迈向真实世界的软件智能体:如何将语义高亮功能融入智能体编程?
引言
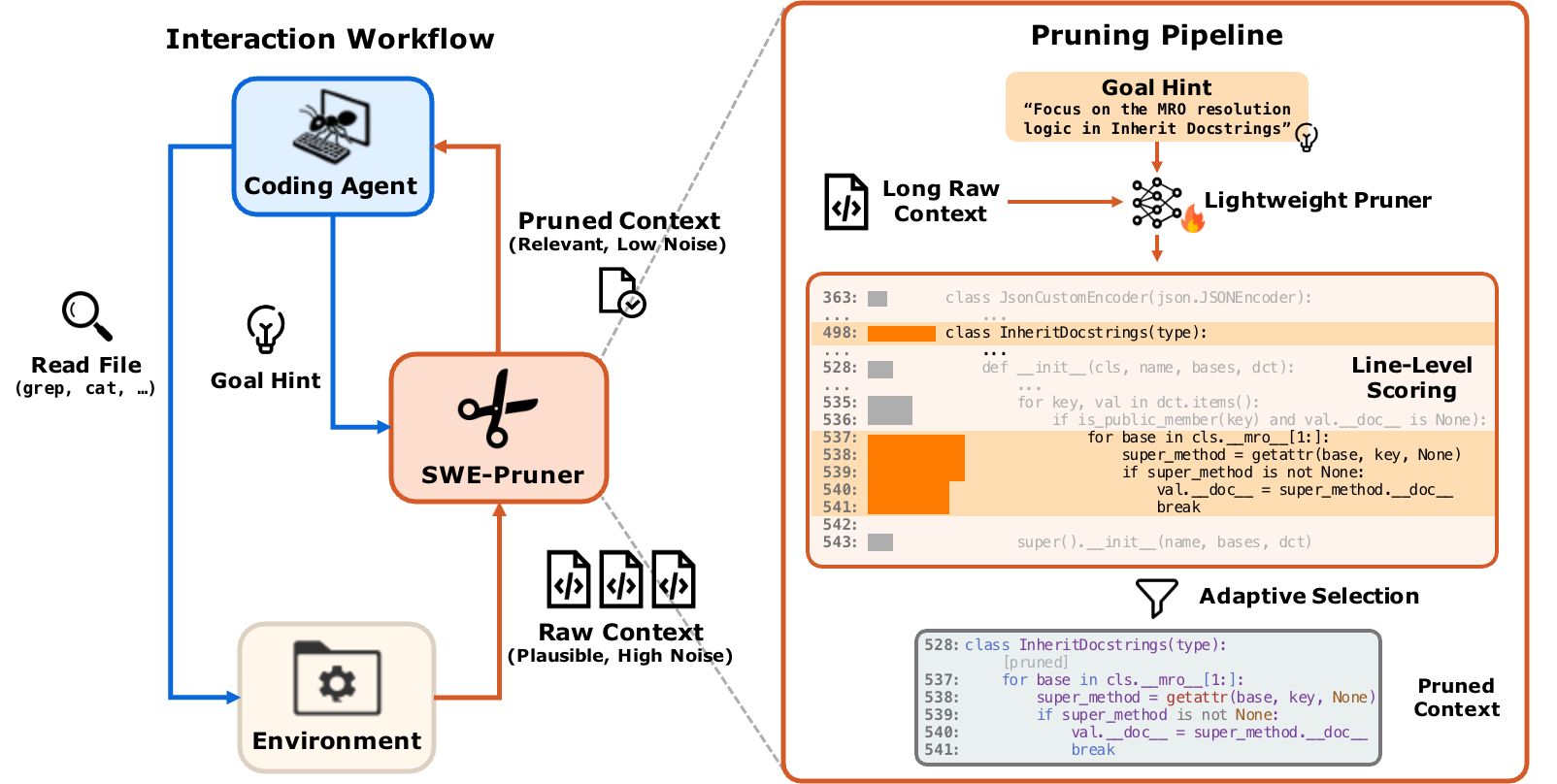
我们训练了一个代码语义高亮模型SWE-Pruner并开源了配套的Agentic接入框架,在真实的Coding Agent多轮任务(SWE-bench, SWE-QA)上,在保持性能不变甚至提升的情况下提供多轮场景下30%甚至更多的token开销减少。该模型基于语义理解,自动识别并高亮检索到的文档中语义相关的句子。而框架作为agentic的接入层,可以轻松接入claude code,openhands等SOTA agent系统
模型发布
- HuggingFace: https://huggingface.co/ayanami-kitasan/code-pruner
- License: MIT (commercial-friendly)
- Architecture: 0.6B Dual-Head model based on Qwen3-Reranker-0.6B
- Supported Programming Languages: Python
- Github: https://github.com/Ayanami1314/swe-pruner
- arxiv:https://arxiv.org/abs/2601.16746
在本文中,我们将分享我们的技术方案。
问题:编码代理的上下文膨胀
在先前的RAG工作中,上下文的粗粒度膨胀已经是一个很严重的问题 https://huggingface.co/blog/zilliz/zilliz-semantic-highlight-model
在生产环境中的 RAG 系统中,一个典型的查询会检索 10 个文档,每个文档包含数千个词元,每次查询消耗数万个词元。问题在于: 只有几十个句子真正包含相关信息 ,其余的都是噪声,这会增加成本并降低答案质量。
然而,对于真实环境下的软件工程任务,问题甚至更加严重:一个典型的查询可能涉及上百个代码文件,而一些大型项目中,巨型文件的代码token包含的远不止数千个,现代的编程agent却仍然在广泛使用关键词匹配的方法,即grep,来对大型代码仓库进行探索,匹配项的过分庞大使得现代agent中都配备了相当多的上下文硬截断逻辑

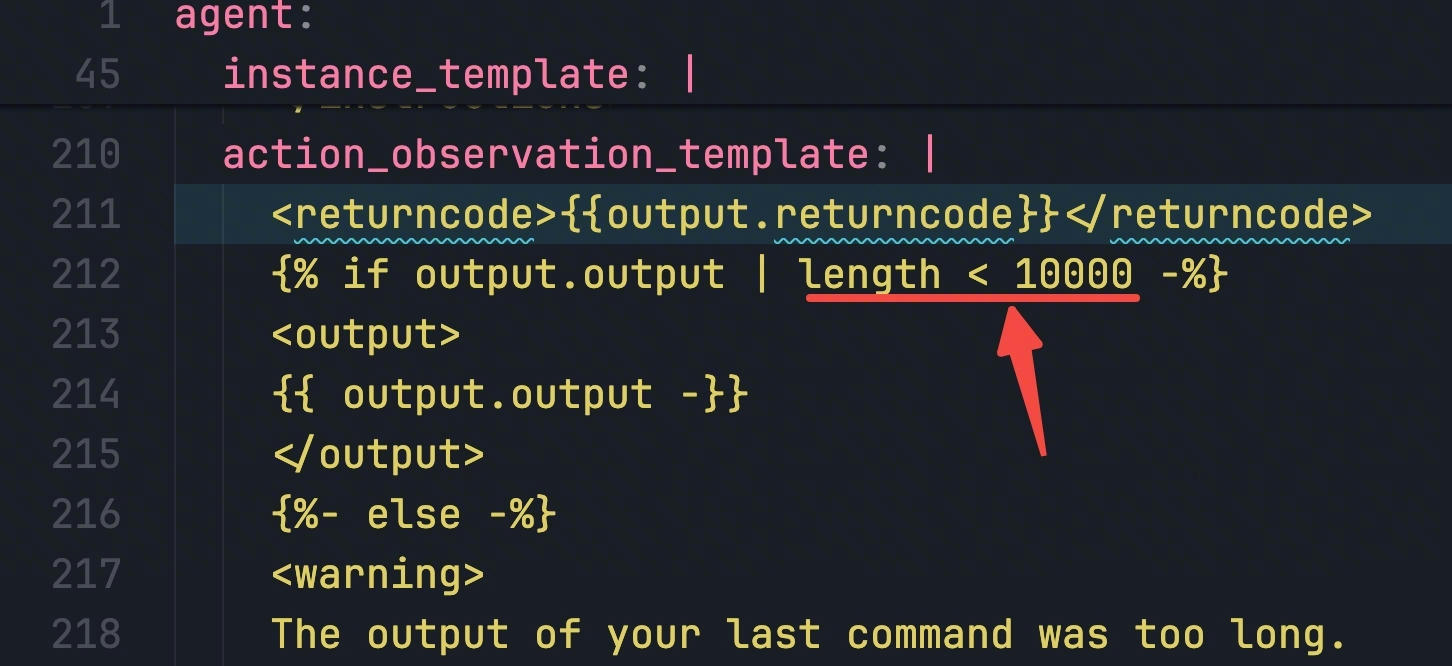
在人工智能代理场景中,这个问题会变得更加严重,因为查询是经过推理和分解后的复杂指令。传统的高亮显示方式只是机械地标记匹配的词语,却会遗漏真正有价值的分析结论。
这就迫切需要一种有针对性的高亮模型,该模型仅保留上下文相关的代码,并高亮显示它们,同时剪掉所有无关的噪声内容——这种技术也被广泛称为上下文剪枝。类似的纯文本任务也被Provence为代表的一系列工作较为完善地解决,但对于究竟如何在代码任务上引入语义高亮模型,社区尚未给出一个答案。
现有模型的困境
我们调研了现有的解决方案,但发现它们并不完全符合我们的需求。
Provence/XProvence,OpenProvence,zilliz/semantic-highlight-bilingual-v1沿用Provence的思路继续优化Provence的上下文长度和多语言性能。然而,它们并没有指出在代码等非纯文本场景下,如何构造合理的粗细粒度,如何满足额外的AST约束等。

另一个困境是,现有的模型沿用BGE的类BERT管道,但大部分现代代码嵌入模型都是LLM架构,decoder-only的模型如何设计裁剪头来处理特征的交互和输出的合理性仍是一个待解决的问题——BERT自然双向注意,但decoder模型需要某些“代偿”因果掩码单向注意的方案。
我们的选择
既然市面上没有这样的代码剪枝模型,那我们自己训练一个
第一个问题是在代码中,如何将纯文本里面的细粒度“句子”转换成代码的对应概念?
我们提出两套方案,基于代码行和基于AST statements,鉴于数据的生产难度,我们选择了以行取代句子作为细粒度
第二个问题是,选择什么样的模型?
BGE-m3是非常好的模型,但它没有针对代码数据进行大规模预训练;BAAI的另一个优秀模型是BGE-Code-v1,但社区对它的适配相对较少
我们注意到了社区的另一个工作modernbert,然而出于数据分布或是模型表达能力等原因,我们并没有在这个模型上训练成功
我们的猜想是——代码任务对基础模型的能力提出了可能超越大部分旧BERT模型的要求
最后我们采用的是Qwen的新模型,Qwen/Qwen3-Reranker-0.6B, 它的海量预训练数据和世界知识产生了相当好的代码嵌入,0.6B的大小又和传统bert类模型开销接近,LLM模型作为基底的另一个好处是自然完成了多语言query的适配。
类似Qwen这种LLM based reranker依然采用Casual Mask,这对token打分实际造成了一些影响,添加一个Full self-attention模块能让模型在测试集上的F1上升接近0.1
我们实验了不同的架构设计和特征trick,发现几个训练技巧对这个任务比较好用:
- 冻结大部分层:我们发现只解冻最后两层和全参数微调差距极小,而冻结之后更能避免过拟合,训练速度也更快
- 特征融合:对于LLM不同层数的特征作用,在先前已经有了相当多的工作进行讨论,一般认为浅层会有更多的语法信息,而深层则更重语义,将浅层、中间层和深层做简单的concat接入下游即可显著提升token打分头性能(我们使用的是7, 14和28层)
- Sample Loss Norm: 代码片段的长短有着很大的差别,更关键的是,与文本领域大部分的信息都是稀疏不同,保留的代码行既有稀疏的片段(大部分行被删除)、又有稠密的片段(大部分行被保留),且长度上也有比较大的区别。如果简单在token level计算,模型训练相对不稳定,将每��一个样本的loss使用样本的长度归一化能更好的平衡长短样本
- CRF Layer:我们特殊设计了Token打分头的模型结构,使用CRF层进行序列建模,取代BERT风格的mlp层,实验证明对于改进模型的稳定性有一定帮助
模型架构&训练
我们设计了一个如下图的模型架构,它在思路上借鉴了Provence,但细节做了大量改动
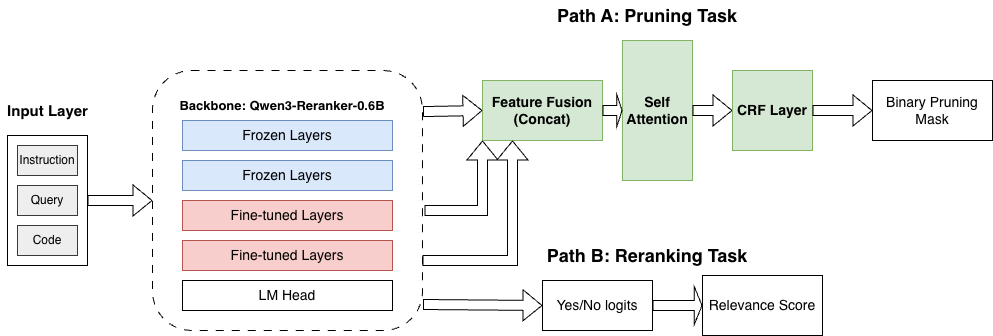
此外,我们使用了和Provence相同的做法保留了基础模型的原始rerank头, 即图中的Path B,这种Rerank-While-Prune的方式进一步降低了在RAG管道等场景接入模型的成本。
最终,我们使用8 * H100 训练了3个epoch,用时大约是4个小时。
我们的具体训练超参数可以在论文中找到。
推理过程:
推理过程非常直接:
- 将输入拼接为
指令 + 查询 + 代码 - 对上下文中的每个 token 进行打分(范围在 0 到 1 之间)
- 对每行内所有 token 的得分取平均,得到该行的得分
- 根据阈值保留得分高的行,同时移除得分低的行
一个有趣的细节是阈值的选择,在Provence的开源模型之中,他们推荐将threshold设置为0.1来保守裁剪;而我们阈值调优实验发现,和训练保持一致的0.5阈值就能在下游任务中达到最佳性�能,而0.1似乎过于保守——0.3已经会保留非常多的部分,这也可能是代码数据的分布特点和文本不同所导致的,在下文中会详细说明。
训练数据:如何构造“部分相关”的查询-代码对?
我们使用Qwen-Coder-30B-A3B-Instruct,从github 2025年的新仓库上自行构建数据(再次感谢qwen团队的优秀工作!),在来自6k个仓库、19w个文件的20w条代码片段上,使用了9个种子任务构建数据,并使用Qwen3-Next-80B-A3B-Thinking进行质量筛选,最后得到了约5万条高质量“部分关联query code对”
为什么是“部分相关”?
与文本领域不同的是,代码领域的QA数据集相对较少,缺少类似ms macro这样规模的query,code对;另一个问题是,由于缺少搜索引擎商开源的数据,现有的code query数据集的query往往分布偏窄,常是“这个函数的功能是什么?”“这段代码的运行结果是什么?”这种与整段代码相关的查询
但我们想要在代码之中引入semantic highlight功能,需要的是对“部分代码”的查询,例如,“这一条if分支会产出什么结果?” “这个类的属性A的作用是什么?”,这样我们才能划分出highlight的部分
也就是说,我们最后的数据集格式会是类似 <查询,原始代码,highlight部分> 的三元组
如何保证数据质量
数据质量直接决定了最后模型的性能,乃至训练是否能够成功。我们采用了以下几种方法来提升数据质量和解决实际遇到的问题。
- 问题:模型产出的query同质化比较严重
- 解法:定义代码重构、代码debug、代码解释等9个种子任务,构建时随机抽取,让模型根据种子任务写短/中/长不同长度,不同相关程度的查询
- 问题:代码片段太短,较难从中捕捉不同的执行流分支;代码片段太长,行数会变得过多(相比于Provence大部分段落在5-10个句子的情况,我们的代码段取的大约是100-150行)
- 解法:让模型使用range格式表示最终的“相关片段”,即1,4-10,16-28这样的区间,来避免模型陷入不断输出下一个数字的坏情况
- 问题:模型会认为大部分代码行都和query “有点关系”,相关度难以量化
- 解法:借鉴Provence的prompt设计,让模型仅根据提供的代码片段回答query,并要求引用,仅将回答中引用到的片段视为相关部分
- 问题:由于行数过多还是会出现一些bad case
-
解法:将构建的数据集使用Qwen3-Next-80B-A3B-Thinking筛选,判断其在代码结构保留程度,query质量和相关性质量上的表现。代码结构的筛选也是我们的方法在裁剪后AST正确率上领先其他方法的重要基础,在编程语言这种高度结构化的文本中,缺少一个
:或}都会导致整个语法树崩溃。压缩方法 AST 语法正确率 (%) 无压缩 (Full Context) 98.5 Token 级压缩 (如 LLMLingua2) 0.29 Function RAG 92.3 Pruner + Function RAG 87.3
-
为什么选择这些模型/数据集?
我们认为,github的原始代码最能够保证和真实用户数据的分布接近,同时具备足够的、真实场景的多样性
使用Qwen-Coder-30B-A3B-Instruct有以下几个原因:
- 性能稳定,我们抽取了部分样例人工校验模型认为的“相关代码”是否符合人类的观点,它的符合程度相当高
- 速度非常快——我们使用vllm的offline推理模式在24h左右的时间,8 * H100机器上完成了20万条数据的构建和筛选;而对应的GLM-Z1-32B等dense模型则需要一周
而使用Qwen3-Next-80B-A3B-Thinking则是在含有思维链情况下平衡速度和质量的一个优解
评估1:单轮任务
我们在多个数据集上对比了不同模型的性能,包括:
- LongCodeQA
- LongCodeCompletion
评估的方法包括 我们的模型, RAG, LLMlingua2, selective context, LongCodeZip 等, 实验中swe-pruner的压缩率向下取整,其他方法的压缩率向上取整(实在难调平)
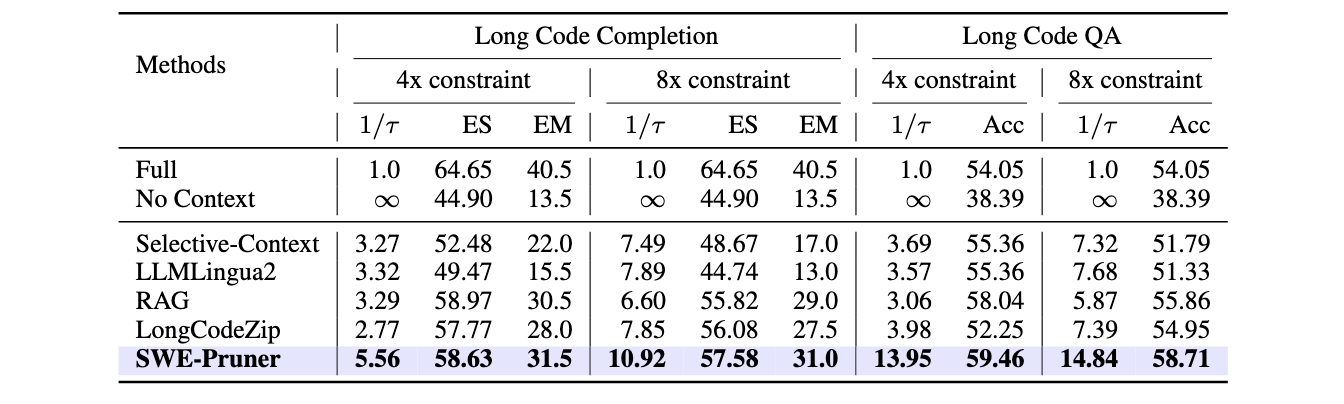
主要发现:
- 上下文噪声的去除不会影响QA的性能,甚至可能因为噪声的去除有所提升
- 我们的模型在压缩率上要远远超出其他方法 —— 事实上为了调整不同方法的压缩率到近似可比,我们花了非常大的力气调整超参数
- 我们的模型取得了所有压缩率下的SOTA
还有一个有趣的发现是,以Qwen3-Reranker-0.6B这种LLM based reranker作为基底,它的自定义instruction能力让下游任务的泛化更加轻松了。例如代码补全任务的query是上一行代码行而不是自然语言文字,这对于大部分模型其实是难以理解的,但我们可以在instruction中描述补全任务,使得模型在训练相对少的补全任务上性能也相当不错。
智能体服务:不止于 RAG
在构建了这样的模型之后,我们回到了我们的初始想法,如何将其融合到现代的Code Agent呢?虽然CodeRAG也是很广泛的范式,但也有相当多Agent是使用Grep作为搜索的工具,比如我们用得最多的Claude Code
更进一步的,会令上下文爆炸的,其实很多时候是ReadFile而不是Grep,我们想要削减上下文的开销的话,应该也对ReadFile处理好冗余上下文的问题
所以,我们设计了一个最小侵入的highlight模型接入方式,它不仅能服务于CodeRAG,还能服务于Grep, ReadFile乃至任何阅读工具
具体的做法是,假设有一个工具A,会产生一些输出,现在在工具A的原始参数基础上,增加一个参数context focus question,SWE-Pruner就可以根据这个question对A的输出进行裁剪 —— 而A可以是cat, grep, rag search, 甚至像是我们论文之中更暴力的bash

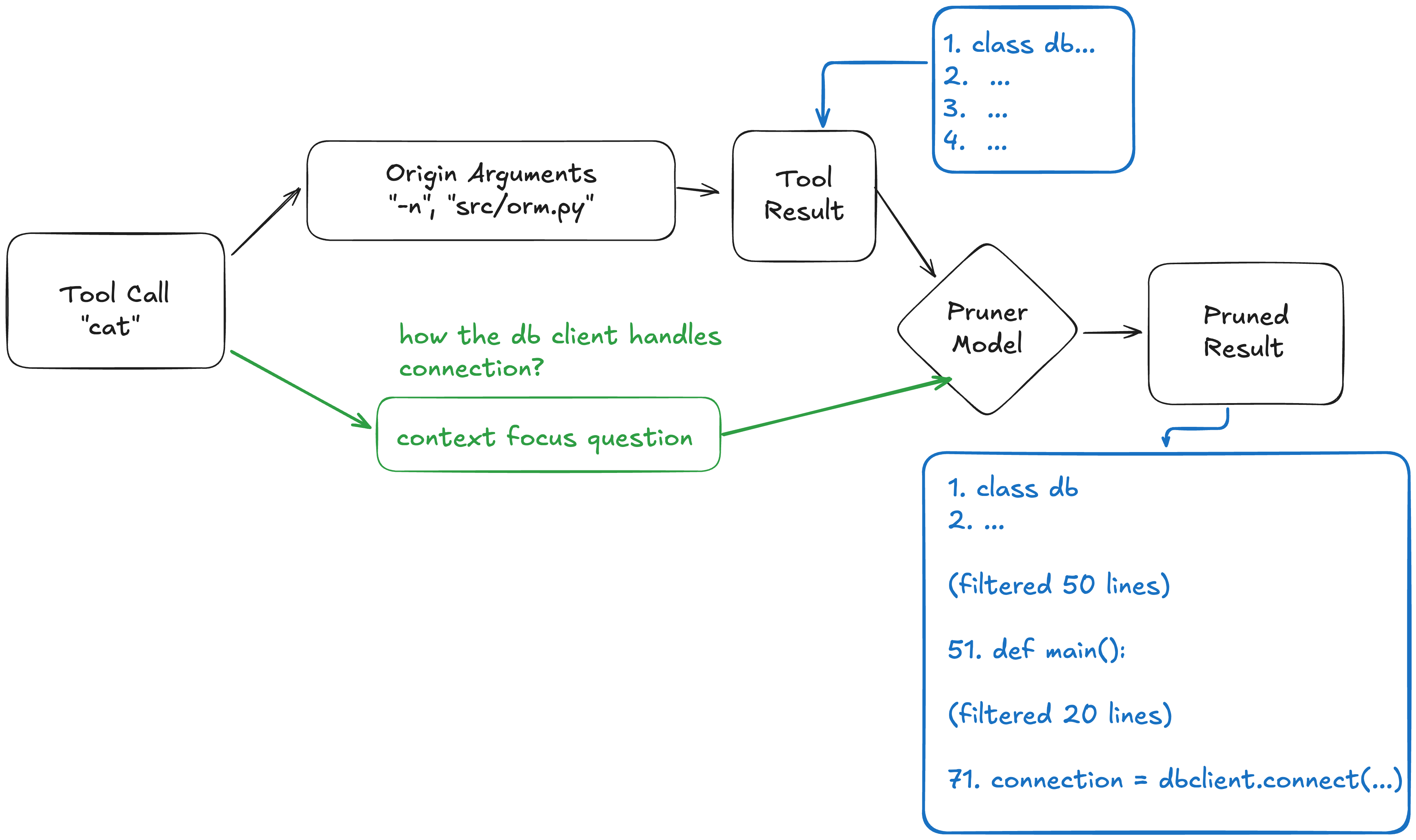
Agent模型负责根据当前运行的需要产生question, 甚至不产生question(留空则不进行裁剪),让整个系统留下了更多的灵活性和随基础模型成长的可能——在我们的实验之中,我们确实看到了顶尖的模型会评估自己当前的需求、预估命令输出的长度,从而灵活地选择简单或是复杂的 question,又或是不使用question来保证关键命令的输出完整性
这种仅对工具做包装的方法保留了最大的兼容性,我们实现了claude code sdk和openhands sdk等框架的兼容示例,可以在 https://github.com/Ayanami1314/swe-pruner/blob/public/examples/README.md 中找到
评估2:多轮任务
我们使用SWE Bench Verified和SWE-QA两个benchmark来评估这套方案的agentic能力,并在claude-sonnet-4.5和glm-4.6上做了实现,接入mini-swe-agent进行测试,结果也是比较喜人的——不仅明显地节约了token的开销,并且在正确率上能打平甚至微升(sweqa, sonnet)
我们也针对不同的方法再次进行了消融对比,即使不考虑速率的因素,我们的方法也比简单的大模型总结更加优秀——代码是一个相当难总结的形式。
真实场景案例研究:精准识别核心语句
除了基准分数之外,让我们来看几个更有趣的例子,以直观地展示我们的模型在实际应用中的性能。
模型在查看文件时,使用了 Focus on the MRO resolution logic in Inherit Docstring 作为context focus question,而SWE-Pruner在大量代码中精准定位到了高亮逻辑 —— Docstring的类定义,mro的部分代码逻辑
另一个例子来自SWE-bench的 django__django-10554 问题,Baseline 智能体和搭载了 Pruner 的智能体表现出了截然不同的行为模式:
| 配置方案 | 运行步数 | 读取操作 | 搜索操作 | 编辑操作 | Token 总消耗 |
|---|---|---|---|---|---|
| Baseline | 164 | 59 | 39 | 25 | 7,001,934 |
| Pruner | 56 | 20 | 10 | 11 | 1,170,160 |
- 传��统的 Baseline 智能体倾向于采用“广度优先”的搜索策略。它会盲目执行类似
find . -name "*.py" | grep union的命令,并不断使用sed命令在大堆文件中反复读取片段。这种方式虽然覆盖面广,但会导致大量无关紧要的代码进入上下文,最终造成上下文溢出,让智能体在冗余信息中迷失方向。 - 相比之下,搭载了 Pruner 的智能体表现得像个经验丰富的架构师。它直接定位到核心文件
django/db/models/sql/query.py,通过带行号的cat -n进行读取,并迅速锁定了关键代码分支(if self.combinator: ...),避免了 Baseline 的无效试错
站在巨人的肩膀上
该模型的开发建立在大量前期工作的基础上,我们谨此感谢所有为我们的这项工作做出贡献的人:
- Provence的理论基础: 提出了一种有效的训练Rerank-While-Prune模型的方法,即句级打标与双头损失
- Qwen团队的优秀模型:Qwen3-Reranker, Qwen3-Coder-30B-A3B-Instruct, Qwen3-Next-80B-A3B-Thinking
在这些基础之上,我们提出了若干创新
- 将Provence双头设计首次迁移到Qwen3-Reranker这样的decoder-only LLM上
- 从github代码仓库中构建部分相关查询-代码对的数据集的完整管道与数据
- 模型结构和训练方法的优化
- 实际Agentic系统的接入方法创新,提出了context focus question这一工具包装机制并实验验证
我们诚挚感谢 Provence 团队和 Qwen 团队的奠基性工作。
Conclusion
在本文中,我们分享了我们从识别生产环境中 Coding Agent 中的上下文成本问题到构建最先进的代码语义高亮模型SWE-Pruner的历程。
SWE-Pruner 填补了粗粒度文件检索与细粒度 Token 压缩之间的空白, 并为代码、多轮的场景引入了一套新式的上下文压缩解决方案,比起对Agent的轨迹进行“事后”压缩,SWE-Pruner强调在“事前”过滤掉无关的代码,从根源上降低Agent在生产环境的token开销和注意力噪声。通过引入任务感知的行级剪枝,我们不仅显著降低了 AI 编码的经济成本,还提高了智能体在复杂代码库中的推理质量。
该框架具有极强的即插即用性,可作为标准中间件集成至 OpenHands,Claude Code 等主流 Agent 框架中,也可以与任意轨迹压缩方案集成,为构建更高效、更具扩展性的 AI 软件工程师提供了新的路径
Future Works & Limitations
- 由于我们的算力有限,我们只进行了20万条数据、单语言环境下的迭代,多语言和更大规模数据量的scale或许是将来采用这项技术的团队的命题
- 在Agent方案之中,模型产出的question质量对实验效果的影响较大,在将来社区如果能对基础模型进行后训练以专门适应包装形式的工具,预计效果仍会出现显著的提升
- 生产环境的“屎山”代码仓库benchmark较为稀少,swebench等开源代码仓库还是不够“脏”,对于semantic highlight模型的发挥有一定劣势,希望在将来这个方法能被用于更冗长的代码库之中,并对这种极端情况下Agent应该如何工作做出一定参考意义
Related Links
- Qwen-Reranker-0.6B: https://huggingface.co/Qwen/Qwen3-Reranker-0.6B
- Qwen-Coder-30B-A3B-Instruct: https://huggingface.co/Qwen/Qwen3-Coder-30B-A3B-Instruct
- Qwen3-Next-80B-A3B-Thinking: https://huggingface.co/Qwen/Qwen3-Next-80B-A3B-Thinking
- Zilliz’s semantic highlight model: https://huggingface.co/blog/zilliz/zilliz-semantic-highlight-model
- Provence: https://arxiv.org/abs/2501.16214
- Swebench: https://www.swebench.com
- SweAgent: https://swe-agent.com/
- SWE-QA: https://arxiv.org/abs/2509.14635
- LLMlingua series: https://llmlingua.com/
- LongCodeZip: https://arxiv.org/abs/2510.00446
- Openhands: https://openhands.dev/
- Claude Code: https://claude.com/product/claude-code
- ModernBERT: https://huggingface.co/answerdotai/ModernBERT-base
- Selective Context: https://github.com/liyucheng09/Selective_Context