乃至知识图谱检索之类的策略保证相关性,也就是在查询完之后是合并还是切分的思路差距
半结构化数据
https://docs.superlinked.com/getting-started/installation 聚焦半结构化的异构数据,例如朴素 embedding 方案对数字的理解不足,无法建模 1-99 的相似度分数与 higher/lower 这种文本的关系
https://github.com/microsoft/multifield-adaptive-retrieval 做多字段的权重学习(自适应选择查询应该着重的权重)
embedding 相关的调优
colbert架构是一个better embedding的方向,其核心在于将文档的token level embedding保存下来,对于每一个query token,计算maxsim算子得到单token的score,再求和

对比朴素embedding方案,它在token level进行计算可以很好的带来类似关键词匹配的效果,有效避免长文档下,embedding过于平均化余弦相似太不敏感的问题
对比rerank方案,它的优点又在嵌入矩阵可以离线计算,不需要完全在线的交叉编码器
引入方案: https://python.langchain.com/docs/integrations/providers/ragatouille/
Prompt
基本没有什么特别通用的工作,但值�得一提的是将prompt作为一个优化变量,使用LLM在Trajatory上进行采样和跑各种论文的“prompt优化算法”的解耦框架dsPy https://dspy.ai/ 用户以类似类型/对象系统的简短注释提供给dspy作为“初始意图”,而后续复杂的提示由dspy生成,核心思想是让用户专注于编程
class CheckCitationFaithfulness(dspy.Signature):
"""Verify that the text is based on the provided context."""
context: str = dspy.InputField(desc="facts here are assumed to be true")
text: str = dspy.InputField()
faithfulness: bool = dspy.OutputField()
evidence: dict[str, list[str]] = dspy.OutputField(desc="Supporting evidence for claims")
context = "The 21-year-old made seven appearances for the Hammers and netted his only goal for them in a Europa League qualification round match against Andorran side FC Lustrains last season. Lee had two loan spells in League One last term, with Blackpool and then Colchester United. He scored twice for the U's but was unable to save them from relegation. The length of Lee's contract with the promoted Tykes has not been revealed. Find all the latest football transfers on our dedicated page."
text = "Lee scored 3 goals for Colchester United."
faithfulness = dspy.ChainOfThought(CheckCitationFaithfulness)
faithfulness(context=context, text=text)
DSPy 中的不同优化器将通过为每个模块合成良好的小样本示例 (如 dspy.BootstrapRS 1 ) 来调整程序的质量;为每个提示提出并智能地探索更好的自然语言指令 (如 dspy.MIPROv2 2 ) ,以及为您的模块构建数据集并使用它们来微调系统中的 LM 权重 (如 dspy.BootstrapFinetune 3 )
LLM评估
测试不可靠:有多少答案是被记忆出来的?
有多篇相关的paper在讨论这个问题,然后采用了一些方法来衡量这个事情,例如,在数学问题题集中,替换无关的描述、修改数字等等,看看模型性能变差多少
类似数学问题集这种在网络上数据中很难过滤干净,还需要考虑多语言影响
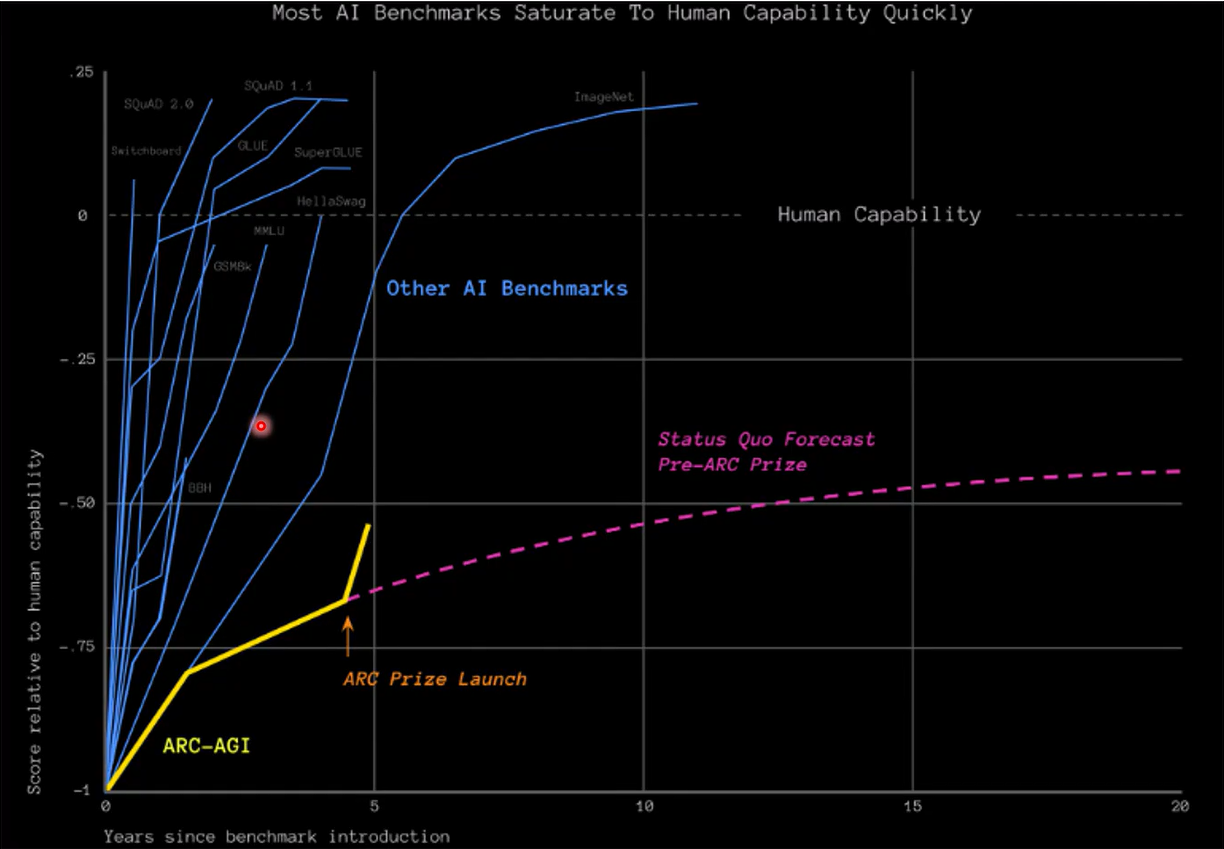
另一些评估指标如ARC-AGI通过抽象图像智力问题集来评估模型的推理能力,相对来说泄题风险小一些(并且有隐藏test set)
- 丢给LLM的时候不是图像,而是矩阵,用数字表示不同颜色
Chatbot Arena: 让全世界的人都来进行判断哪个模型好
但还是有办法hack: 更fit人的倾向(粗体字、分点、emoji.....)
Elo Score 考虑除了人的直接倾向之外其他因素的影响,在BF模型计算时加上一项β0, 1+exp(βi−βj+β0)1=Eij, Eij 是模型i和j的胜率,βi 是模型i的真实评分,β0 是一个全局偏差项,表示人类评估者的偏好。通过最大化似然函数来估计参数βi和β0,从而得到模型的真实评分。
β0=γ1∗长度差+γ2∗emoji个数差+γ3∗...
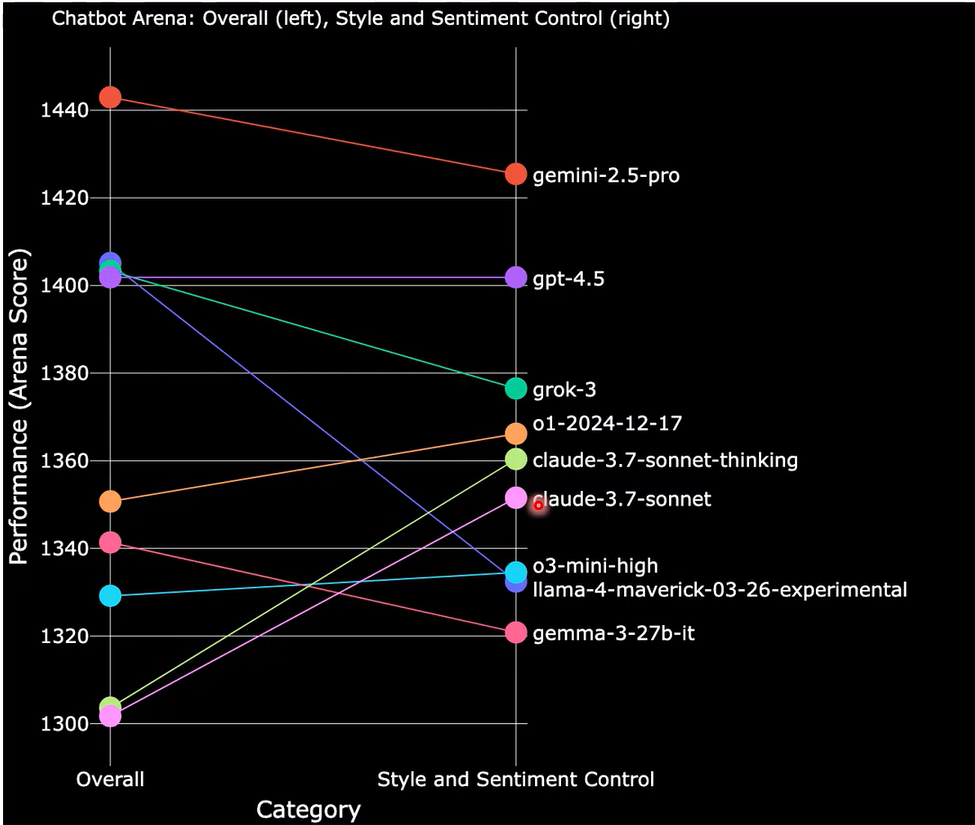
可以看到,考不考虑这个β0,模型的排名差别很大
Goodhart's Law
一旦一项指标被用作目标,它就不再是一个好的指标
http://becomingahacker.org/integrating-agentic-rag-with-mcp-servers-technical-implementation-guide-1aba8fd4e442
However, traditional RAG has limitations: it usually queries a single data source and only performs one retrieval pass, so if the initial results are poor or the query is phrased oddly, the answer will suffer
但是,传统的 RAG 存在局限性:它通常查询单个数据源,并且只执行一次检索传递,因此如果初始结果不佳或查询措辞奇怪,答案将受到影响
There’s no built-in mechanism for the system to reason about how to retrieve better information or to use additional tools if needed.
系统没有内置机制来推理如何检索更好的信息或在需要时使用其他工具。
关于结构化输出的另一篇特别好的文章: https://www.boundaryml.com/blog/schema-aligned-parsing
推理加速:是对的,例如huggingface-text-embedding项目,将各种转trt/onnx 可以让吞吐提升5x
H100 bge-reranker-v2-m3 1024 * 512char sentence, 13s -> 2.3s
关键词抽取
基于主题LDA,词典等
小模型方法:先用spaCy、hanLP等得到语法树,再从语法树中拿到名词性关键词等
无监督,经典如YAKE!综合考虑词频,词位,共现等。可以考虑https://github.com/JackHCC/Chinese-Keyphrase-Extraction
一篇非常有insight的blog:上下文相关!=上下文充足,定量充足性和它的应用
https://research.google/blog/deeper-insights-into-retrieval-augmented-generation-the-role-of-sufficient-context/